
カオスエンジニアリングとは、実験を通してシステムの弱みを明確にすることである。カオスエンジニアリングから継続的検証へ(後編)。JaSST'23 Tokyo基調講演
Netflixが始めた「カオスエンジニアリング」は、現在では大規模なシステムにおける可用性向上の手法のひとつとして確立し、広く知られるようになりました。
そのカオスエンジニアリングという手法を定義したのが、元Netflixカオスエンジニアリングチームのエンジニアリングマネージャーを務めていたCasey Rosenthal(ケイシー ローゼンタール)氏です。
そのローゼンタール氏が、ソフトウェアのテストに関わる国内最大のイベント「ソフトウェアテストシンポジウム 2023 東京」(JaSST'23 Tokyo)の基調講演に登壇し、「Chaos Engineering to Continuous Verification」(カオスエンジニアリングから継続的検証へ)という講演を行いました。
講演では、カオスエンジニアリングの成り立ちと、従来のテスト手法とカオスエンジニアリングの本質的な違い、そしてなぜ大規模システムにおいてカオスエンジニアリングが欠かせないのか、などが解説されました。
この記事では、その基調講演の内容をダイジェストで紹介します。記事は前編、中編、後編の3つに分かれています。いまお読みの記事は後編です。
複雑なシステムで問題を起こさない方法とは?
ここまで私は、なぜ複雑なシステムは問題なのか、そして直感的にそれに対応する方法だと思われていることは、実は間違ってるのだ、という話をしてきました。
ということで元々の問題に戻りましょう。
つまり、複雑なシステムにおいて望まない現象を起こさないためにはどうしたらいいのか、ということです。

そうするとテストが重要なのだ、ということになります。
これは「ダイナミックセーフティモデル」の図です。
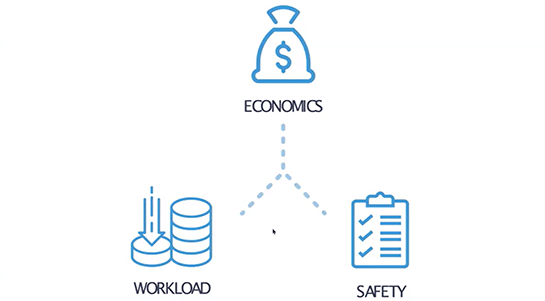
これはソフトウェアエンジニアリングとは関係なく、レジリエンスエンジニアリングの分野で40年ぐらい前から使われているモデルです。原子力発電所や海軍、陸軍、航空管制などで使われています。
非常に重要な、クリティカルなシステムにおいて、その安全性を高めるために何が寄与しているのかを示しています。
3つの柱として「エコノミクス」「ワークロード」「セイフティー」があります。
この3つの柱はゴムのようなものつながってると考えてください。いずれか1つの柱が他からすごく離れると、ゴムは切れてしまいます。
例えば、エコノミクスについて考えると、あるシステムであまりにもお金を使ってしまうと、そのシステムの持ち主である会社そのものが破産してしまいます。
ふつうの会社なら、例えばAWSの費用として1億円を使うことは出来ない、などという明示的なルールはありません。そんなことは当たり前であって、エンジニアだってそんなにお金を使ってしまったら自分がクビになることは分かります。
ワークロードについて考えると、例えばNetflixの規模のシステムをノートPCで実行することは出来ないことくらい、エンジニアなら言われなくても分かるはずです。
セイフティーについても同じです。ただ、ここには違いがあります。
それはエンジニアはシステムの安全性がいまどれだけ切迫しているのか、どれだけ崖っぷちに立たされているのかを、崖から落ちるまで気づかない場合が多い、ということです。
つまり、エンジニアはこのセイフティのゴムが切れそうになっていることに気付かない場合が多い。なぜならばシステムに問題が発生すると事前に分かれば、上司に言われなくてもそうならないように行動していたはずだからです。
カオスエンジニアリングの原則
そこで私たちが導入した新しい考え方が「Chaos Engineering」(カオスエンジニアリング)です。
公式サイトにその原則を記しました。

カオスエンジニアリングは、Chaos Monkeyなどを使ってシステム上でなるべく安全に実験を行います。その目的は、システムのセイフティのマージンがあとどのくらいあるのかを学ぶことです。
カオスエンジニアリングとは、実験を通してシステムの弱みを明確にすることである。というのは、私の大好きな定義のひとつです。
それは意図的に何かを壊すのではありません。システムの中には既にカオスがあるということを認識し、エンジニアリングを通してそのカオスをより深く理解する。そうすることで、望まない結果が起きないように安全性を担保するということなのです。
複雑性の経済的な柱
別のモデルも見てみましょう。
システムの安全性、そしてそのためのテストやバリデーションを考えるとき、必要な項目となるのが「Economic Pillars of Complexity」(複雑性の経済的な柱)です。

このモデルには「状態」(States)、「関係」(Relationships)、「環境」(Environment)、「可逆性」(Reversibility)の4つの柱があります。
この4つの柱をコントロールする、あるいは4つの柱に対して影響力を行使できるかどうかは、複雑性にどの程度対応できるのかと関連しています。
経済学での例が、世界最初の量産型自動車「T型フォード」です。

まず状態です。フォードは「T型」という単一の車種という状態に限定することで複雑さに対応しました。
当時の自動車はカスタムパーツをたくさん使っていましたが、T型フォードではパーツの種類も限定しました。
次に関係です。T型フォードは人と製造プロセスの関係を限定しました。あるチームは非常に長い製造ラインの一部分だけを担当するのです。

環境については、当時の経済環境は多くの分野でいくつかの企業の独占状態にありました。フォードは自分たちが市場に参入するときにはその独占状態を壊そうとし、その後は自分たちが独占しようとしました。
そしてアメリカの国土が自動車に有利なように、鉄道をできるだけ道路にするようにし、市場の複雑性をコントロールしようとしました。
そして最後に可逆性です。この領域でフォードはうまくできませんでした。
フォードが自動車を製造し始めると、製造ラインの人が設計段階で決定されたことを変更することはできません。一旦設計に関する意思決定がなされると、後からそれを変更するのは難しかったのです。
ソフトウェアでは状態や関係や環境をコントロールしにくい
同じモデルをソフトウェアに適用してみましょう。
状態については、ソフトウェアエンジニアの多くが、ソフトウェアの状態(ステート)についてコントロールできません。データも増え、機能も増えていくと状態も増えていきます。
また関係の限定もできません、マイクロサービスでサービス間の関係を限定することは難しいでしょう。ソフトウェアエンジニアが人と人、人とチームの関係を限定することも難しいでしょう。
また、ソフトウェアでは新しい抽象化の層がシステムに挿入されることがよくあります。システムの開発に関わっている人は、そこにはほとんど関与できません。
環境のコントロールも、ソフトウェアエンジニアはほとんどできません。アメリカではAWSのように独占状態の分野もあり、一部で環境のコントロールがある程度可能ですが、独禁法の関係もありますのでそういった優位性はいつまでも続くものではありません。
つまり、最初の3つ、状態、関係、環境についてコントロールするのは難しいわけです。しかし最後の「可逆性」の部分ではソフトウェアが輝きます。
ソフトウェアにおける優位性は「可逆性」
可逆性はソフトウェアにおける優位性です。
複雑なビジネス環境において、ソフトウェアはコードをアップデートしやすいのです。
ソフトウェア業界の開発プロセスは、ウォーターフォール型からアジャイル型へと移行しました。
ウォーターフォール型は時間をかけて設計し、開発し、お客様のところに設置をするのに1年かかる、という状況でした。
お客様がそれを使って、実は自分が欲しいものではなかったとしても、もう遅すぎるわけです。その時点では投資が大きくなりすぎて作り直すのは難しく、そのソフトウェアを使わざるを得なかったわけです。
その後にアジャイル型が入ってきました。
アジャイル型は、作り始めてから最初のデリバリーまで1週間にしようとしました。1週間後には、それほど素晴らしくはないけれども、お客様は使い始めて、問題があればその1週間後には修正できる。
時間を細分化することによって、設計の意志決定をやり直せる。可逆性を持つようになります。
コードも可逆性がありますし、インフラやデプロイにも可逆性がある方法を選べます。
何かあったときにすぐに戻すことができるようにしておくことで、複雑性といったものをうまく管理することができるようになります。
ということで、「ソフトウェアエンジニアリングとは、この可逆性のプロであることなのだ」と、例えばTシャツに書きたいぐらいです。

CIからCDへ、そしてCV(継続的検証)へ
エンタープライズソフトウェアの開発で起きているより大きな変化を見てみると、CIからCDへ、そしてさらにCVへという動きがあります。

CIというのはContinuous Integration、継続的な統合ということです。
20年前、ソースコード管理が始まり、コードでより速く機能が作り込める方法が分かってきました。
そしてコードをコラボレーションで書いていくと、さらに機能が作り込みやすい。さらにみんなのコードをまとめて、継続的にインテグレーションしていけばバグも見つけやすいことが分かりました。
それからDevOpsによる革命が起こりました。
さらにそれをデプロイしてユーザーに使ってもらうことで、より効率的になることも分かりました。
インターネットのおかげで、デリバリーパイプラインを自動化できるようになったのです。
こうしたCI/CDの進化によってソフトウェア開発の可逆性は高まり、これをビジネスに取り入れた人たちは、より成功に近づくことができるようになりました。
ビジネスもよりアジャイルに動くことができるようになり、競合優位性を持てるようになるからです。
CVはさまざまな実験をすること
そして今は、より速く機能をデリバリするだけではなく、それを壊さずに、ビジネスのニーズをきちんと満たすことが出来ることも実現しなければならない時代に入ってきました。
さまざまな場所で非同期的に開発が行われていたとしても、全体としてお客様のニーズを満たす方向へ向かっているかどうかを継続的に確認できることが大事になってきたのです。
そのためにQA(Quality Assurance)やソフトウェアテストやカオスエンジニアリングによるテストなどを用いながら、システムの振る舞いが望んだとおりなのかどうかを確認していかなくてはなりません。
米国ではこのコンテキストをCV(Continuous Verification)、継続的検証という文言で呼びはじめています。
このCVというのは、システムの振る舞いを予測するために前もってさまざまな実験をする、ということになります。

図の一番上のラインのところは、システムが非常に複雑な場合です。よりプロアクティブに実験をして、システムの振る舞いを見ていかなければなりません。
下には現在あるいは過去のベストプラクティスが並んでいます。これらが悪いという意味ではありませんし、やるべきではないわけでもありません。ただ、現在の複雑なシステムには対応できてないということです。
現在、可用性への対応は事故が起きてからそれを分析することで、事後的に行われています。
一方で、カオスエンジニアリングはシステムで何かが起こる前に対応をとります。
単体テストや機能テスト、結合テストなどのテスト自体はいいことですが十分ではありません。テストでは、システムについて分かっている特性について確認しているだけです。
一方で、実験は新しい知識を生み出すのです。
複雑なシステムでもっと重要なのは、システムシステムはやりたかったことをしてくれるのかということです。予想通りに機能しなかったとしても、欲しいアウトプットが得られているかどうかが、企業としては気になるわけです。
たとえ本来こうあるべきだという機能をしていなかったとしても、システムに期待する成果が得られていればいいわけです。
ビジネスとしてはコンポーネントではなく全体を見ていきたいわけです。
これが今日の全てのテーマなんですが、複雑性と戦うのではなく、それをナビゲーションするということが必要なのです。

質問があればお答えしたいと思いますし、遠慮なく連絡してください。私はこのトピックについての話をするのが大好きですので。
ありがとうございました。
参加者との質疑応答
Q) 気をつけていても人間はミスをすることがある、問題は直接ミスを起こした人ではなく、仕組みなどにある、という理解で合っていますでしょうか?
A) そうです。根本原因というのは、その現象を説明する方法のひとつでしかなくて、それはあまり役に立たないということです。ですから、どこのコードが間違ってたか、ではなくてシステム全体を見ることが大事だということです。
Q) CVはCIに含まれるのでしょうか?
A) いえ、CVはCIやCDとは非同期で実行されるのが一番うまく機能します。
例えばエンジニアがアプリケーションの挙動を変えるときにCI/CDパイプラインが実行されると思います。
しかしながら全く違う部門が別のタイミングでネットワークやファイアウォールを変える可能性があります。アプリケーションエンジニアはそれを知らない場合があります。そうするとシステムの挙動が変わります。
自動化テストとCI/CDではそれを捉えられません。ですからアプリケーションのデプロイのタイミングに頼るのではなく、CVはなるべくたくさんに頻繁に走らせたいわけです。
Q) 複雑性をどうしようというふうに突き詰めていくと、多くが深い対策しか思いつかないので、そもそも不具合を出さないシンプルなソリューションを求めるべきではないかと考えていますが、いかがでしょうか?
A) そうしたいと思うのは分かりますが、それは不可能です。複雑性というのはもちろんいいことではありません。しかしながら、複雑性が好きだから複雑性を作るのではなくて、ある作業を達成するために複雑性が必要なんだということなんです。
例えばNetflixではシンプル化に関する専門家を雇って、そしてシンプル化と同時に信頼性も上げることを試しましたが、最終的にはうまくいきませんでした。
ですからシンプルにしようとしていた会社はあったのですが、失敗しているのです。
Q) 複雑性というのは、ソフトウェアだけではなくてハードウェアにも生じる問題でもあると思うのですが、ハードウェアのメカニックとかロボティクスなど、ソフトウェア以外の業界がカオスエンジニアリングを使うということはありうるんでしょうか?
A) はい、もちろんできます。
例えば病院では、私達は人の命を扱うから人の命で実験はできないよと言われたわけです。
しかしながらカオスエンジニアリングを定義するとき、私はその定義を実は医療科学の部分から取ってきたのです。二重盲検試験という方法があります。
医療の分野では、ある治療が本当に効果があるかどうを調べるのに二重盲検をやっていて、つまりこれはカオスエンジニアリングですよと、名前が違うだけで同じことやってるんですよと説明しました。
すると病院の人たちは、なるほど私達もやってるねと、それを安全にやれるかどうかを考えればいいんだね、と分かってくれました。
―――― ありがとうございました。
あわせて読みたい
AWS上で開発環境一式、コードリポジトリからテンプレートコード、IDE、CI/CDパイプラインまでを丸ごと提供する「Amazon CodeCatalyst」が正式サービスに
≪前の記事
JavaでKubernetesを拡張できる「Java Operator SDK」が、Operator Frameworkの正式なサブプロジェクトに

