
「Prometheus 2.0」正式版リリース。クラウドやコンテナなど動的な分散環境に対応した統合監視ツール
Prometheusはクラウド上のシステムに代表される、監視対象となるサーバが増減するような動的な分散環境システムに適した監視ツールとして開発された。2.0では時系列データベースが改善され、性能向上などを実現している。
オープンソースで開発されている統合監視ツール「Prometheus」の最新バージョンとなる「Prometheus 2.0」正式版のリリースが発表されました。
Prometheusはアプリケーションやコンテナ、Kubernetesのようなオーケストレーションツール、OS、サーバ、ネットワークなど、システムを構成するさまざまな要素を監視対象とすることができ、メトリクスとしてCPUの負荷やメモリ、ストレージの利用率、HTTPのレイテンシなど任意の値を取得、監視できる統合監視ツールです。
状況をグラフで表示しつつ、異常を検知するとアラートを発するなど、システム監視を統合的に行うことができます。さらにリッチなビジュアライズについては「Grafana」などの外部ツールと連携可能。
Prometheusは、DockerコンテナのオーケストレーションツールであるKubernetesの開発をホストするCloud Native Computing Foundationが、Kubernetesに続く2番目の開発プロジェクトとして採択されました。現在はCloud Native Computing Foundationのホスト下で開発されています。
Prometheusの主な機能と仕組み
Prometheusの共同開発者の一人であるJulius Volz氏が、2017年5月に行われたイベント「DockerCon '17」で行ったPrometheusのセッションを基に主な機能や仕組みを簡単に紹介しましょう。
下記がPrometheusのアーキテクチャ図です。ターゲットからメトリクスを取得し、それを基にアラートマネージャでアラートを発したり、Grafanaを用いてグラフィカルなダッシュボードを表示します。
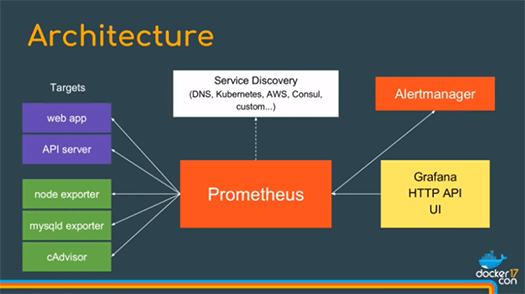
ターゲットから取得したメトリクスの格納には時系列データベースを用いています。
この時系列データベースはPrometheus独自のもので、ミリ秒のベースで時刻と値を保存。マルチディメンショナルなデータモデルによって、メトリクスの名前と値がセットで保存されます。
これにより、時系列データベースに対してメトリクスごとの値を取り出して演算するようなクエリを可能にしており、これがPrometheusの多くの機能を支えています。
時系列データベースなどを保存するストレージは、シンプルな実装をあえて選択した結果ローカルストレージ上に実装されています。クラスタリングなどの複雑な機能は備えず、可用性には2つのPrometheusを同時に実行するなどで確保。その代わりPrometheusのバイナリをサーバで実行すれば複雑な設定なしですぐに利用可能になります。
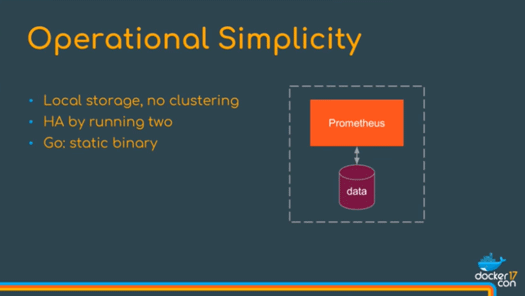
この実装でも1秒あたり100万以上のメトリクスを保存でき、小規模な組織でのモニタリングには十分だと説明されています。Prometheus 1.6からはリモートストレージへの書き込みに対応し、よりスケーラブルで堅牢、長期間のデータが保存できるようになりました。
さらに後述するようにPrometheus 2.0では時系列データベースが全面的に書き直され、性能が向上しているため、よりスケーラブルになっているとされます。
Prometheusは、ターゲットに対して情報を取りに行く、プル型の仕組みを採用しています。
しかし、たとえばクラウド対応のアプリケーションでは負荷に合わせて仮想マシンが起動されて増えたり、終了されて減ることがありますし、アプリケーションの機能追加に合わせてデータベースが増えたりと、監視対象となるターゲットの環境や個数はいつも変化する可能背があります。
こうした動的なシステム環境に対応するべくPrometheusに備えられているのが「Service Dicsovery」(サービスディスカバリ)機能です。
Service Discoveryは、監視対象とすべきターゲットを自動的に発見する機能のこと。これがあらかじめPrometheusに組み込まれているため、ターゲットが動的に変化しようとも、Prometheusは追随することができるわけです。
Prometheusには最初からAWSやAzure、Googleなど主要なクラウドの仮想マシンや、Kubernetesなどのコンテナスケジューラ、DNSやZookeeperといった一般的なサービスに対応するService Discovery機能が組み込まれています。

PrometheusはGoogleのBorgmonに触発されて開発
下記は、2017年8月にドイツのミュンヘンで開催されたPrometheusの年次イベント「PromCon 2017」のオープニングセッションで示されたPrometheusの年表と予定です。
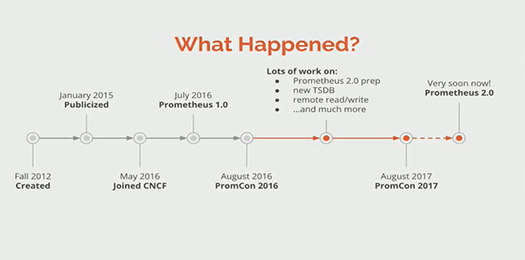 2017年8月に示されたPrometheusのロードマップ。まだこの時点ではPrometheus 2.0はComing Soonだった
2017年8月に示されたPrometheusのロードマップ。まだこの時点ではPrometheus 2.0はComing Soonだった Prometheusはもともと音楽共有サービスを展開する「SoundCloud」が2012年に社内で開発を開始したものです。
前述の共同開発者の一人であるJulius Volz氏は、2012年にGoogleからSoundCloudに転職。Volz氏によると、まだ世の中にDockerやKubernetesが登場する前の2012年の時点で、SoundCloudのシステムは動的にクラスタを管理するスケジューラを基盤としたマイクロサービス的なアーキテクチャを採用していました。
そのため、そうした動的な環境で効率よくシステムをモニタリングするためのツールが必要とされていたのですが、適切なものは当然ながらまだ存在していません。
Google社内ではすでにそうした環境に対応したモニタリングツール「Borgmon」を開発、利用を開始しており、SoundCloudはそれに触発されて後にPrometheusとなるモニタリングシステムをオープンソースで開発することにしたとのことです。
その後、Prometheusは2015年に公開され、2016年5月に前述のようにCloud Native Computing Foundationがホストとなって開発を主導するようになります。そして同年7月に「Prometheus 1.0」がリリースされます。
そこから約1年半で、今回のバージョン2.0が正式に登場しました。
内部で使用されている時系列データベースを改善
Prometheus 2.0では、時系列データベースが完全に書き換えられた新しいものとなりました。その結果、あらゆる面で効率性や性能が向上していると説明されています。
例えばPrometheus 1.8と比較してクエリのレイテンシがより安定し、CPUの利用率も20%から40%減少、ストレージの消費量も33%から50%減少。ディスクI/Oの負荷は、負荷の高いクエリがない平均的な状態では1%以下になっています。
またデータベース全体のスナップショットをとることも可能になっています。
今後は時系列データベースが新しくなったおかげで、Prometheusの機能を拡張しやすくなり、より積極的な機能拡張などが行われていくとされています。
あわせて読みたい
テスラのAI部門長が語る「Software 2.0」。ディープラーニングは従来のプログラミング領域を侵食し、プログラマの仕事は機械の教師やデータのキュレーションになる
≪前の記事
Apache Kafkaがついにバージョン1.0に到達、オープンソース化から約7年。大量のデータを高速に収集できるメッセージ処理システム

