
[速報]「Amazon Redshift Spectrum」発表。Amazon S3にデータを保存したまま複雑なクエリを高速で実行可能に。AWS Summit 2017 San Francisco
2017年4月20日
Amazon Web Servicesは、サンフランシスコでイベント「AWS Summit 2017 San Francisco」を開催。データウェアハウスの新サービス「Amazon Redshift Spectrum」を発表しました。
Amazon S3にデータを保存したままデータウェアハウスで分析可能
Amazon.com CTOのWerner Vogels氏。
多くの顧客で、ペタバイトから多い場合にはエクサバイトクラスの生データがAmazon S3に保存されており、これをAmazon Redshiftへ取り込むのは時間やコストの制約で難しいと考えられていると。

そこで「Amazon Redshift Spectrum」が発表されました。
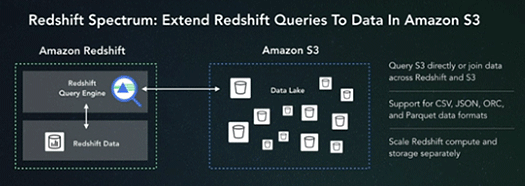
Redshift Spectrumは、複雑なデータウェアハウスのクエリをAmazon S3に保存されているデータへ直接投げられるというもの。

Amazon Redshiftでクエリを組み立ててS3のデータを指定し、実行できます。データ形式はCSVやJSON、ORCなどに対応し、GZipなどで圧縮されたデータにも対応。
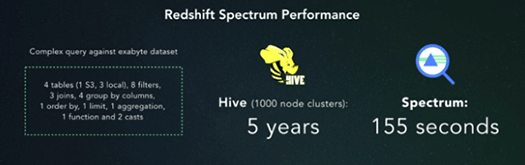
性能について。エクサバイトデータに対してジョイン、グループバイ、オーダーバイなどが含まれた複雑なクエリの実行を想定すると、1000ノードのHiveでは5年かかる一方、Redshift Spectrumでは155秒で完了すると説明されました。
「これによってDatalakeをAmazon S3に作ったうえで、複雑なクエリを実行することができるようになるのだ」(Werner Vogels氏)。
すでに何社かはRedshift Spectrumを利用しているとのことです。

あわせて読みたい
≫次の記事
Dockerが「Moby Project」を発表。すべてをコンテナで組み立てる世界を目指す。DockerCon 2017
≪前の記事
[速報]オラクル、Docker StoreでOracle DatabaseやWebLogicなどのオフィシャルイメージを配布開始。開発やテスト用途は無料で利用可能。DockerCon 2017
Dockerが「Moby Project」を発表。すべてをコンテナで組み立てる世界を目指す。DockerCon 2017
≪前の記事
[速報]オラクル、Docker StoreでOracle DatabaseやWebLogicなどのオフィシャルイメージを配布開始。開発やテスト用途は無料で利用可能。DockerCon 2017

