
メルカリは開発組織を拡大するためにマイクロサービスアーキテクチャを採用した(後編)。Mercari Tech Conf 2018
メルカリはこの1年、マイクロサービスアーキテクチャにどう取り組み、実現のためになにをしてきたのか。技術面と組織面の双方に関する興味深い取り組みが、10月4日に都内で行われた同社主催の技術カンファレンス「Mercari Tech Conf 2018」のセッション「Microservices Platform at Mercari」で紹介されました。
(本記事は「メルカリは開発組織を拡大するためにマイクロサービスアーキテクチャを採用した(前編)。Mercari Tech Conf 2018」の続きです)
DevOps文化を組織内に醸成する
次はDevOps文化の醸成です。
この1年で、マイクロサービスの開発者が自分たちでできるようになったことが大きくふたつあります。
ひとつ目は、インフラのセットアップとプロビジョニング。ふたつ目はサービスのデプロイです。
まず、プロビジョニングから。
先ほど、各開発チームがKubernetesのネームスペースやGCPのサービスにアクセスできるようにした、という話をしました。
そこで例えばGCPのデータベースを使いたいときにはデータベースをセットアップする、という作業を行います。これがプロビジョニングです。
われわれはこのプロビジョニングを「Infrastructure as a Code」の文化を浸透させることで実現しています。

具体的なツールとしては、HashiCorpの「Terraform」を使っています。
Terraformは、GCPやAWSなどのクラウドサービスを抽象化して、宣言的にコードとしてインフラのあるべき状態を記述することで、その状態になるようにプロビジョニングを実行してくれます。
各マイクロサービスごとのTerraformのコードの管理やそのコードの自動アプライを実現するために、microservices-terraformというリポジトリを準備しています。
このリポジトリにはStarter-kitというTerraformのモジュールも提供されています。これを使うことでマイクロサービスをリリースするための最低限必要なインフラを簡単に構築できるようになっています。
最低限必要なインフラとは、さっき紹介したNamespaceやGCPプロジェクトがあり、またモニタリングの設定だったり、それらをStarter-Kitを使って一発でブートストラップできます。
開発者はまず自分たちでTerraformのコードを書いて、このリポジトリにプルリクエストをかけます。
インフラの経験が少ない開発者がいきなりTeraformのコードをがりがり書くのは難しいので、われわれマイクロサービスプラットフォームチームがレビューを行います。レビューが通ってマージが行われると、CIが走ってプロビジョニングが行われるというフローになっています。
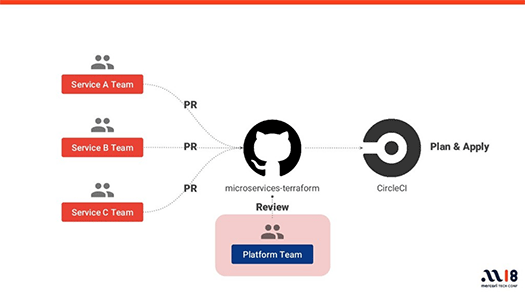
開発者が自分たちでインフラのプロビジョニングができるように
このワークフローで問題になるのは、マイクロサービスプラットフォームチームによるレビューのところです。Terraformのコードを保守していくためにはレビューは必須なのですが、マイクロサービスが増えれば増えるほどここがボトルネックになってスピードが失われてしまいます。
これを解決するためにGitHubのCODEOWNERSという機能を使います。
CODEOWNERSを使うとリポジトリの特定のディレクトリにコードオーナーを指定できます。コードオーナーはプルリクエストのアプルーブやマージができます。
この機能を使ってGitHubの各サービスの専用ディレクトリに、各サービスのチームメンバーをコードオーナーとしてアサインします。すると、自分たちのサービスに関するプルリクエストは自分たちでアプルーブしてマージできるわけです。
つまり、何度かわれわれマイクロサービスプラットフォームチームのレビューを受けて、自分たちでTerraformのコードを書く自信が付いたら、自分たちでレビューしてスピード感を持って進めればいいし、まだちょっと不安があるチームはわれわれのレビューを受けて、書き方を覚えてもらう、ということをやっています。
この仕組みはとてもうまく回っていて、いまではこのリポジトリに110名ものコントリビュータがいます。これはどういうことかというと、100名以上の開発者が自分たちでインフラのプロビジョニングをしているということです。

1年前、インフラの管理ができるのはSREの10名くらいしかいませんでした。そこから10倍以上の成長です。
この変化は、マイクロサービスプラットフォームチームがもたらした大きなものだといえます。
デプロイのパイプラインも開発者が作る
次はサービスのデプロイです。
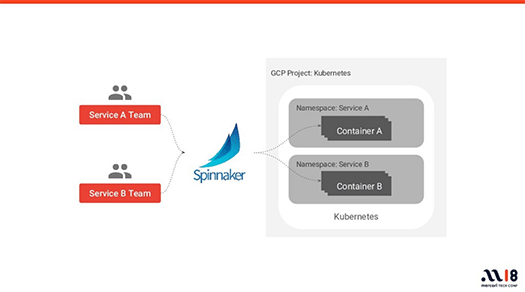
マイクロサービスではデプロイも、開発者が自分たちで行います。このために「Spinnaker」というツールを使っています。
SpinakerはNetflixがオープンソースとして公開した継続的デリバリのためのツールです。
参考:Netflix、マルチクラウド対応の継続的デリバリを実現する「Spinnaker」をオープンソースで公開
Spinnakerは例えば、カナリアデプロイメントを行うステージ、Blue/Greenデプロイメントを行うステージ、デプロイの承認を行うステージなど、さまざまなステージを提供しています。開発者はサービスの特性に合わせたステージを組み合わせてデプロイを行うことができます。
すでにSpinnakerを使い始めて1年ですが、60以上のパイプラインが作られています。
これはSpinnakerの設定画面です。開発者はこの画面を通じてデプロイの設定をしています。ただ、これはGUIなので、ここが開発者のペインポイントになっていました。
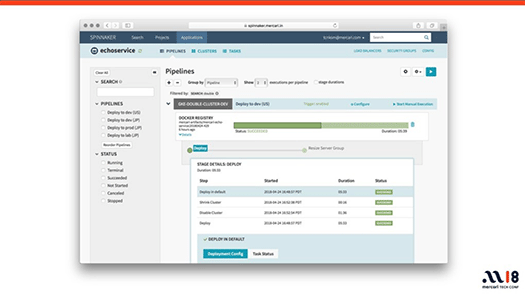
GUIは小規模なチームが素早く動くには便利だと思うのですが、チームがスケールするほど変更したときのレビューができないとか、ドキュメント化するのがむずかしいとか、ほかのチームの設定をコピーして使うことができないといった問題があります。
これを解決するためSpinnakerにもInfrastracture as Codeへの移行をはじめています。
具体的には「Kubernetes v2 Provider」というSpinnakerの機能を利用しています。これはKubernetesのYAMLを直接書く方式です。つまりKubernetesのYAMLさえも開発者に書いてもらおうという方向に進んでいます。
これもTerraformと同様にGitHubにプルリクエストを送ってレビューをする方法を採用しています。
この仕組みは導入したばかりですが、GUIの設定の負担を減らして、かつ、Kubernetesの設定であるYAMLファイルを覚えることで、開発者が自分たちにとってよりよいKubernetesの設定をカスタマイズできるようになるのではないかと期待しています。
以上が、この1年のわれわれマイクロサービスプラットフォームチームが取り組んできたことです。
マイクロサービスプラットフォームチームがこれから取り組もうとしていること
最後に今後われわれがどのようなことに取り組んでいきたいか、について紹介します。
先ほど紹介したように、現在本番で動いているマイクロサービスの数が19に対して、開発中のマイクロサービスは73あります。
マイクロサービスの開発を始める環境はできてきた一方、これからは本番環境に出て行くマイクロサービスが増えてきます。すると次の課題は、いかにマイクロサービスの開発者が自分たちのサービスを高い信頼性を持つサービスとして運用できるようになるか、です。
これに対していくつかアイデアがあります。
ひとつ目のアイデアは、GoogleのSREが採用しているSLI/SLOという指標を導入することです。

SLIはService-Level Indicatorで、サービスレベルの定量的な指標です。SLOというのはService-Level Objectiveで、SLIに対する目標値です。これらはサービスの特性に合わせて決定することができます。
例えば、速くレスポンスを返すことが重要なサービスであれば、SLIはすべてのリクエストのうち100ミリ秒以内にレスポンスを返した割合で計る、といったものです。
SLIとSLOを設定することで、サービスの機能の開発とリライアビリティ(信頼性)に対する取り組みのバランスを数字を使ってとることができるようになります。
SLOを99.9%に設定した場合、これを満たしているうちはひたすら機能開発を続ける。これを下回ってしまったら機能開発を止めて、リライアビリティの向上に努めるといったことができます。
これによって機能開発ばかりやって障害がひんぱんにおきるサービスをなくしたり、逆にリライアビリティばかり追求して機能追加が進まないといった状況を避けることができる。
マイクロサービスプラットフォームチームとしては、SLI/SLOという考え方を浸透させることがまず重要で、そのあとにサービス全体のSLOを俯瞰できるようなダッシュボードを整えていくのもひとつのアイデアかなと思います。
カオステスティングの導入
ふたつ目のアイデアはカオステスティングです。

これまで障害対応は開発者が自分でやることはなかなかありませんでしたが、これからは開発者が障害に対する一時対応をやっていく必要があります。
カオステスティングの手法でわざと障害を起こして、問題になるコードをすぐ見つけるとか、障害が起きたことにすぐ気づけるかとか、そもそもモニタリングやアラートが動いているかを確認することができる。
また開発者が障害対応を経験することで、実際に障害が起きても落ち着いて対応できるようになる、みたいな仕組みを作っていきたいと思っています。
サービスメッシュの採用
そして最後はサービスメッシュです。

モノリシックなアプリケーションでは関数呼び出しですべてが完結しました。しかしマイクロサービスにおいてはネットワーク越しのコミュニケーションが大量に発生します。
サービスメッシュを導入することで、サービス間のコミュニケーションのオブザーバビリティ(観察性)を改善するとか、ネットワークコネクションのリライアビリティを向上させるとか、セキュリティを強化することもできると思っています。
以上で発表を終わります。ありがとうございました。
公開されているスライドはこちら。
Mercari Tech Conf 2018
あわせて読みたい
開発者らが日常業務から2日間離れ、自由なアイデアの実現に集中するメルカリの社内ハッカソン「Go Bold Day」とは。Mercari Tech Conf 2018
≪前の記事
メルカリは開発組織を拡大するためにマイクロサービスアーキテクチャを採用した(前編)。Mercari Tech Conf 2018

