
NoOpsを実現できる時が来た。「NoOps」とは運用の“嬉しくない”ことをなくすこと。NoOps Meetup Tokyo #1
9月12日に都内で「NoOps Meetup Tokyo」の第一回が開催されました。
この「NoOps」は運用そのものをなくしてしまう「No Ops」ではなく、運用の嬉しくないことをなくす「No "Uncomfortable" Ops」だと、NoOps Japan発起人の岡大勝(おか ひろまさ)氏は説明します。
NoOpsの具体的な意義と、それをどのように実現するのかを説明した岡氏のセッション「15分で分かる NoOps」をダイジェストで紹介しましょう。

参考:「NoOps? よろしい、ならば戦争だ」。NoOpsコミュニティに異議申し立てた「Opsの味方」。決裂か? 和解か? NoOps Meetup Tokyo #1
NoOpsの目指すもの
今日お伝えしたいことは3つです。「NoOpsの目指すもの」「なぜいまNoOpsなのか」「NoOpsのつくりかた」

「NoOps」とは、「No Uncomfortable Ops」つまりシステム運用の嬉しくないことをなくそう、ということ。

嬉しくないこととは、おもに3つあげられます。
1つ目はユーザーの体験を妨げないということ。例えば障害時のダウン、計画停止、負荷集中時の性能低下などはユーザーの体験を妨げます。
2つ目は運用保守の現場での「トイル」です。トイルとは、リリース手続きやパッチの適用など、人間がやるべきでないような作業、これを最小化しましょうと。
3つ目はシステム運用保守におけるリソースとコスト。これは忘れられがちですが、実は1つ目や2つ目はサーバリソースにお金をかけたりヒューマンリソースを豊富に投入すれば問題にならないかもしれません。でもそうではなく、リソースやコストの最適化をしましょうと。
いまならすべてが改善できる、という時が来た
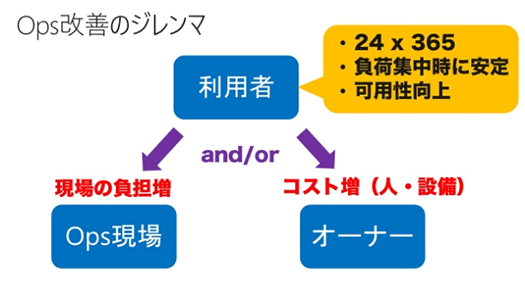
こうしたことを目指したNoOpsのためにOpsを改善しようとすると、ジレンマが立ちはだかります。
利用者の体験を向上させようと24時間365日運用、負荷が集中しても安定して稼働し、可用性も高めようとすると、運用の現場の負担は増し、コストもかかる。
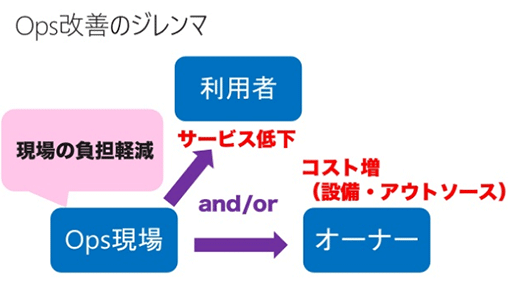
一方、運用の現場の負担を軽減しようとして、例えば待機人員をなくすとするとサービスが落ちても対応できなくなってサービスの低下につながります。また現場の負担を軽減するための設備投資やツールの導入、アウトソースの採用などはコストがかかります。
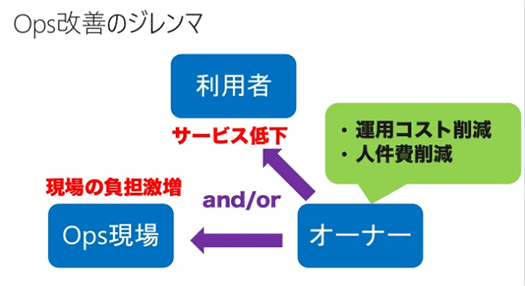
サービスのオーナーはコスト削減しようとすると、サービスの低下や運用の現場の負担増につながります。
こうして「結局何をやってもあまり効果がでないね」というループになって、これまで同じようなやり方で運用の現場を何年も回してきたんじゃないかと思います。
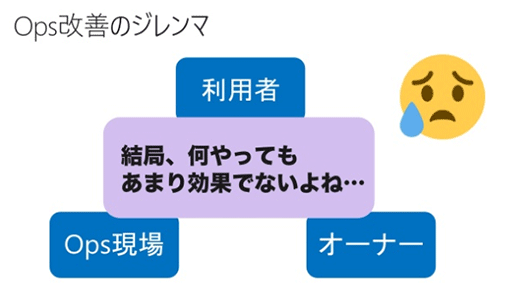
しかしいまなら、すべてが同時に改善できる、という時が来たと思っています。
(それがNoOpsへの取り組みです)
NoOpsの鍵は高い復元力
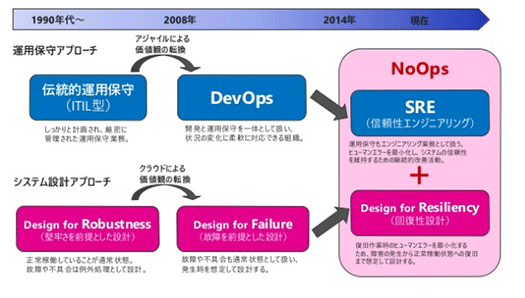
10年前あるいは20年前は、システムの「堅牢性」が信頼性でした。MTBF至上主義で、多重化や高度なエラー検知と訂正機能などを持つサーバが作られ、その高価な機器を10年保守や20年保守で大切に使っていました。
その価値観がこの10年で大転換して、十分な性能や帯域を持つシステムが安価に手に入るようになって、これらを入れ替えながら、信頼性はソフトウェアで構成しましょうという世界になりました。「Design for Failure」です。
技術の変化とともに設計思想も変化していきます。堅牢性を設計する「Design for Robustness」から、障害を前提とする設計の「Design for Failure」になったわけです。
そしていま、ここから進化して「Design for Resiliency」、回復性設計の時代に来ています。これは障害から回復して動作を続行する能力を持つシステムを設計するものです。

NoOpsの鍵は、高い復元力です。

別の言葉で言うと、取り回しの軽さ。
例えば、ChefでWordPress環境を構築する時間が240秒、これがコンテナでWordPress環境を構築する時間が14秒。

アプリケーションのタイムアウトはだいたい30秒くらいですから、アプリケーションが壊れても30秒以内に検知して再構築してReadyになるのなら、ユーザーから見れば壊れていない、サービスが続いている、ということが実現できます。
コンテナやOSをできるだけ小さくしようというのは、こういうところを目指しているのです。
「壊れない」システムから、「いつでも回復できる」システムへの価値観の転換です。

いままで、復元力は低いけれど高い可用性が欲しい場合、冗長構成が必要でした。
しかしいまは高い復元力が手に入る。
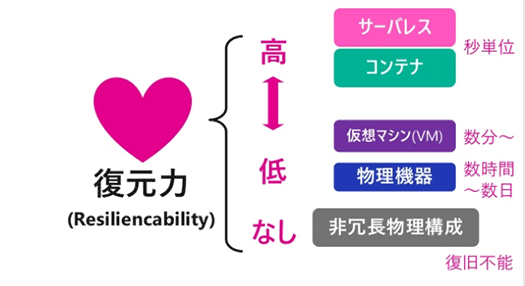
つまりひとりでも「高い可用性」が手に入るようになったのです。

しかもそれだけじゃなくて、高い復元力を持つことで、障害発生時の自己回復だったり、オンザフライでのインスタンス変更、秒単位のスケールアウトやスケールインなどができる。

NoOpsの作り方
NoOpsの実現には「復元力」(Resiliencability)だけでなく、障害が起きたときにそれをいかに早く検知する観察力「Observability」も必要です。ログを見て検知するのでは遅い。
そして障害を検知したら、システムを再構成する能力「Cofigurability」も必要です。
例えば、クラウドのあるリージョンが死にましたと。それを検知してオンタイムで別のリージョンで同じシステムを構成して復元します、ということも現在では可能です。データさえ同期させておけば、検知して、構成して、復元できるのです。
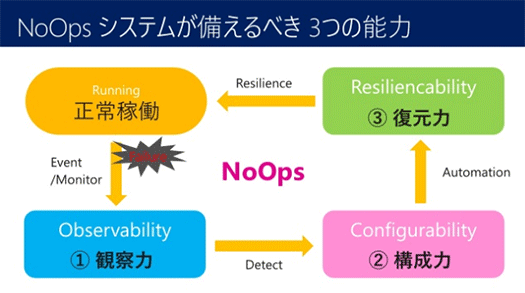
こうしたことを実現する上でいちばん大事なのは、仕様には書かれていないこの観察力、構成力、復元力を兼ね備えたシステムやサービスを採用することで、これには目利きが必要です。

ミドルウェアやインフラが回復力を持っていても、例えばバッチ処理を回しているときに落ちました、というときにはインフラだけ復元させてもだめで、バッチ処理のどこで落ちたか、どこから再実行するかといった人の手が処理の回復に必要です。
だからアプリケーション側にも回復力を持たせる必要があります。

そのための原則として、粒度はできるだけ小さく。例えば1時間もかかる処理は復元が難しくなります。
処理はステートレスで。ステートを持たせても消えてしまいます。
非同期処理。同期処理だとすべてのプロセスが連鎖していくので、途中で落ちたら最初からやり直しです。
いちばん大事なのが処理の冪等性を担保すること。どのサーバで何回リトライしても、正常終了したら結果は同じ場所に同じ値が書き込まれる。この冪等性をすべての処理で担保する。
さらに追跡可能性という意味で処理結果を記録します。

目指すところは、シンプルなリトライです。落ちました、そしたらリトライする。それでだめなら別サーバでリトライする、それでもだめなら別リージョンでリトライする。それで大丈夫な設計にしていきたい。
NoOpsを実現するチームとは
最後に、NoOpsを実現するチームについて。
運用のアプローチ、設計のアプローチが合わさって、いまちょうどDesign for ResiliencyとSREが出会って、NoOpsが実現できるタイミングになりました。
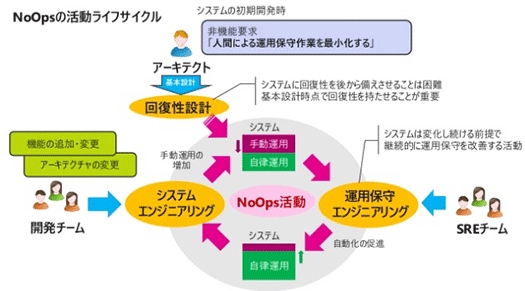
それを次のようなライフサイクルで回していきたい。
まず、回復性はあとから手に入るものではなくて、最初から設計しておかなくてはいけません。ですのでアーキテクトはシステム設計では最初から回復性設計をします。
そこから最初は手動運用も入れつつ、SREチームは運用保守エンジニアリングで自動化をして、自律運用を実現していきます。
その中で、プロダクトはDevOpsで日々リリースされて進化しますので、機能の追加や変更、アーキテクチャの変更などがあります。すると運用に手動の部分が増えてくる。それをまた運用保守エンジニアリングで自律運用へ近づけていく。
こういうサイクルを目指していきたいなと。
NoOpsは待っていても来てくれません。
システム運用の嬉しくないことをなくして、ユーザーも運用現場の人も開発者もオーナーも、みんな「このシステムいいよね、もっとやっていきたいよね」ということを実現するために、NoOpsのコミュニティを始めました。ぜひみんなで、これからも情報交換などしていきたいと思います。

下記が公開されているスライドです。
NoOps Meetup Tokyo #1
あわせて読みたい
マーク・ベニオフ氏が米Time誌を1億9000万ドルで買収。一方、ジェフ・ベゾス氏は貧困層支援の基金を20億ドルで立ち上げ
≪前の記事
ニュースメディアの求人、記者や営業よりソフトウェアエンジニアが高給待遇。米Glassdoor

