
Yahoo! JapanのHadoopクラスタは6000ノードで120PB。指数関数的に増大するデータ需要を技術で解決していく。Hadoop Spark Conference Japan 2016
日本を代表する規模のビッグデータ処理基盤を持つ企業の1つがYahoo! Japan(以下Yahoo!)です。
同社は2月8日に開催された「Hadooop Spark Conference Japan 2016」において、現在運用中のビッグデータ処理基盤の規模、そして同社が抱えている課題と、それをどう解決していくのかを基調講演の中で示しました。
同社が示した解決方法は、Hadoopなどのビッグデータ処理基盤を使い倒す側から、作る側へ向かうという大胆なものです。同社の貢献はオープンソースとなり、今後さらに多くの課題解決に役立つことになりそうです。
同社データインフラ本部 遠藤禎士(えんどうただし)氏のセッションをダイジェストでまとめました。
Yahoo!はマルチビッグデータカンパニー
Yahoo! Japan データインフラ本部 遠藤禎士(えんどうただし)氏(写真左)。

現在Yahoo! Japan(以下Yahoo!)は100以上のサービスを提供し、月間649億ページビュー、1秒間に5万アクセスの規模のマルチビッグデータカンパニーです。

ビッグデータ基盤の全体像として、HadoopのうえにRDB、DWH、オブジェクトストア、KVS(キーバリューストア)が乗っている構造になっています。
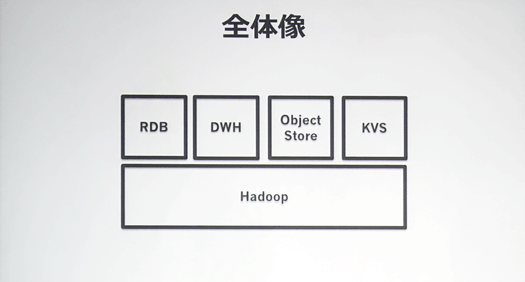
Hadoopクラスタは6000ノード、120ペタバイトのデータを保持。

その上のサブシステムは以下のようになっています。
- RDBはMySQL(Percona)のデータベースが560個、Oracleのデータベースが200個。
- DWHにはTeradetaを利用し、43ノードで1.7ペタバイト、1日平均30万クエリを処理。
- オブジェクトストレージは同社のプロプライエタリなもので、1500ノード以上あり10ペタバイト以上のデータを保持。1カ月あたりのギガバイト単価は2円
- KVSはCassandraで2000ノード、1秒あたり15万リクエストを処理
いま取り組んでいるのがこの図に示されたものです。
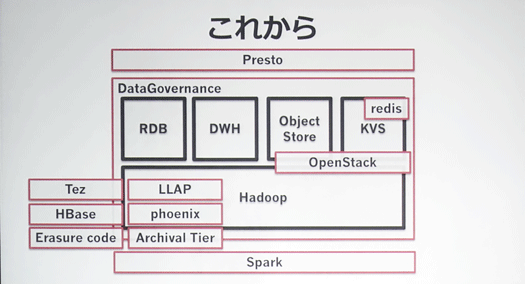
今日はHadoopまわりにフォーカスします(図左下)。
Tezの導入が本格化しており、LLAPの開発も進めており、HBaseは現在検証中、Erasure code、Archival Tierなどにも取り組んでいます。
Sparkはサイエンス部隊で検索データのグラフデータ化に試験的に取り組んでいます。
データ需要の増大を、コストではなく技術で解決する
次はこれからのHadoopまわりについて。
課題はデータ需要の指数関数的増大です。データ容量が1年で4倍、指数関数的に増大しています。コストも急増しており、新規に追加した3000台のクラスタリソースがわずか8カ月で使い切られてしまいました。
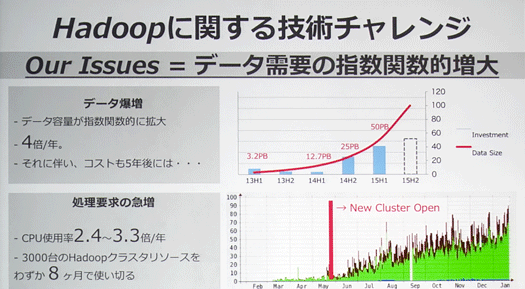
こうした需要の増大をコストではなく技術で解決するのがわれわれの課題です。
広告レポートの事例を紹介すると、このシステムでは、2つの要件があります。過去13カ月で4000億行ある巨大データで、しかも毎日13億行が追加されるデータを扱えること。そしてこれを1時間で10万クエリの性能で処理する要件がありました。
広告事業は私たちの主要な事業ですので、このビジネスが成長すればこのシステムも成長が求められます。
当初、構築したシステムは1時間あたり1万クエリしか処理できませんでした。ここから処理性能の向上を目指して以下のことを行いました。
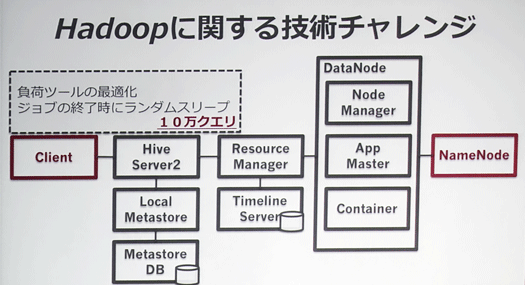
- Metastoreにはいろんなモードがあるので、RemoteからLocalへ変更。これで2万クエリ/時
- Resource Managerでは、App Masterのリソースを有効活用できていなかったのでランチャーマスターのスレッド数を引き上げ。するとハートビートが混雑してきたのでハートビート間隔を長く。これで4万クエリ/時
- DataNodeでは他ノードのコンテナを再利用にし、直近のデータのレプリケーション数を増やすことで性能向上。これで8万クエリ/時
- クライアントでは同時クエリ数を最適化。ジョブ終了処理が集中発生しないようにランダムスリープを入れた。これで10万クエリ/時
こうしたことで1時間あたりの10万クエリを実現しました。
使う側から作る側へ回ることで、データ需要への根本的な解決を
いままでYahoo!はソフトウェアを使い倒すことで大規模なデータ処理に対応してきましたが、増大するデータの処理要求はとどまることを知りません。つねに後手後手にまわってきました。
われわれが直面している問題を解決するには、USEからMAKEへ。作る側に回ることでこの問題を根本的に解決しようとしています。

昨年、Hortonworksとパートナーシップを結び、徐々に作る側に回っています。そうして世の中にも貢献していきたいと思っています。
Hadoop Spark Conference Japan 2016
あわせて読みたい
Docker Cloud 1.0登場へ。買収したTutumをリブランドしDocker Hub と統合
≪前の記事
Spark 2.0はフロントエンドAPIの創設と10倍の性能向上を目指す。早くも今年の5月頃登場予定。Hadoop Spark Conference Japan 2016

