
ついに登場した不揮発性メインメモリ。対応アプリ開発に欠かせない性能チューニングツールがインテルから[PR]
これまでのコンピュータの常識では、電源を切ったらメインメモリ上のデータは消えてしまいます。そのため、不意の停電などで消えてしまっては困る重要なデータは、必ずストレージに保存しなければなりませんでした。
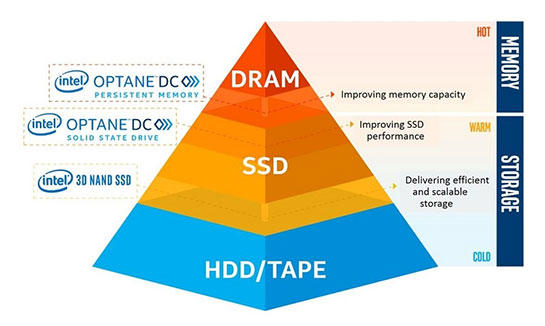
この常識をくつがえし、電源を切ってもデータが消えない不揮発性のメインメモリを実現するのが、昨年から本格出荷が始まった「Intel Optane DC Persistent Memory」です。
Optane DC Persistent MemoryはDRAMと同様にDDR4スロットに挿して利用し、最大3TBまで追加できます。
そしてメインメモリの一部としてCPUから高速にデータを読み書きできるだけでなく、APIを通じてストレージのように読み書きすることも可能です。
インテルはこのOptane DC Persistent Memoryを、DRAMとSSDのあいだの新しいメモリレイヤーとして位置付けています。
前述の通り、Optane DC Persistent Memoryは、すでに最新のサーバ向けXeonプロセッサに対応した製品の本格出荷が始まっています。インテルはサーバだけでなくワークステーションでのOptane DC Persistent Memorサポートも明言しており、その環境はおそらく今年後半から来年には整ってくると予想されます。
不揮発性メインメモリの活用にはチューニングが欠かせない
Optane DC Persistent Memoryは不揮発性メモリであるために、ここにデータを配置すると、データを失わないためにストレージに保存するという動作を省略できます。
例えばデータベースでOptane DC Persistent Memoryを活用すれば、データやログをいちいちストレージに書き込まなくてよくなるので実行速度が飛躍的に向上するでしょう。
ただし、本当にソフトウェアをOptane DC Persistent Memoryに最適化するには、十分なチューニングが求められます。
というのも、最新のCPUではマルチコア化が進んでいるからです。
たくさんのコアを効率よく並列動作させて高速な実行速度を引き出すためには、DRAMであってもOptane DC Persistent Memoryであっても、メモリとCPUのあいだで効率的なデータ転送が求められます。
そのためには、メモリからCPUへのデータ転送に関するボトルネックを徹底的に排除し、できるだけ多数のコアが並列に処理を進められるように、メモリ上におけるデータの構造や配置、読み込みや書き込みの順番などのチューニングか欠かせません。
特にOptane DC Persistent MemoryはDRAMよりもアクセス速度が遅いため、そのままではアプリケーションの性能を落とす可能性すらあります。活用にはより深いチューニングが必要なのです。
そして、そのチューニングを十分に行うには、実際にコードを実行し、プロセッサや内部のコア、L1/L2/L3キャッシュ、DRAMのメモリ、Optane DC Persystent Memoyによるメモリなどの状態を逐一解析していく必要があります。
そのためには解析ツールが不可欠であり、インテルが純正の解析ツールを提供しています。
おもにパフォーマンスの問題となる原因を素早く特定してくれる「VTune Profiler 2020」と、おもにマルチスレッド化のアドバイスを教えてくれる「Advisor 2020」です。日本ではいずれもエクセルソフトが日本語版を販売し、技術サポートなども提供しています。
それぞれを紹介しましょう。
VTune Profiler:ホットスポットを発見、並列性や実行効率を詳細に把握
VTune ProfilerとAdvisorは、どちらもVisual Studioのアドオンとして使うことができます。
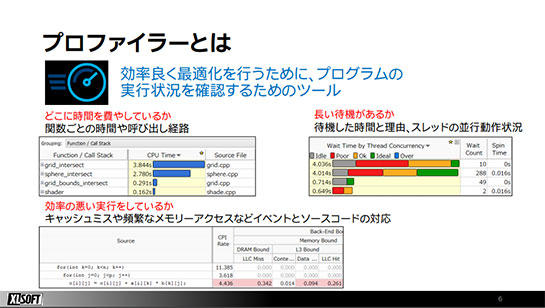
VTune Profilerは名プログラムの実行におけるCPUのコアやキャッシュの使われ方、メモリの使われ方などの状況を詳しく解析し、どこが性能のボトルネックになっているのかを簡単かつ効率よく把握できるツールです。
C/C++、Fortran、.NET、Java、Python、Goなどのプログラミング言語に対応し、またLinuxではコンテナにも対応しています。
VTune Profilerでは、おもに「ホットスポットの発見」「スレッド並列の効率の評価」「コア内部の実行効率の評価」などの解析が可能です。
ホットスポットとは、実行したプログラムのなかでもっともCPU時間を使用している部分のことです。プログラムの動作速度を改善するにはいちばん時間がかかっているところを改善するのが効果的であり、ホットスポットの発見は、その効果的な部分を見極めるために使われます。
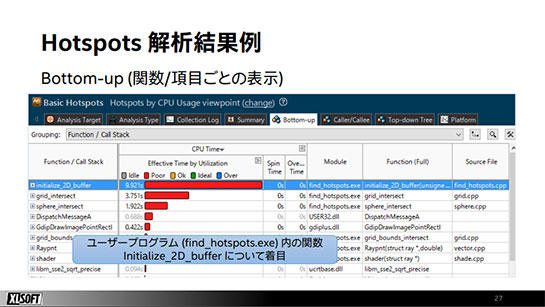
VTune Profilerによってプログラムの実行が解析されると、このホットスポットが示されてプログラムのどの部分でCPU時間が多く使われていたか、関数や項目ごとに見ることができます。さらに、ソースコードレベルにまで掘り下げていくことができます。
スレッド並列の効率の評価では、スレッドがどれだけ効率よく並列に動作できているかを示してくれます。特に、メモリを共有して並列実行するプログラムを実現するためのコンパイラの指示文やライブラリなどを規格化した、OpenMPを利用して性能を改善するための有益な情報を表示してくれます。

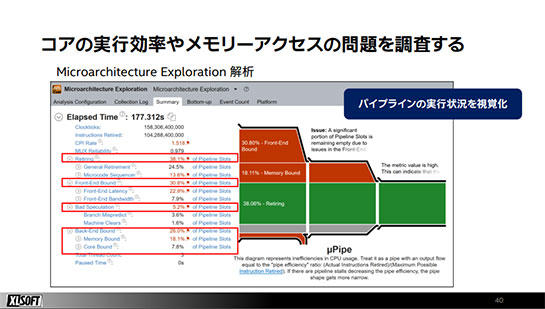
コア内部の実行効率の評価では、CPUのコア内部のマイクロアーキテクチャーによって効率的にプログラムが実行出来ているかを評価します。
コア内部では、メモリから命令を取り出す「フェッチ」、取り込んだ命令をマイクロオペレーションに変更する「デコード」、デコードしたマイクロオペレーションを実行する「実行」、そして実行結果に応じてメモリをアップデートする「リタイア」の4つのパイプラインによって処理が行われています。
すべてのコアでこのパイプラインがスムーズに流れていれば、非常に高い実行効率として評価されます。しかし、分岐予測ミスによる命令のフラッシュ、浮動小数点数の除算など実行コストの大きな命令の実行、そしてメモリーアクセスにおけるキャッシュミスを起こすことなどで、実行効率が下がっていきます。
VTune Profilerによってパイプラインの実行効率を視覚化し、どこがボトルネックになっているのかを把握。改善のためのヒントを得ることができます。
Advisor:コードのベクトル化やメモリアクセスパターンをアドバイス
Advisorはコードのベクトル化、すなわち一度に複数のデータを処理できるベクトル命令を活用できるようにコードを最適化することや、CPUが最適なパターンでメモリへアクセスできるようにコードを改善することなどを、アドバイスによって支援してくれるツールです。
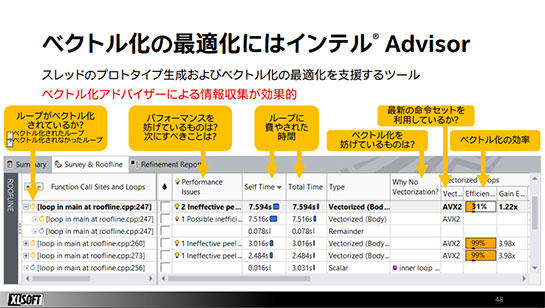
Advisorはまず、ハードウェアの限界までプログラムを実行。そもそもハードウェアが備えている性能に対して、例えば実行したプログラムではDRAMからCPUへのデータ転送で十分にその性能を発揮できていない、といったことを視覚化して教えてくれるほか、ベクトル化やスレッド化などの具体的なアドバイスもしてくれます。
ソフトウェアによって多様なハードウェアを使いこなしていく時代に
ハードウェアの進化に任せておけばプログラムの実行速度は何もしなくても毎年のように向上していく、というプログラマにとって幸せな時代は残念ながら数年前に終わりを告げています。
これからのハードウェアの性能向上は、コア数の増加やGPU、FPGA、AI専用チップ、不揮発性メモリといった多様化によって実現されていきます。そしてこれからのコンピュータ性能の向上とは、この多様化するハードウェアをソフトウェアによって活用し、それぞれに最適化していくことで実現されていくものとなるでしょう。
そのために、VTune ProfilerやAdvisorといったツールを使いこなす必要性も高まっていくことになるのではないでしょうか。
≫インテル VTune プロファイラー 2020
≫インテル Advisor 2020
上記2つを含むコード最適化と高速化のための統合スイート製品
≫インテル Parallel Studio XE 2020
(本記事はエクセルソフト提供のタイアップ記事です)
あわせて読みたい
Microsoft TeamsやVirtual Desktopなどクラウドサービスの利用率が急上昇中、最大775パーセント増加。クラウド増強を加速
≪前の記事
Kubernetes 1.18リリース。NUMAサーバでの最適化、ポッドのデバッグの容易化など

