
Kubernetes 1.6が登場。etcd3とgRPC採用で大幅な性能向上、チームやワークロードごとに名前空間を分離、物理ノードを考慮しデプロイ可能など
オープンソースで開発されているコンテナのオーケストレーションツール「Kubernetes」の最新版、「Kubernetes 1.6」がリリースされました。
リリース翌日の29日(日本時間30日夕方)にドイツのベルリンで開催されたイベント「Cloud Native Con+KubeCon Europe 2017」では、このKubernetes 1.6の主要な新機能が紹介されました。
Kubernetes 1.6はGoogle社員以外がマネジメントした最初のリリース
Kubernetes 1.6のテーマは、複数のチーム、複数のワークロードを大規模展開で実現するというものです。また、今回のリリースはGoogle社員以外の人間がマネジメントした最初のリリースでもありました。リリースリードとなったのはCoreOSのCaleb Miles氏。

Kubernetes 1.6では5000ノードの規模のクラスタをサポート(Pod数にして15万)。ロールベースのアクセスコントロールを実現し、ワークロードごとに異なるスケジューリングを可能にした「Controlled scheduling」に対応。
「Dynamic Storage Provisioning」では特にステートフルなアプリケーションにおいて有用なストレージの自動化が実現しています。
また、このリリースにおいても、そして今後のリリースにおいても安定性に重点がおかれることになっています。
etcd3やgRPCプロトコルの採用で大幅な性能向上
5000ノードというスケールを実現した背後にあるのがCoreOSのetcd3。ノード間のデータモデルやコミュニケーションフレームワークがアップデートされ、JSONからgRPCプロトコルになったおかげで大幅な性能向上を果たしています。

そして、複数のチームが邪魔しあうことなく、異なる複数のワークロードを効率よく、1つのクラスタで実行できるようにするための重要な機能が新しく追加された「Role Based Access Control」(RBAC)です。
Kubernetesのある開発者は、KubernetesにRBACが実装されることを「誰もがファイルを見て実行できるシングルユーザーのDOSから、ユーザーごとにパーミッションを持つUNIXへと変革されたようなもの」と表現しています。
RBACによって、異なるワークロードを実行するそれぞれのチームを、それぞれの名前空間に分離し、適切な粒度のパーミッションを与えることができるようになります。
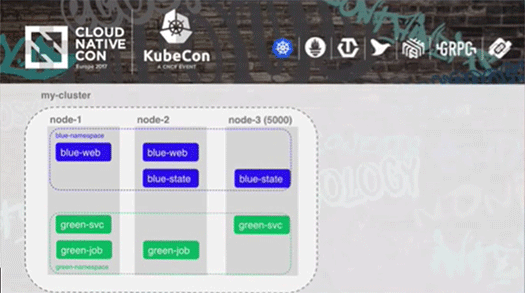
例えば「ブルー」という名前空間が与えられたブルーチームは、このブルーの中でポッドやサービスの作成、削除、実行などが可能になります。また、グリーンチームに対して参照権だけを与えて、グリーンチームがブルーチームをモニタリングできる、といったことも可能です。
これによって1つの大規模なクラスタ内で複数のチームが安全に共存できるようになります。
ワークロードごとに最適化したスケジューリングが可能に
Controlled Schedulingは、ワークロードごとに最適化したスケジューリングができるというもので、複数の機能から構成されます。

「Node/Pod affinity/anti-affinity」では、Podごとにどんなノードにデプロイするかを指定できます。例えば、このPodはこのゾーンのこのノードに固定する、あるいはSSD内蔵のノードに固定するといった指定や、特定のラベルが付いたノードにのみスケジュールする、といったことが可能です。
また、Pod同士の関係も定義でき、例えばデータセンターでできるだけ相互の通信を高速にしたいときには、指定したPod同士をできるだけ近くにデプロイするという指定が可能。また、複数のPodを可能な限り異なるノードに分散してデプロイすることで全体の可用性を高めるといったことも可能になります。
「Taints/Tolerationons」は、ノードごとの指定で、このノードはこのチーム専用にする、あるいはこのノードはGPUを搭載しているからGPUを利用するワークロードに割り当てるといった指定が可能。
「Custom Schedulers」はデフォルトのスケジューラだけでなく、独自のスケジューラを併用したり置き換えることを可能にする機能です。
あわせて読みたい
ブロケードのイーサネット事業、Exterme Networksが買収へ。ブロードコムによるブロケード買収のあとで
≪前の記事
わずか2台のサーバでミニ・ハイパーコンバージドインフラ構成を実現。クロスケーブルで2台を直結、vSPhereとvSANを利用。Dell EMCから

