
クラウドの音声認識APIはライターの「文字起こし」に使えるか? ライターたちが実際のインタビューの録音データで評価してみた
ライターの仕事のなかでも手間がかかるのが、インタビューや講演などの録音データを聞きながら逐一正確に文字にしていく、いわゆる「文字起こし」と呼ばれる作業です。
この作業が高度化するクラウドの音声認識APIを使って自動化できたなら、どんなに楽か。多くのライターがそう夢見ていることでしょう。僕もそうです。
もちろんそれはライターの仕事だけでなく、会社の議事録や講演録などにも応用できるでしょうから、そのインパクトは非常に大きいものでしょう。
そこで、僕は現時点で音声認識APIは文字起こしの用途にどれだけ使えるのかを調べるため、クラウド関連の開発で有名な「ハンズラボ」さんと一緒に音声認識クラウドAPIを評価するプロジェクトを立ち上げました。
この経緯については9月27日の記事「クラウドの音声認識APIで、ライターにとって実用的な「文字起こしサービス」は作れるのか?」でも書きましたので、ご覧ください。
音声認識APIの評価方法
評価の対象とした音声認識APIは以下の3つです。
- Google Cloud Platform「Cloud Speech API」
- Microsoft Azure「Bing Speech API」
- IBM Watson「Speech to Text API」
これらのAPIに対して、ライターが実際の仕事としてICレコーダーなどで録音したインタビューや講演のデータを送り込み、どれだけ正確に文字起こしができているかを評価します。
そのためのアプリケーションも開発しました。
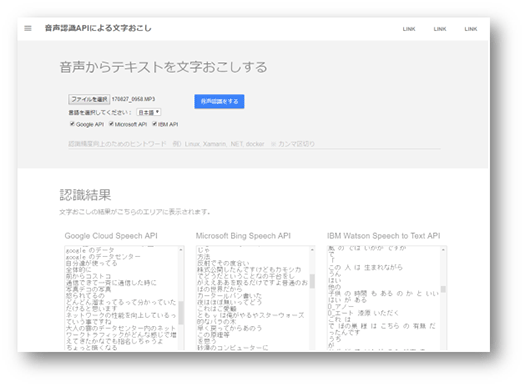
Webページから音声データをアップロードし、「音声認識を開始する」ボタンを押下すると、Google、Azure、Watsonの音声認識APIにそれぞれ音声データを送りこみ、結果をテキストフィールドに表示するというものです(このアプリケーションは現時点で非公開です)。
そして返ってきたテキストを見て、APIごとにざっくりと以下の5段階で評価することにしました。
1点:価値を全く感じない
2点:価値を感じないが可能性は感じる
3点:価値を感じる
4点:ある程度の実用性があり、利用が検討できる
5点:実用性があり、人間が書き起こしたものと区別がつかない
現実には、まだ「文字起こし」の実用には遠い
そして11月、東新宿にあるハンズラボさんの会議室にライター有志が集まって実際に仕事で使った録音データを持ちより、音声認識APIがどれだけ実用的なのかを評価しました。
結論から言うと、音声認識APIの能力は、インタビューの録音データなどを対象にした「文字起こしツールとして」は実用的に使えるレベルにはほど遠く、期待したレベルには達していない、というものでした。
各APIともに、話者が丁寧にしゃべった音声を、口元のマイクで明瞭に捉えた音声データならば、ほぼ実用的な文字起こし結果が得られることは分かっていました。
これは以前から、Google Docsの音声入力機能でマイクを使って話しかけることで、それなりに実用性のあるテキストが生成されるといったことはライターのあいだでも知られていたテクニックだったため、十分予想できたことでした。
正直なところ、Google Docsの音声入力がそこそこ使えていたので、マイク入力の代わりにインタビューの録音データをAPIに流し込んでやれば、そこそこ実用的な文字起こしがすぐにでもできるのではないかと、当初は期待していました。
ところが、実際に各APIにデータを送り込んでみると、その結果は予想を裏切って、よく分からない日本語テキストばかりが返ってきましたのです。
以下が、ライター6人による13種類のインタビューや講演の録音データを用いて評価した各APIの平均点です。
Cloud Speech API:1.9点
Bing Speech API:1.7点
Speech to Text API:1.2点
出力結果の一部には、実用になるのではないかという可能性を感じさせるところもありました。しかし全体としては、出力されるテキストにほとんど価値を感じず実用性もないというのが、ライターが文字起こしに使う録音データを用いた音声認識APIの能力の現状ということです。
実際に出力されたテキストの例をいくつか紹介しましょう。あえてちょっと面白いところを抜き出しましたが、出力されるテキストの雰囲気はつかんでいただけるのではないかと思います。
喫茶店で録音されたため周辺ノイズが多いインタビュー音声の認識結果の一部。
仮面女子活動
入力してくださとじゃないです正直なところ1大聖堂
(もちろん仮面女子の話はしていません)
会議室で複数人に対するインタビューの認識結果の一部。
ふたりエッチ
教えてくれるんですごく助かったので後黒枠問題男女何
(もちろんインタビュー内容はITやビジネスに関するものなので、「ふたりエッチ」の話はしていません:-)
上記とほぼ同じ個所の別の音声認識APIでの認識結果。
二人 で 面白い です ね 出られ
ご意見 だけ 口 に する のも
ちなみに、13種類の録音データは、iPhoneやさまざまなメーカーのICレコーダーを用いて録音されました。録音場所は、会議室や講堂、カフェテリアなどがあり、ICレコーダーを机に置いたりスピーカーの前に置いたりと状況もさまざまです。
話者も、男性、女性、早口な人、超早口な人、ゆっくりしゃべる人などさまざまでした。
なぜ実用には遠い結果になったのか?
なぜこういう残念な結果になったのか。本当のところは音声認識APIの開発者でないかぎり分かりませんが、何種類ものデータで試した結果からその原因を考察したうえで、それをどう改善していくかについても考えてみます。
まず、音声認識APIにとって理想的な音声というのは前述の通り、1)音声を口元のマイクで明瞭にとらえ、2)話者が丁寧にしゃべる、という2つの条件が揃ったものだと考えられます。
ところが、ライターがインタビューをICレコーダーで録音するような状況では、この2つの条件ともに揃いません。
まず、1)ICレコーダーは話者の口元から遠く机の上などに置かれ、さらに会議室なら部屋の影響によるエコーやキーボードをたたく音などのノイズも入ります。
そして、2)話者はおおむね日常会話と同じペースで、ときに早口で、ときいに言いよどみつつしゃべります。
人間がこの2つの条件がともに悪いときでもちゃんと聞き取れるのは、おそらく周辺のノイズについてはいわゆる「カクテルパーティ効果」による話者への集中によってマスクでき、話者の早口だったりする口調に対してはおそらく文脈を読み取って不明瞭な単語を聞き手が勝手に頭の中で補完しているからだろうと思います。
しかし機械学習APIにはカクテルパーティ効果も文脈による補完もないのでしょう。こうした悪条件によって一気に認識率が落ちてしまうのです。
参考記事
機械学習APIについて。マイクロソフトは、Windows 10に機械学習専用のAPI「Windows ML」を搭載すると明らかにしました。
音声が明瞭でないことの影響が大きい
いくつかの音声データを評価して分かったのは、特に話者の音声が明瞭かどうかが、認識率にもっとも影響を与えている、という点です。
要するにマイクが口元に近くあって明瞭に音声をとらえつつ、周辺ノイズなどが少ないと、認識率が明確に向上するのです。
また、インタビューの現場の現実を見ても、話者に丁寧にしゃべってもらうというコントロールをすることは事実上無理です。
ですので、音声認識APIのユーザー側で認識率を向上させることができるとすれば、いかに明瞭な音声の録音データを用意するか、にかかっていると言えます。
おそらくこれは、音声認識APIの内部で行われているおもな処理が、音声の波形と日本語文字のマッチングによって行われているからではないかと想像しています。
音声認識APIの内部処理として、音声データの波形を見て、その波形に近い日本語テキストを出力することで、音声をテキストに変換しているのであれば、ノイズや音声そのものの不明瞭さによって波形の比較は難しくなります。
前述の出力結果に「仮面女子活動」とか「ふたりエッチ」のような、まるで文脈を無視した単語が唐突に表れるのも、波形を見て、それに似た波形でよく登場する単語を単純にマッチさせた結果だからではないか、と推測できるわけです。
明瞭な音声を得るためのアプローチ
ではどうやって明瞭な音声データを音声認識APIに渡すことができるか。まず、以下の2つのアプローチが考えられます。
デジタル加工アプローチ
ICレコーダーで録音した音声データを何らかの方法でノイズを取り除き音声を明瞭に持ち上げるデジタル加工を施す。現時点の評価用アプリでも音声帯域の周波数帯をフィルターしているが、より高度なデジタル処理を行う。
録音時のアプローチ
これまでのICレコーダーを机の上に置くのではなく、マイクをきちんとセットして録音する。
デジタル加工アプローチは、いまのところなにをどうすればうまくいくのかよく分かっていませんし、明らかに技術的なハードルも高いでしょうから、これはハンズラボさんのエンジニアの方々と相談して検討することになります。
録音時のアプローチは、現場で実現可能な範囲でどこまで改善可能なのか、また講演などの場合はラインから音声をもらえるのか、といったことを、これから模索していきたいと思っています。
また、流行のスマートスピーカーのように複数のマイクを埋め込んだデバイスを使って、ノイズを提言しつつ音声を明瞭化しつつ録音するような、ハードとソフトを組み合わせたアプローチも検討する価値があるかもしれません。
音声認識APIの改善アプローチ
そして最後にもうひとつ、音声認識API側がもっと賢くなって認識率が高まることを期待するアプローチがあります。
なにしろ画像認識、顔認識、手書き文字認識などの分野で、機械学習を用いたテクノロジーは人間に肉薄し、あるいは人間を上回りつつあります。
音声認識においても、例え録音状況が多少悪くとも人間が問題なく文字起こしできるレベルの録音データならば、人間と同等くらいのテキストを生成してくれるくらいに進化してくれてもおかしくないでしょう。
また、11月末には後Amazon Web Serviceからも音声認識APIの「Amazon Transcribe」が発表されました。日本語に対応し次第、このAPIも評価してみるつもりです。
アドバンスト・メディアのAmiVoiceなど国内ベンダで入手可能な製品やサービスなども未評価なので、時間と手間について考慮しつつもこうした製品も評価したいところです。
では、こうした進化が訪れるまで僕たちは待つことしかできないのでしょうか。
音声認識APIの能力向上を支援できるか
いや、僕たちの手で音声認識APIの能力向上を促進できないだろうか、とも考えています。
というのも、これまでの評価の課程で、どうやら日本語より英語の方が認識率がずいぶん高そうだと感じています。それはたぶん学習量の違いではないでしょうか。
だとすると、日本語でもいろんな環境でのいろんな話者の音声をもっともっと音声認識APIに学習してもらえれば、悪条件での認識率が向上することが期待できるのではないでしょうか。
ではその学習に必要なのはなにかといえば、音声データと、それを忠実にテキストに起こした正解データです。
僕たちライターはそうした学習に用いられるデータを提供しうる立場にあります。ただ、音声が忠実にテキストになっているかというと微妙なところはあるので、既存のデータがそのまま使えるかどうかという課題はありますが、とはいえ、その気になればライターのひとたちは、こうした学習データを豊富に提供しうる立場にいることは間違いないでしょう。
そうしたデータを提供することで、悪条件下にある音声データであっても、高い認識率を実現できるように学習してもらえるのであれば、協力したいライターは多いのではないかと考えています。
ただ、そうした学習データを本当に音声認識API側が求めているのかどうかは、ベンダ側に聞いてみなければなりません。もしかしたら、ノイズ入りの音声データは学習データにしたくないと考えているかもしれません。そのあたりの事情はよく分からないので、相談してみる必要はあるでしょう。
そして、もしそうした音声データが学習に役立つのであれば、ライターに呼びかけて、学習データをできるだけたくさん集めることで、日本語における音声認識APIの能力向上に役立てることができると思います。
音声認識APIの能力向上は、ライターのみならず、たくさんの人たちのビジネスや生活を便利にしてくれるはずです。
今後のアクション
というわけで、文字起こしを自動化するという楽をするために、まだまだ苦労しなくてはならないようです。
今後は前述のように、デジタル的なアプローチ、録音側のアプローチ、そして音声認識APIの能力向上のアプローチをそれぞれ検討しつつアクションしていくつもりです。
また随時経過報告などもしていくつもりです。最後になりましたが、このプロジェクトにご協力いただいているハンズラボさん、ライターの皆さんに感謝します。今後ともよろしくお願いします。
参考記事
音声認識APIは文字起こしの用途にどれだけ使えるのかを調べるため、音声認識クラウドAPIを評価するプロジェクトを立ち上げました。
Amazon Web Services(AWS)は、米ラスベガスで開催中の年次イベント「AWS re:Invent 2017」で、音声認識サービス「Amazon Transcribe」を発表しました。
あわせて読みたい
GitHubによる2018年の予想。データがすべて、ワークフローの戦い、OSSは上位レイヤへ、など
≪前の記事
サーバレスコンピューティング、もっとも利用されているのはAWS Lambdaで70%、Google Cloud Functionsが13%。CNCF調査

