
Linuxバイナリを最適化して性能を向上させる「BOLT」、Facebookがオープンソースで公開。言語やコンパイラに依存せず高速化
Facebookは、Linuxバイナリの内部配置を最適化することによりCPUのキャッシュ効率などを向上させ、実行速度を改善する「BOLT」をオープンソースで公開しました。
BOLTは「Binary optimization and layout tool」の略とされています(もしかしたら、より速く走るという意味でウサイン・ボルト氏にかけているのかもしれません)。
BOLTは言語やコンパイラに依存せず、ソースコードも不要
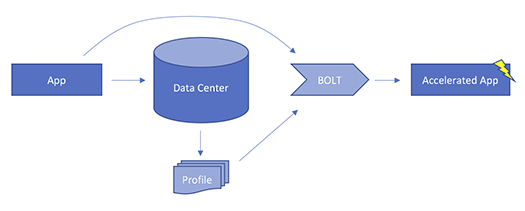
BOLTのおもな効果は、Linuxバイナリの実行状況をperfコマンドで取得し、高頻度で実行されている部分などを判別した上で、そうした部分がCPUキャッシュにヒットしやすいようにバイナリの内部配置を改善することなどで実行速度を向上させることと説明されています。
そして最大の特徴は、どのようなプログラミング言語やコンパイラ、リンカが使われていても対応できるという点です。従来の最適化ツールはコンパイラレベルで行われるために言語に依存したりしていましたが、BOLTはそうした依存性がありません。
バイナリの動作を直接観察し、その結果をもってバイナリを直接操作するため、ソースコードも不要です。つまり、既存のアプリケーションやバイナリだけが提供される商用アプリケーションにさえ適用可能です。(追記 6/21 11:00 最適化にリンカの操作が求められるので、上記の表現を削除します。お詫びして訂正します)
BOLTを紹介したFacebookの記事「Accelerate large-scale applications with BOLT | Engineering Blog | Facebook Code」から、その動作内容の一部を引用します。
In order for BOLT to perform a new code layout for an application, it has to reconstruct the control flow graph for the code. The task is similar to de-compilation, except we only have to find high-level constructs, such as branches with all possible source and destinations, and loops. We don’t have to perform other de-compilation tasks, such as local variables detection.
BOLTがアプリケーションのために新しいコードレイアウトを実現するためには、コードのコントロールフローグラフを再構築しなければならない。この作業はデコンパイルに似ているが、ここでは分岐の開始と行き先やループといった高レベルの構造だけを見つければいい点が異なる。
Internally, the application is represented as a set of functions operating on a set of data. We designed our own internal representation, which uses LLVM’s MCInst format for instructions.
内部的には、アプリケーションは一連のデータ上にある一連の機能操作として表現される。われわれは独自の内部表現を用いており、これはLLVMの命令用MCInstフォーマットとしている。
下記はこの記事中で示されたグラフ。BOLTによって処理されたバイナリは、頻繁に実行される部分が集中していることが分かります。
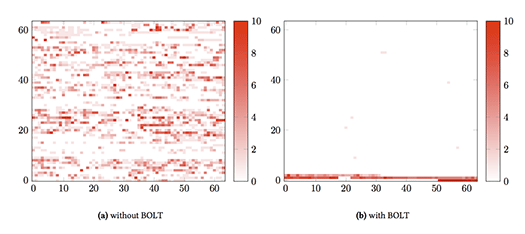
FacebookはBOLTを用いて同社のアプリケーション実行環境であるHHVMを処理したところ、実行状況によって度合いが異なるものの、おおむね2パーセントから15パーセント程度の性能向上が見られたとのことです。
参考
あわせて読みたい
国内でCNCF公認の「認定Kubernetes管理者」「認定Kubernetesアプリケーションデベロッパー」試験が今秋開始、日本語でトレーニングと受験が可能。クリエーションライン
≪前の記事
機械学習を高速処理するGoogleの「Cloud TPU」サービス、7割引きの利用料で使えるプリエンプティブに対応

