
Google、AIでファイルの種類を高速正確に判別できる「Magika」をオープンソースで公開
Googleは、AIを用いることでファイルの種類を高速かつ正確に判別できるツール「Magika」をオープンソースで公開したと発表しました。
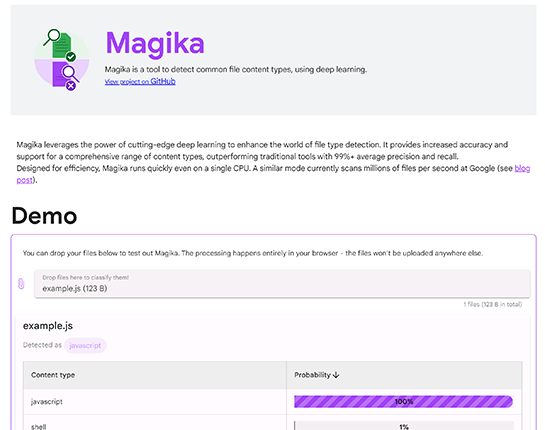
Magikaは、あるファイルの中味が何なのか、記述されたプログラミング言語の種類、動画や画像、音声などのフォーマットの種類、ExcelやWord、PDFなどのオフィス系ソフトウェアの種類、OSの実行形式バイナリなどの種類を瞬時に判別してくれます。
下記はコマンドラインとしてMagikaを実行した例で、フォルダ内のファイルの種類を出力しています。

特別に最適化された1MBのモデルでを用いて推論を実行
Magikaはファイルの判別に、Kerasを用いて特別に最適化されたディープラーニングによる、わずか1MBのモデルを用いていると説明されています。
このモデルは推論エンジンのOnnx上で実行されています。実行速度はGPUを用いずCPU上で処理されたとしても数ミリ秒程度とのこと。
GoogleはこのMagikaを100以上のファイルタイプを網羅する1Mファイルベンチマークで評価し、他の既存ツールより高い精度で判別を実行し、なおかつ他を約20%上回る高速度を実現したことも発表しています。
なぜファイルの中味を見て判別する必要があるのか?
一般にファイルの種類は拡張子によって示されますが、現実にはファイルの拡張子がつねに正しいとは限らないため、ファイルの内容を見て種類を判別する処理はさまざまなソフトウェアの内部で行われています。
例えば、コードエディタにおいてシンタックスハイライトの設定を行うためにプログラミング言語の種類を判別することや、業務アプリケーションが特定の種類のファイル以外は読み込まないような判別をすることなどが挙げられます。
特に重要とされているのはセキュリティの分野です。拡張子を偽ってユーザーにファイルを開かせようとするマルウェアに対処するために、拡張子ではなくファイルの内容から種類を適切に判断し、ファイルの種類に合わせて用意されたスキャナーによる安全性評価は欠かせません。
GoogleはMagikaをGmailやGoogle Driveなどの何百万ものファイル処理にすでに活用しており、これまで同社が利用していたルールによるファイル判別と比べて50%の精度向上を実現でき、より精度の高いスキャンが可能になったと説明しています。
あわせて読みたい
GitHub、脆弱性のあるコードを実際にデバッグして学べる「Secure Code Game」シーズン2がスタート
≪前の記事
NGINXのコア開発者がF5の経営陣に反発、NGINXをフォークし「FreeNginx」を立ち上げ。F5の経営陣がポリシーや開発者の立場を無視したと

