
サーバレスでスケーラブルかつ堅牢なシステムを構築するためのデザインパターンとアーキテクチャ。Serverlessconf Tokyo 2017
サーバレスコンピューティングは新しいシステム開発手法である。Serverlessconf Tokyo 2017で紹介された、スケーラブルで堅牢かつ高性能なアプリケーションの構築に役立つ6種類のデザインパターンを紹介する。
2017年11月2日、3日の2日間、東京都内でサーバレスコンピューティングのイベント「Serverlessconf Tokyo 2017」が開催されました。
サーバレスコンピューティングもしくはサーバレスアーキテクチャと呼ばれるアプリケーション実行環境は、一般にサーバのことを意識せずにアプリケーションを実行できる環境のことを指します。
そのサーバレスコンピューティング環境の実装として一般的なのが、あらかじめアプリケーションとして実行したいコードを関数として登録しておくと、指定されたイベントによって自動的に関数が呼び出されて実行されるという、いわゆるFunction-as-a-Service(FaaS)です。
しかし、このイベントドリブンな関数をどのように組み合わせて適切なシステムを構築するべきなのか、多くのプログラマにとって新しい課題です。
そこで重要な指針になるのが、適切なアーキテクチャやデザインパターンでしょう。本記事で紹介するServerless Conf Tokyo 2017のセッション「Serverless Patterns and Architectures」は、まさにそうした内容をカバーしたものでした。
Serverless Patterns and Architectures
AWSでAPI GatewayとServerlessのPrincipal Product Manager、Dougal Balantyne氏(左)、A Cloud GuruのPeter Sbarski氏(右)。

以下はBalantyne氏とSbarski氏の発言をダイジェストでまとめたものです。
サーバレスアーキテクチャを知ることは、スケーラブルで堅牢かつ高性能なアプリケーションの構築に非常に重要です。
私たちは、強力なデザインパターンの理解こそが、本当にスケーラブルで堅牢なアプリケーションの構築につながると信じています。
そして再利用可能なパターンを用いることで、そうしたアプリケーションの開発はさらに容易になると考えています。
まず、サーバレスの事例を3つ紹介しましょう。米国のオンライントラベルサイトExpediaは、1カ月で12億ものリクエストをサーバレスで処理しています。まさに驚異的です。
米国の金融規制当局FINRAは、毎日5000億件もの米国の株式市場の取引をすべて追跡し、検証しています。これまで大規模なHadoopをベースに展開していましたが、サーバレスを取り入れたことで、よりスケーラブルで高速な処理を実現しました。
金融関係の情報提供機関であるトムソンロイターは、1秒あたり4000件のリクエストをサーバレスで処理することで、スケールアップ、スケールダウンをオンデマンドで実現しています。
こうしたサーバレスアーキテクチャでのソリューション構築における、基本的なパターンを紹介しましょう。
Compute as backend
Restful APIがAWS API Gateway経由でAWS Lambda Functionにつながっています。
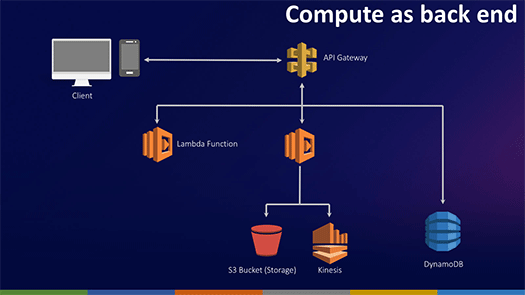
クライアントがリクエストをAPIに送るとこれがLambda Functionを呼び出し、そこからさまざまな処理が行われて、結果がAPI Gateway経由でクライアントに戻されます。
クライアントからはサーバレスがバックエンドにあることはわからず、API GatewayがAWSのサービスを統合する役割を果たしています。
このパターンでは、API Gatewayが必ずLambda Functionを呼び出さずともよく、DynamoDBを呼び出すこともあります。
われわれはこれをハイブリッドアーキテクチャと呼んでいます。このアーキテクチャはAPI Gatewayを活用することで、Lambda Functionを呼び出すだけでなく、通常のアーキテクチャのアプリケーションを呼び出すこともできます。
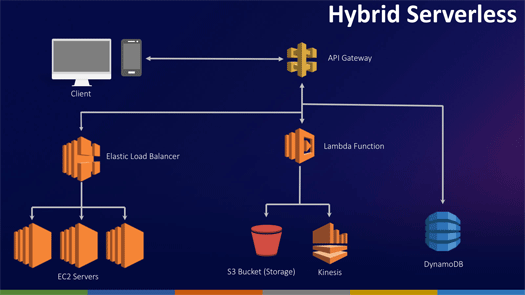
すべての機能がAPI Gatewayにつながっており、ここで統合されます。
ですので、サーバレスアーキテクチャへの移行はまずこのパターンからはじめて、時間をかけて通常のアーキテクチャから移行していけばいいのではないか。おそらく移行にもっとも手間取るのはデータの永続性に関する部分だと考えられる。
例えば、予約サイトであれば予約の処理部分はトラフィックが増えても対応できるようにサーバレスにして、それ以外のレガシーな部分は残しておいて、徐々に移行すればよい。
GraphQL
GraphQLはFacebookが2012年に開発したクエリ言語です。
このパターンでは単一のエンドポイントがLambda Functionとして存在し、ここでGraphQLが実行され、そこに接続された複数のデータソースで処理されます。
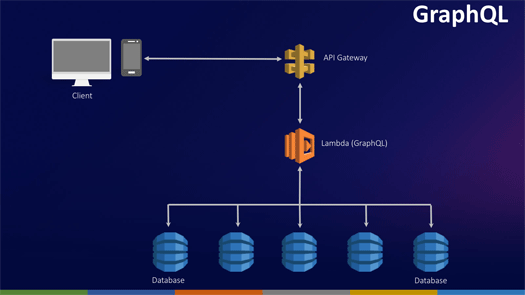
クライアントがデータをリクエストすると、GraphQLエンドポイントのLambda FunctionがGraphQLを実行、DynamoDBのデータ結合などの処理を行ったうえで答えをクライアントに返します。
これは非常に強力で効果的なパターンです。
Legacy API Wrapper
これはAPIファーストなアプローチを実現する場合のパターン。とりわけシステム内部ではSOAPやXMなどを使ったアプリケーsyンを、API Gatewayを使ってREST API対応のモバイルアプリケーションやWebアプリケーションとする場合に使われます。
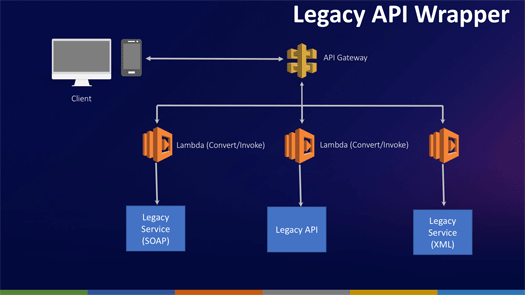
Compute as glue
これは私がいちばん好きなパターンです。
さまざまなサービスに対してAWS Lambdaを接着剤(Glue)として使うというもの。データの抽出や変換などを行うデータ分析などでのパイプライン処理などで、非常に強力なパターンとして使えます。
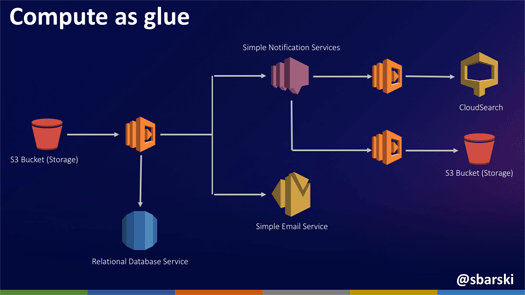
この例では、S3 Bucketにデータを入れるとそのイベントがAWS Lambdaを呼び出し、そこでRDBのアップデートとともにSMSにメッセージをプッシュ、さらにSESでメールを送信する、といった形でAWS Lambdaの処理のパイプラインをどんどん伸ばしていくことができます。
私たちの会社では動画のフォーマット変換をこのパイプラインを用いて行っていますが、非常にスケーラブルに処理してくれます。
Metrics Pattern
これは非常に重要なパターンですが、おそらくまだ多くの人の前で語られたことのないものでしょう。
従来のアプリケーション開発では、そのアプリケーションが正常に稼働しているかどうかなどをメトリクスを取得することでモニタリングします。

サーバレスアーキテクチャでも同様ですが、多くのユーザーが用いているパターンは、まずLambda Functionのアプリケーションロジックなどのコードを書き、さらにその処理やデータベースへの接続にどのくらい時間がかかったのかをメトリクスを出力するために計算し、外部のモニタリングサービスやCloud Watchへ送信するというものです。
しかしこうしたコードは完璧に動作するかもしれないし、バグがあって動作しないかもしれません。
そこでみなさんと共有したいパターンは、AWS Lambdaからの大量のメトリクス取得を可能にするものです。
この例で協調すべきなのは、API Gatewayでの処理に続いてLambdaに処理が移ると、Lambda Function内部でJSONオブジェクトにメトリクスが出力され、明示的にメトリクスサービスに接続することなく、それが自動的にCloud Watch Logに書き込まれるということです(新野注:AWS Lambdaには自動的にCloud Watchにログを出力する機能がある、ということ)。
ポイントは、これが非同期に行われるため、メトリクスサービスへ接続するためにLambda Functionの実行に待ちが発生するといったことのない点です。
これによってメトリクスのログへの書き込みはLambda Function内で高速に行えるとともに、メトリクスサービスもアプリケーションの規模に合わせて自動的にスケールしてくれるため、ログ側の心配をすることもありません。
これは非常に大事なパターンなので、ここで紹介できてうれしく思います。
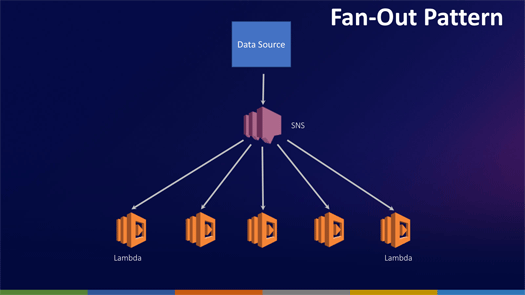
Fan-Out Pattern
これはAWSにおいてクラシックなパターンでしょう。たぶんAWSのアーキテクトとして資格を得るにはこのパターンを学ぶことになるのではないでしょうか。
例として示しているのはデータソースからイベントがSNSへ送られ、トピックスが生成されます。Lambda Functionはトピックスをサブスクライブしており、それぞれのLambda Functionは同じデータを基にもとにそれぞれ異なった処理へと、自動的に広がっていくようになっています。
ここでは6種類のパターンを紹介してきたが、これは最初の取り組みであってほかにもさまざまなパターンがあります。
今後さらに新たなパターンについても議論を進めていきたいと考えています。
あわせて読みたい
分散ストレージの仕組みの違いが、ハイパーコンバージド製品を見極める重要ポイント[PR]
≪前の記事
jQuery MobileとjQuery UI、停滞を打破するため開発体制を刷新。以前より簡単にコントリビュート可能に

