
「英語は新しいプログラミング言語であり、生成的AIは新しいコンパイラだ」。英語対応のためのSDK「English SDK for Apache Spark」をデータブリックスが発表
Apache Sparkなどの開発で知られるデータブリックス社は、同社が主催したイベント「DATA+AI Summit 2023 by Databricks」で、英語をApache Sparkの問い合わせ言語にできるSDK「English SDK for Apache Spark」を発表しました。
英語は新しいプログラミング言語である
Databricks共同創業者兼チーフアーキテクト Reynold Xin氏。
英語は新しいプログラミング言語であり、生成的AIは新しいコンパイラであり、Pythonは新しいバイトコードだ。

これが何を意味するのか。多くの方々がChatGPTを使ってSparkの問い合わせコードを生成したことがあるだろう。
しかしChatGPTはさまざまな言語能力を備えているが故に、大量のアンチパターンなども生成してしまう。
これを改善するには多くのプロンプトエンジニアリングが求められる。そこで、そうした作業を不要にする「English SDK for Apache Spark」を発表する。

Sparkのエキスパートによってプロンプトエンジニアリングが実行され、アンチパターンが最小化されている。
デモを見ていただこう。
英語の指示でデータの集計からグラフ化まで
Sparkでのデータ分析のために、Apache Sparkへのコミュニティからの貢献数をGitHubのプルリクエストデータから取得する。
GitHubのAPIからPythonのコードでデータを取得し、AparkのDataframeとする。
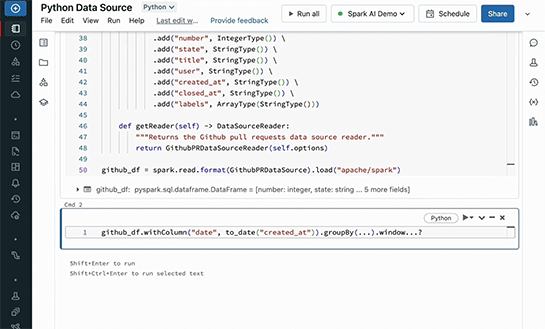
このデータを基に、1日ごとのプルリクエスト数と7日間の移動平均などを求めるために、AggrigationやWindows関数などを使おう。
ただ、詳しい使い方まで覚えていないので公式ドキュメントやStack Overflowなどを検索することになる。
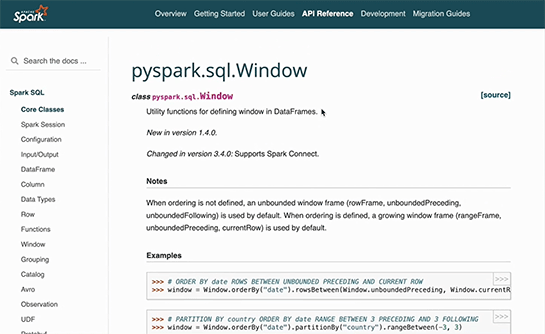
やりたいことは言葉(英語)で言えるのに、それをコードとして記述するのは時間がかかるのだ。
言葉がそのまま実行できればいいのに。そこで「English SDK for Apache Spark」だ。
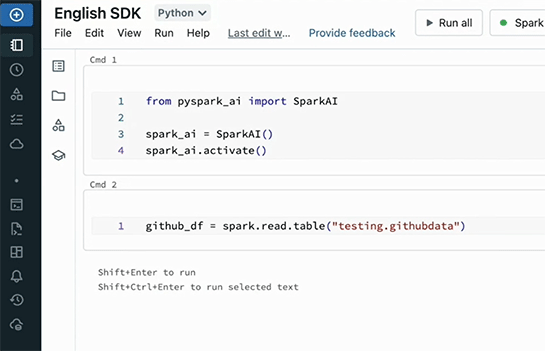
使い方は簡単。まず、Spark_aiクラスを初期化、有効化。これですべてのDataframeがAIのパワーを得られる。
あとは英語での指示を書き込む。「Add a column 'date' derived from 'created_ai'」(Dateカラムを追加)、「Add a column 'num_pr_created' that aggregates the number of created PRs by date.」(日次でプルリクエスト数を合計)、「Add column '7_day_avg' that computes the 7 day moving average of the number of PRs created.」(そして7日間移動平均を追加)。
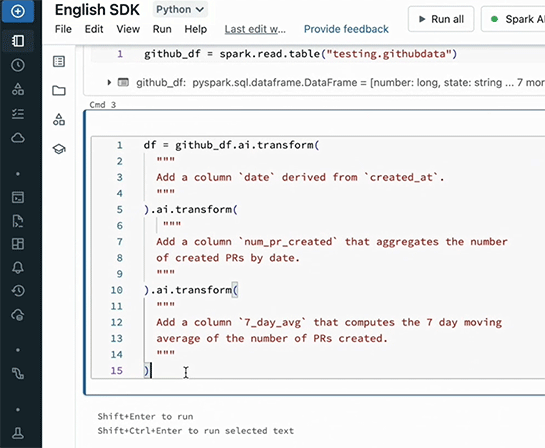
これで結果が得られた。
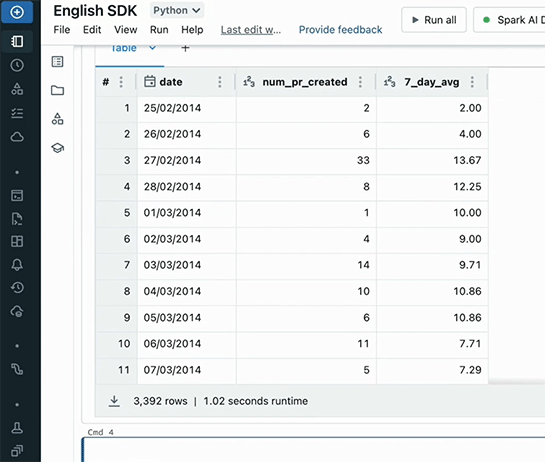
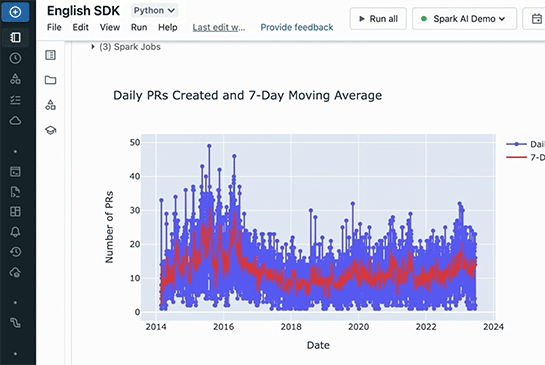
これをグラフ化。
このデータに、Sparkのメジャーバージョンアップの時期を重ねるため、バージョン番号が「x.0.0」で示されるメジャーリリースの日付のデータを英語で指示して取得。
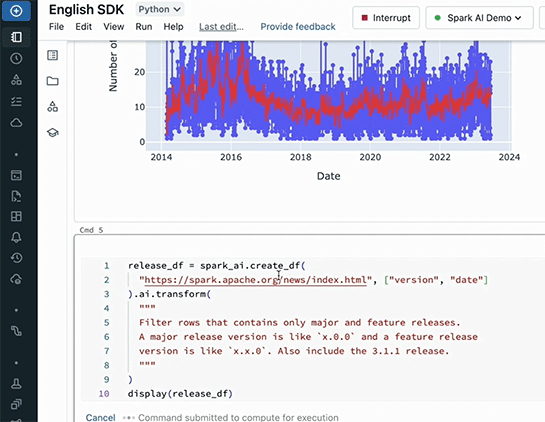
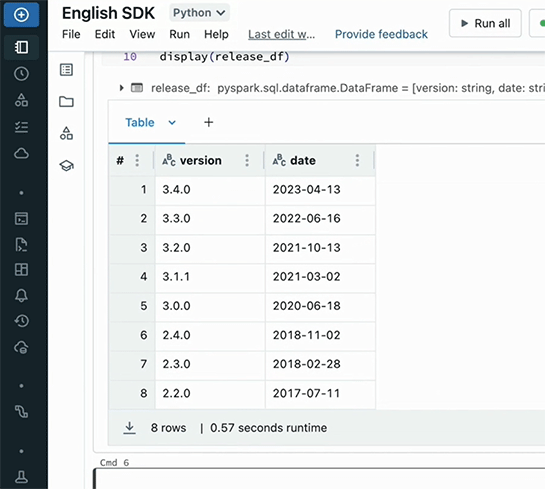
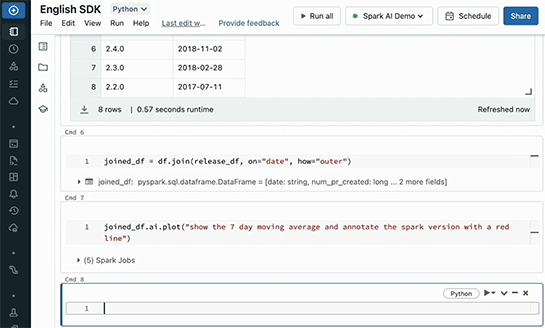
2つのグラフを重ねるために「show the 7 day moving average and annotate the spark version with a red line」(7日移動平均と、バージョン毎の赤線を引く)という指示を出す。
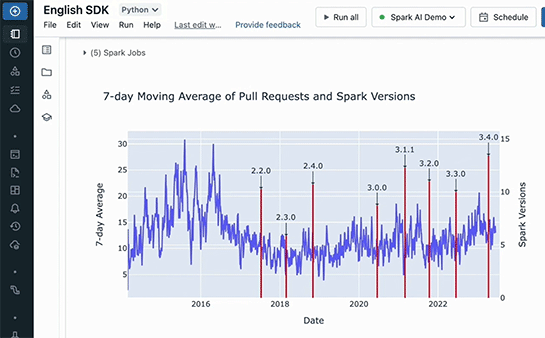
すると、目的のグラフが表示された。
あわせて読みたい
Vue.jsのフルスタックフレームワーク「Nuxt 3.6」リリース。性能向上、完全に静的なサーバコンポーネントなど新機能
≪前の記事
Amazon Aurora MySQLとAmazon Redshiftをニアリアルタイムに同期する「Amazon Aurora MySQL zero-ETL integration with Amazon Redshift」パブリックプレビュー

