
Kubernetesを利用したクラウドネイティブな開発と運用とは何か? これまでと何が違うのか? サイバーエージェント青山氏が語る(前編) July Tech Festa 2019
Kubernetesを利用したクラウドネイティブな開発や運用は、これまでとどう違うのでしょうか、あるいはどのくらい進化したものなのでしょうか。
2019年12月8日に産業技術大学院大学で行われたイベント「July Tech Festa 2019」で、サイバーエージェントの青山真也氏が行ったセッション『「Kubernetes による Cloud Native な開発」と「VM 時代の開発」』で、VMを用いた従来の方法と比較しつつ、Kubernetesを前提としたクラウドネイティブのやり方が分かりやすく紹介されています。
その内容をダイジェストで紹介しましょう。本記事は前編と後編に分かれています。いまお読みの記事は前編です。
「KubernetesによるCloud Nativeな開発」と「VM 時代の開発」
サイバーエージェントでインフラエンジニアをしております青山と申します。

普段は、プライベートクラウド上でのマネージドKubernetesのプラットフォームを開発するプロダクトオーナーをしています。
また、パラレルキャリアとしてクリエーションラインの技術アドバイザーやさくらインターネットの客員研究員などもしております。
とにかくKubernetesの好きな人、と覚えてくれたらと思います。
今日は、KubernetesによるCloud Nativeの開発と、従来のVMを使った開発がどのくらい違うのか、比較しながらお話をしていきたいと思います。
Cloud Nativeとは?
Cloud Nativeな開発にはいろんな手段があると思いますが、今回はKubernetesを前提としてお話しします。
一方で、VMを使っていたらクラウドネイティブではないのかというとそうではなくて、VMを使っていてもクラウドネイティブな開発はできると考えています。
VMを使う開発でもいろいろなやり方があると思いますが、今回はあくまでも、少し前のVM時代のよくある開発と、いま新しくいわれているようなKubernetesを使った開発とを比較していきたいと思います。
さて、冒頭でもCloud Nativeというワードを使いましたが、Cloud Nativeは、Cloud Native Computing Foundationという団体が言語化した定義を発表しています。
これを要約すると、疎結合システムで、復元力があるとか、管理しやすいとか、そういう特性を持ったシステムをオープンなテクノロジーを使ってスケーラブルに実現すること、また、それをできるように組織に力を与えることを、Cloud Nativeだといっています。
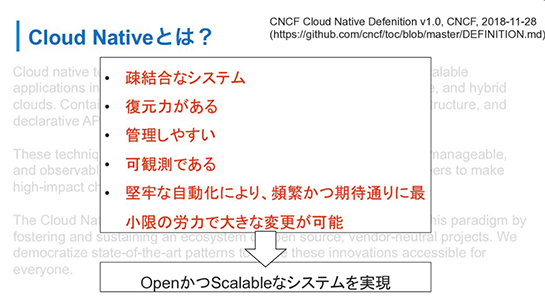
これを頭の片隅に置いていただいて、こういう特性を得るためにコンテナやKubernetesなどを技術要素のひとつとして使っているのだ、というのが、今日の話の主軸になります。
VMとコンテナはライフサイクルが違う
早速ですが、VMとコンテナはなにが違うのでしょうか。
ひとつ違うのは、隔離性がVMとコンテナでは大きく異なっています。
VMではVMごとにOSの領域が用意されるので、基本的には隔離性が高い状態になっています。
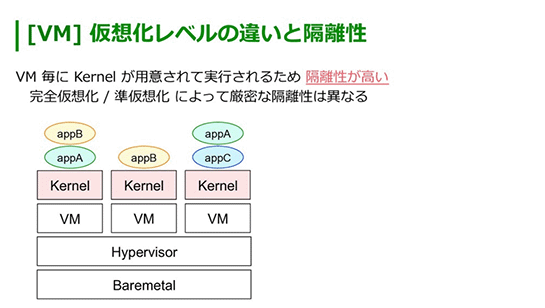
コンテナの場合、一般的に使われているruncと呼ばれるコンテナランタイムではカーネルを共有する形でコンテナの隔離領域を作ることになっています。
例えばこの図ではAとBのコンテナはカーネル自体は共有するのでVMと比べると隔離性は低い。そのかわりコンテナは高速な起動や低オーバーヘッドなどの利点があります。

最近ではgVisorやKata Containerなど、隔離性の高いコンテナランタイムも開発されてきています。
こうしたVMとコンテナの違いは、ライフサイクルが異なることにもなります。
あくまで個人の見解ですが、VMは数カ月や数年の単位で動かし続けることも多いと思います。900日くらいのアップタイムはみなさんも見たことがあるのではないでしょうか?
一方、コンテナは短いスパンでどんどん作って、消していきます。
VMの場合、なんらかの都合で「このVMは止めないようにしたい」といった要望がよく来たりします。
ただ、コンテナの場合はこの、特定のコンテナを止めない、といったことは極力、極力NGにしてください。
なぜかというと、DockerやKubernetesはコンテナを気軽に止められることで、アプリケーションがすぐに復旧するとか、アップデートしやすい、といったメリットを得られるからです。
こうした特性を殺さないために、Cloud Nativeで最初に考えなければいけないのが、コンテナをいつでも停止できるようにすることを心がけて作るということです。
インフラのコード化がCloud Nativeでどう変わるか
話は少し変わり、大規模なインフラではインフラをコードで管理しなくてはならなくなります。数千台、数万台のサーバを手動で管理するのはちょっと現実的ではないですよね。
インフラのコード化の歴史というかパターンを見ていくと、VMではTerraformでVMプロビジョニングして、ChefやAnsibleでOSやミドルウェアを設定して、Jenkinsでアプリケーションをデプロイしてサービスが提供できるような状態に持っていく、というのがよくあるパターンかと思います。
この場合、すべてを自動化していたとしても、VMの起動からアプリをデプロイするまで数十分。
もうちょっと進んでくると、事前にPackerを使ってNginxなどがあらかじめ入ったVMイメージを作って、あとはアプリをデプロイすればいいだけ、とすると、VMの起動時間は5分くらいになるかもしれません。
結局、VM時代のインフラのコード化は時間がかかったり複数のツールを使うことでハードルが高かったりします。

これがCloud Nativeでどう変わるか。
DockerやKubernetesでは、基本的にDockerfileを使ってイメージをビルドし、そのイメージを指定したKubernetesのManifestを書くと、アプリケーションが簡単にデリバリできるようになっています。
イメージのビルド時間も最短で1分くらい。デプロイも、数秒から1分くらいでできます。

Dockerfileいうのは、どういうコンテナイメージにするのか、CentOSやNginxなどと書いておいて、docker buildコマンドでビルドすると簡単にそれらをコンテナイメージにできます。
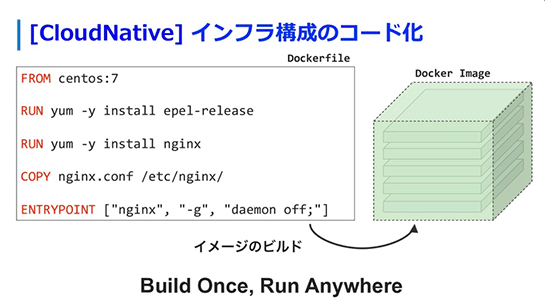
イメージを作った後は、どういう状態でデプロイするかを定義したKubernetes Manifestファイルに、デプロイするコンテナイメージとレプリカ数を書いておくと、インスタンスをその数に維持し続けてくれます。
コンテナイメージにはアプリケーションも埋め込むことができます。

つまり、KubernetesのManifestファイルでデプロイすることは、アプリを新しくデプロイすることと同じになります。
コンテナは高速でスケールアウトできる
これでなにがいいかというと、スケールアウトするときに同じ環境を高速にデプロイ可能になるということです。
VMの場合、起動時間が1分から3分とか。アプリケーションも含めた完全なイメージにしておいてもそれくらいかかります。
コンテナの場合、起動時間は1秒とか5秒とかの単位なので、スケールが非常に速く、すぐにリクエストを返せる。

さらに、VM時代にはわりとモノリシックなアプリケーションの書き方をすることが多かったと思いますが、コンテナやKubernetesを使うと、マイクロサービスや、マイクロサービスまではいかなくてもロールごとに機能を分けて作られていることが多いので、特定の機能だけを高速に起動してスケールさせることもできます。
CI/CDはCloud Nativeでどう変わるか
こうしてインフラは変化してきましたが、同時にアプリケーション開発者の意識も変えなくてはいけません。
インフラとアプリケーションの境界線は、私はCI/CDだと思っていますが、これがCloud Nativeでどう変わるでしょうか。
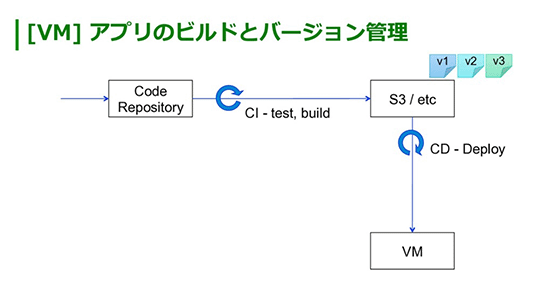
従来のVMでは、コードのリポジトリに対して新たにコードがマージされるとCIが走って、バイナリが生成され、それをS3なりどこかに置いて、それを何らかのデプロイツールでVMにデプロイし、アプリを更新することが多かったかと思います。
このとき、S3などファイルの置き場所にファイル名やディレクトリを切ってバージョン番号などの名前を付けるかなと。
これがKubernetesではどう変わるか。いろんな方法がありますが、一般的に使われている方法として「GitOps」という手法があります。
コードをマージしたらテスト、ビルドが走って、合わせてコンテナのイメージもビルドして、それをDockerレジストリに登録しておきます。
これをKubernetesのManifestファイルでデプロイしますが、Dockerレジストリに登録したどのイメージをデプロイするのかをManifestで定義できるようになっています。
なので、どのイメージをデプロイするかを書いたManifestファイルをManifestのリポジトリに登録し、コミットすることでKubernetesにManifestファイルをデプロイします。
するとManifestファイルに従ってKubernetesが指定されたイメージをデプロイしてくれます。
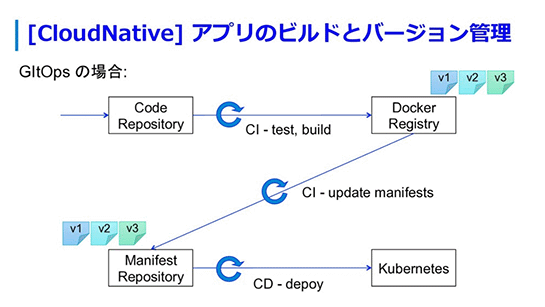
こうすることで、Manifestファイルのリポジトリにはインフラの構成ファイルが保存されていくことになります。そこを見れば現在のクラスタの状態が分かる、という仕組みになります。
万が一、Kubernetesクラスタが壊れても、そこのManifestファイルを再び適用することで復旧できます。
では、このようなCI/CDを契機にして、インフラやアプリケーションがどのように更新されるのか、次に紹介しましょう。
Kubernetesにローリングアップデートを任せる
アプリケーションをアップデートする一般的な方法に「ローリングアップデート」があります。
VM時代の手法だと、ロードバランサーの配下にVMが複数あって、手動やスクリプトを使って特定のVMをロードバランサーから外して、アプリケーションを停止して新しいアプリケーションをデプロイし、起動する、とったことをやる必要があります。
このとき、止めようとしているアプリケーションにリクエストが来てないか確認してから停止させるとか、意外と気を使いながら作業します。
うちの会社でも、私が入社したころはまだこういう作業がわりとありました。
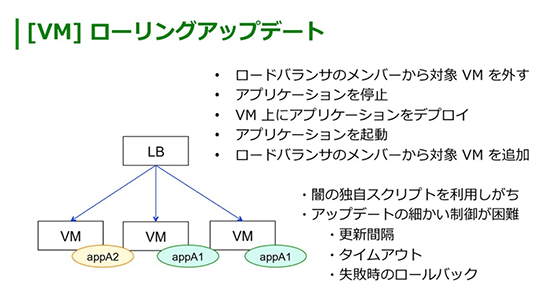
この作業のなにがつらいかというと、 独自のスクリプトを作りがちで、それは誰がメンテしていくんだと。
しかもそのスクリプトは特定のユースケースのために作られたので、更新間隔を変えたいとか、タイムアウトの時にどんな処理をするんだとか、ロールバックをどうするといったことは、だいたいうまくいかないと。
これがKubernetesだと、ぜんぶおまかせできるようになります。
スライドの右にあるManifestにRollingUpdateの設定を登録し、利用するイメージのバージョンを変更し、アプライすると、よしなにローリングアップアップデートしてくれます。
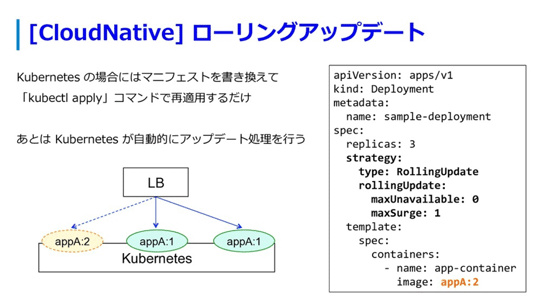
なぞのスクリプトに出会わなくて済むようになる
私がKubernetesをお勧めする理由には、Kubernetesがデファクトスタンダードになっていることで、いろんな人が組織に入ったり出たりするのにも対応できるし、なぞのスクリプトに出会わなくて済み、業界で統一された手段が用意できるのは大きいかなと思います。
Kubernetesの開発にはいろんな会社や人が参加しているので、細かいさまざまなケースもおおむねカバーされていることもいいところだなと思います。
あわせて読みたい
Kubernetesを利用したクラウドネイティブな開発と運用とは何か? これまでと何が違うのか? サイバーエージェント青山氏が語る(後編) July Tech Festa 2019
≪前の記事
Arista NetworksがBig Switch Networksの買収を正式発表。ハイブリッドクラウド向けネットワーキング機能など強化へ

