
MySQLの運用をコードで定義し大幅に自動化する「MySQL Operator for Kubernetes」がオープンソースで公開[PR]
Kubernetesのようなコンテナ環境では、MySQLデータベースのようなステートフルで高い安定性が求められるソフトウェアを運用することは難しいと、以前は考えられていました。
しかし現在ではステートフルセットのような機能もKubernetesは搭載し、実装も安定してきていることから、ステートフルなアプリケーションをKubernetesで実行できる状況が十分に揃ってきました。
それだけではありません。Kubernetesには運用自動化を支える「Operator」と呼ばれる拡張機能が登場しました。これを用いると、Kubernetes上でさまざまなアプリケーションでの運用作業の多くが人手を介することなく自動的に行えるようになります。
そしてこのOperatorを用いてKubernetes環境下のMySQLの運用を大幅に自動化してくれる「MySQL Operator for Kubernetes」が、オラクルからオープンソースで公開されました。すでに正式版に到達しており、実際に本番環境で使えます。
Kubernetesの進化は、ステートフルなアプリケーションの代表ともいえるMySQLの優れた運用基盤になる可能性を見せるところまで前進してきたといえるのです。

この「MySQL Operator for Kubernetes」を用いることで主に2つの利点を得ることができます。1つは前述のように障害対応やバックアップ、アップデートなど運用作業の自動化支援。そしてもう1つは、これらの運用をコードの記述によって定義できるようになる、すなわち運用のコード化です。
それぞれについて詳しく見ていきましょう。
MySQLをクラスタ構成でスケーラブルに
MySQLにはKubernetesのような分散環境に対応し、スケーラビリティと可用性を実現する「MySQL InnoDB Cluster」があります。MySQL Operator for Kubernetesは、Kubernetesの分散環境においてこのMySQL InnoDB Clusterと組み合わせて利用することが想定されています。
まずMySQL InnoDB Clusterの概要を確認しておきましょう。
MySQL InnoDB Clusterは複数のMySQLサーバによるクラスタ構成となります。クラスタ内には「プライマリ」となるMySQLサーバが必ず1つ存在し、それ以外のMySQLサーバはすべて「セカンダリ」となります。
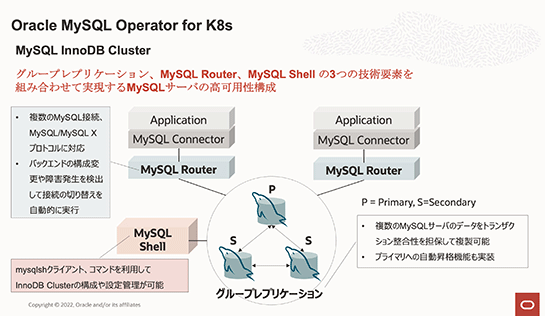
データの追加変更削除はプライマリのデータベースで行われ、その内容はレプリケーションによってすべてのセカンダリのデータベースに即時に反映されます。このセカンダリの台数の増減により大量のリードアクセスに対してスケーラブルな能力を備えたクラスタが実現することになるのです。
万が一プライマリが何らかの原因で稼働しなくなった場合、セカンダリの中の1つが自動的にプライマリに昇格することで、高可用性も実現されています。また、クエリをクラスタ内のサーバに振り分けるルータも冗長化できますし、ネットワーク障害によるいわゆるスプリットブレインなどの状態に陥った場合でも整合性を保てる機能などが搭載されています。
フェイルオーバー、定期バックアップ、アップグレードなど自動化
このMySQL InnoDB Clusterに対してMySQL Operator for Kubernetesを用いることで、さまざまな自動化が実現します。
例えば、クラスタを構成するMySQLサーバが何らかの障害で停止した場合、そのサーバを含むPodが自動的に再起動されてクラスタに復帰するようになっています。
クラスタを構成するMySQLサーバやルータの増減も設定ファイルを変更すると、それに合わせてMySQL Operator for Kubernetesが自動的に実行してくれます。
定期的なバックアップやスナップショットの取得も、あらかじめ定義を記述することで人手を介することなく自動的に実行されます。
MySQLの新バージョンが登場した場合も、設定ファイルにバージョン番号を記述するだけでコンテナレジストリから指定したバージョンのコンテナイメージを取得し、自動的にアップグレード作業が実行されます。
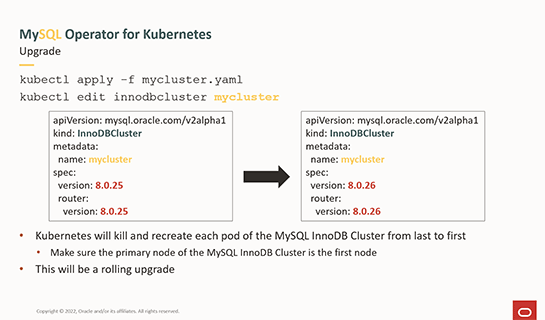 設定用のYAMLファイルにバージョンを指定すると、自動的にそのバージョンへとアップグレードが実行される
設定用のYAMLファイルにバージョンを指定すると、自動的にそのバージョンへとアップグレードが実行されるこうした自動化によって、手作業で運用を行う場合に発生する可能性のあるミスが削減でき、より確実で迅速な運用が実現できるでしょう。

クラウドネイティブな運用体験:コードで運用を定義し実行する
もう1つ大事な特徴は、これらMySQL Operator for Kubernetesに関する運用の自動化はすべて、設定ファイルへの記述で定義できる点です。
クラスタを構成するMySQLサーバやルータの数をいくつにするのか、バックアップをどのようなスケジュールでどのストレージにとるのか、どのバージョンにアップグレードするのかといった運用作業の定義は、すべて設定ファイルに記述します。すると、その記述ファイルを元にMySQL Operator for Kubernetesが実行してくれるのです。
設定ファイルを履歴管理すれば、いつ、誰が、どのように設定し実行したかが明確になります。また、状態を変更してなにか問題が発生した場合、ある時点での状態に戻すことも容易になるでしょう。
クラウドの登場によってインフラの定義をコードで行う「Infrastructure as Code」と呼ばれる技術が登場し、従来のインフラエンジニアの仕事を大きく変えました。
そしてMySQL Operator for Kubernetesの登場は、運用のレイヤにもそのクラウドネイティブな体験をもたらそうとしているのです。
≫MySQL Operator for Kubernetes - GitHub

(本記事は日本オラクル提供のタイアップ記事です)
あわせて読みたい
GitLabがVisual Studio CodeベースのWebIDEへ移行すると発表
≪前の記事
コンテナをサーバレスで実行する「Azure Container Apps」が正式サービスとして提供開始

