
AWS、ビジュアルなデータクレンジングツール「AWS Glue DataBrew」発表。大規模データの整理を迅速に実現
データを基に分析を行う場合、対象となるデータがきちんと整っている必要があります。
しかし多くの場合、日付データの中に日付に変換されなかった数値データが混ざっていたり、同じ会社なのに「株式会社」と「(株)」と「(株)」の表記が揺れているせいで別の会社に分類されたり、名前や住所のどこかに余計なスペースが入っていて別のデータになったり、データをインポートしたときのミスで2つの列が連結されて1つの列に入っていたりと、整っていないデータが紛れ込んでいるものです。
これらを整理しなければ、正確なデータ分析はできません。そこで、データ分析の前処理としてデータを整える、いわゆる「データクレンジング」と呼ばれる作業が行われます。
データクレンジングは一般に手間と時間がかかる作業です。どんな外れ値や未整理のデータが存在するのかはデータを見てみないと予想できないことも多いため、ときには目視でえんえんとデータを眺めることさえあるでしょう。
多数の外れ値や未整理の値を一括して変換するためのデータ操作も簡単ではありません。
そのため以前からさまざまなデータクレンジングツールが存在していました。
今回AWSが発表した「AWS Glue DataBrew」は、このデータクレンジングをビジュアルに行えるツールです。同社によれば、従来よりも80%速く作業ができるとのこと。
AWS Glue DataBrew, a visual data preparation tool that enables data scientists and data analysts to clean &
— Amazon Web Services (@awscloud) November 11, 2020
normalize data up to 80% faster, is now generally available. Read this AWS News Blog to learn more: https://t.co/BVp3PA5n4z pic.twitter.com/XUc8s3NPka
対象となるデータを定義したら、データの全体像を把握できます。下記は対象となるデータ全体のなかで重複している値や欠けているデータの量、全体の相関関係などが示されています。
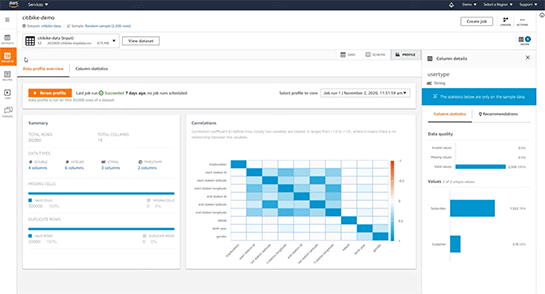
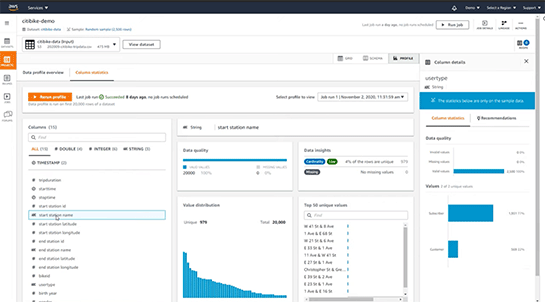
さらに特定の列に注目し、データの総合的な品質、データの分散量(カーディナリティ)、分散の様子、ユニーク値にはどんな値があるか、などもビジュアルに表示できます。
そのうえでデータクレンジング作業を実行できます。画面上のメニューバーに並んでいるのは、よく使われるクレンジングのパターンを実行できるツール群です。これらを組み合わせて実行していけば、変換コードを記述しなくともデータクレンジング作業を進めていくことができます。
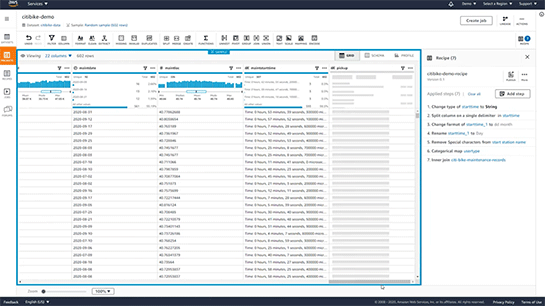
変換作業はプレビューによって適用後の状態を確認することもでき、クレンジング作業はレシピとして保存可能です。
AWS Glue DataBrewは現在、アジアパシフィック(東京)リージョンを含む、米国東部(バージニア北部)、米国東部(オハイオ州)、米国西部(オレゴン)、ヨーロッパ(アイルランド)、ヨーロッパ(フランクフルト)、アジアパシフィック(シドニー)などのリージョンで利用可能になっています。
あわせて読みたい
Docker社、Appleシリコン搭載Mac用の「Docker Desktop」を開発中と表明。Rosetta 2による変換では十分に動かない模様
≪前の記事
軽量でインストールも簡単なシングルバイナリのKubernetesディストリビューション「k0s」、Mirantisがオープンソースでリリース。LinuxとWindowsに対応

