
Excelファイルを読み取って分析可能で、急激なデータ増加にも対応するクラウドDWH。高速化の秘密は列指向型、動的インメモリ処理など。IBM dashDB[PR]
クラウドの登場によって、大規模なデータ分析は以前よりもずっと身近なものになりました。高価なサーバやデータベースソフトウェアのインストールなどの手間をかけずとも、低コストですぐに利用を開始できるデータウェアハウス(DWH)やOLAPのサービスが、クラウドで提供されるようになったためです。
特に「マネージドサービス」と呼ばれる、クラウド側でデータのバックアップやソフトウェアのセキュリティパッチの適用、アップグレード、障害時の復旧などの運用まで行ってくれるクラウドサービスであれば、利用者は運用の手間にわずらわされることなくデータの分析に集中できるようになります。
IBMが同社のクラウドサービスであるBluemixで提供する「IBM dashDB for Analytics」(以下、IBM dashDB)も、そうしたマネージドサービスで提供され、手軽に大規模なデータ分析を実現してくれるクラウドDWHです。
dashDBは、データが増えてきてExcelや手もとのPCでは手に負えなくなってきたけれど、本格的なデータウェアハウスを構築するほどのコストはかけられない、といった規模のデータ分析を簡単に実現できます。そして万が一データが急激に増えたとしても、最大100テラバイトまで(データは圧縮されて格納されているため、実際には数百テラバイトまで)スケーラブルに対応できる高い性能を備えています。
Excelデータをアップロードすれば、すぐにデータ分析可能に
dashDBは非常に簡単に利用できます。BluemixのダッシュボードからdashDBを起動し、ExcelやCSVファイルでデータをアップロードしたら(既存のデータベースやクラウドなどからもデータをアップロード可能)、すぐにSQLやRなどで高速にデータ分析が可能です。
簡単に流れを見ていきましょう。まず、Bluemixのカタログから「dashDB」を選択。起動します。新規ユーザー登録をすると30日間は無償で実際に試すことができます(30日間を過ぎても1GBのデータ量を超えなければ無償で利用可能です)。
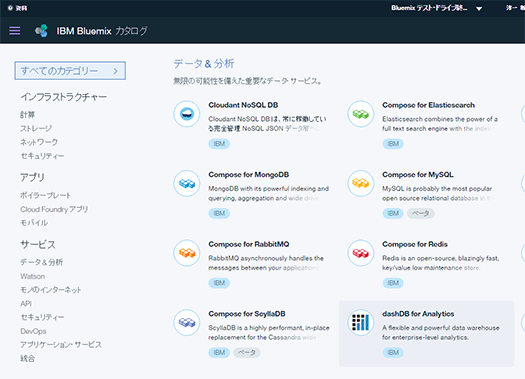
dashDBが起動したら、ダッシュボードから「Load Data」をクリック。
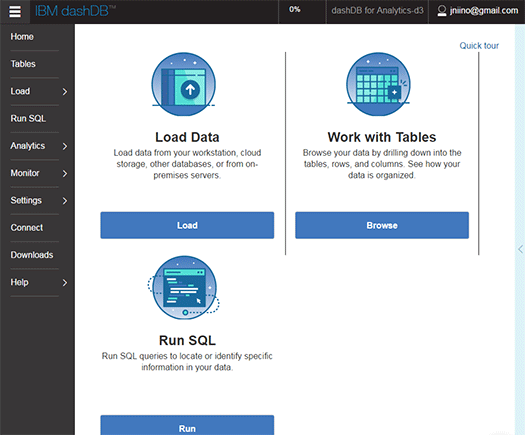
デスクトップからデータをアップロード。ここではExcelファイル形式(.xlsx)のPublickeyのログデータをアップロードしました。
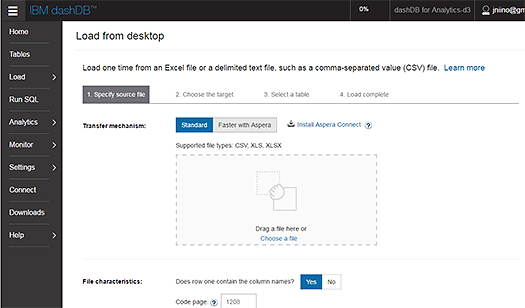
アップロードしたデータはすぐにプレビュー表示され、列名やデータ型などを設定します。ここではあらかじめデータの内容から列名やデータ型の候補が設定されていたため、変更する必要はありませんでした。
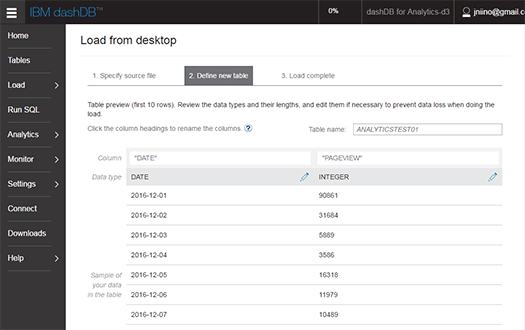
簡単なフィルタを作成して検索をすることも、SQL文による検索や集計もできます。
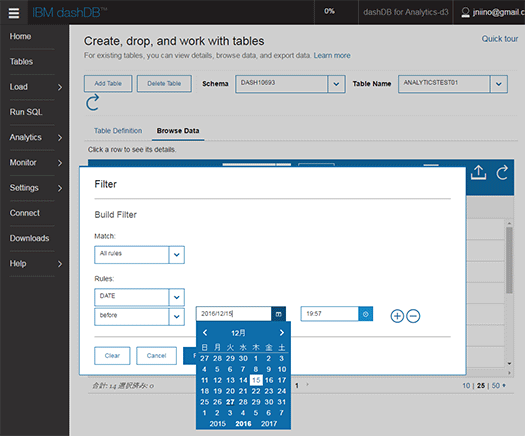
Rを使った高度な分析も可能です(下記の画面はIBMのデモから)。
列指向データベース、インメモリ処理、マルチコア対応などのDB高速技術
dashDBは数百テラバイトのデータを高速で分析することに最適化されたデータベースであり、内部にはさまざまな高速化技術が組み込まれています。
列指向データベースとデータスキッピング
そのひとつが列指向データベースです。一般的なデータベースでは、データが行ごとに格納されます。例えば「日付」「製品名」「販売価格」といったデータをまとめて「一行」とし、この行を単位としてデータを格納していく方法です。
一方dashDBでは、データを行ではなく列を単位に格納する「列指向データベース」を採用しています。これは、先ほどの例で言えば「日付」でデータをまとめる、列方向にデータをまとめて格納する方式です。
これには2つの利点があります。1つは圧縮が非常に簡単になると言うことです。列方向には基本的に日付なら日付、価格なら価格といった同じ型で似たようなデータが集まります。ですから圧縮効果が高いのです。
もう1つは検索や集計が高速になるという点です。列方向にデータがまとまっているため、例えば日付の列を高速にアクセスして検索できますし、価格の列を高速にアクセスして集計などができるのです。
dashDBではさらに、格納しているデータの一定件数ごとに、その一定件数内のデータの最大値と最小値を保持しています。こうすることで、検索時にその一定件数のブロック内に条件が合致するデータがあるかどうかがすぐに分かります。
例えば2017年1月1日以降のデータを集計する、という条件ならば、あるブロックのデータの最大値が2017年1月1日以前であればそのブロックには該当するデータは存在しないため、アクセスをスキップできます。これにより、さらに高速なデータ検索や集計が実現できるのです。
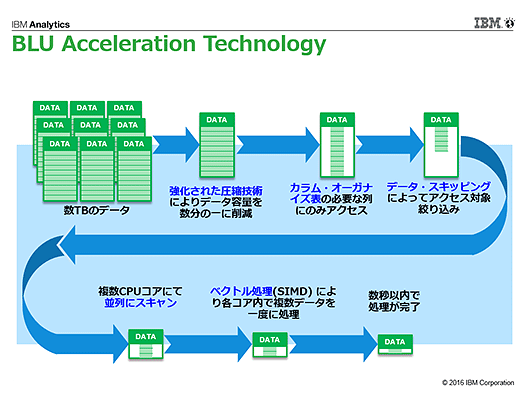 dashDBには処理を高速化するために「BLU Acceleration Technology」と呼ばれる多数のテクノロジーが搭載されている
dashDBには処理を高速化するために「BLU Acceleration Technology」と呼ばれる多数のテクノロジーが搭載されている並列スキャンとインメモリ処理
さらにdashDBではこうした検索や集計処理を複数のCPUコアで並列して実行できるため、データが増えた場合でもスケールアウトによって高速処理が可能。さらにプロセッサが備える並列処理のためのSIMD命令にも対応し、さらに高度な並列処理を実現。
しかもこれらの処理は使用頻度の高いデータを動的にメモリに展開して高速処理を実現するダイナミックなインメモリ処理のうえで実現されています。
またdashDBでは検索や集計だけでなく、分析処理までデータベース内部で行う「In-Database分析機能」を搭載しているため、シンプルなシステムで高度かつ高速な大規模データ分析を実現できるのです。
このようにdashDBは内部に高度な高速化技術を用いていますが、もちろん利用者がこれらを意識する必要はありません。ExcelファイルやCSVファイルをアップロードして簡単に高度かつ高速なデータ分析機能を誰でも利用でき、バックアップやメンテナンスの手間もかからないdashDBは、数あるクラウドデータベースのなかでも技術者でなくても使い始められるユニークなポジションのサービスだと言えるでしょう。
dashDBには、ほかにも「IBM dashDB Local」「IBM dashDB for Transactions」といったファミリー製品が用意され、プライベートクラウド環境で使いたい場合や、高速なトランザクション処理をクラウドで行いたい場合など、さまざまなデプロイメントやワークロードにも対応できるようになりました。ファミリー製品間では共通のテクノロジーが使用され、アプリケーションの移行も簡単とされています。将来のさまざまな可能性も考慮したときに、dashDBという選択肢はさらに魅力を増しそうです。
日本IBMでは、このdashDBのWebセミナーを無料で行っています。ご自身のオフィスからWeb経由でご試聴いただけます
現場のためのセルフサービス分析環境を支援/提供するIBM dashDBにフォーカスして、簡単な機能紹介や利用シーン、実際のデモンストレーションを交えて、「サービス作成~クエリー実行~データの投入~BIツール等との連携」をご紹介いたします。
- 2017年1月25日(水曜日)17時から17時45分まで
- 2017年2月15日(水曜日)17時から17時45分まで
- 2017年3月8日(水曜日)17時から17時45分まで
(本記事は日本IBM提供のタイアップ記事です)
あわせて読みたい
2020年までにデータサイエンティストの業務の4割は自動化される。そしてデータサイエンティストを本職としない「シチズンデータサイエンティスト」が台頭すると、ガートナー
≪前の記事
140年の歴史を持つ日本経済新聞社が、日経電子版アプリで内製化とアジャイル開発に挑戦した理由と現実、そして課題とは(後編)

