
GoogleのBigQuery、標準のSQL構文(SQL 2011)対応。期間でテーブルを分けるタイムベースパーティショニングも可能に
2016年6月6日
Googleは大容量データに対する検索を高速に実行できるクラウドサービス「BigQuery」で、標準的なSQL構文などの新機能が利用可能になったと発表しました。
BigQueryは、大容量のデータをカラム型のデータ配置や並列分散処理などによって、高速な検索や連結を可能にしています。
これまでBigQueryはSQLに似た構文を用いていましたが、最新版となるBigQuery 1.11から、標準的なSQL構文(SQL 2011)にベータ版として対応しました。
内部動作のオプティマイゼーションを改善し、複雑な副問い合わせなどが記述可能になり、日付、時間、配列、構造体などの型にも対応。シータジョイン(θジョイン)と呼ばれる拡張された連結にも対応したとのことです。
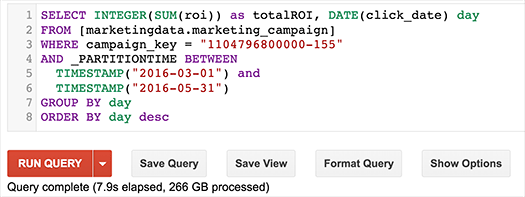
また、期間ごとにテーブルを自動的に分割するパーティショニング(Time based table partitioning)も実現。データをロードするときに自動的にBigQuery側で期間ごとに分けたテーブルを作成してくれます。
こうすることで、特定の期間に対する検索をする場合に、そのパーティションしかスキャンしないため、処理速度が向上。もちろん次のように複数の期間にまたがった検索も可能です(「BigQuery 1.11, now with Standard SQL, IAM, and partitioned tables! | Google Cloud Big Data and Machine Learning Blog | Google Cloud Platform」から引用)。
また、BigQuery 1.11ではユーザーのロールやアクセス制御を中枢して管理できる「Cloud IAM」にも対応しました。
あわせて読みたい
≫次の記事
Amazon Aurora、地域をまたがったリードレプリカが可能に。ある地域で災害が起きても、別の地域のレプリカがマスターに昇格
≪前の記事
CoreOS、コンテナに最適化した分散ストレージ「Torus」を発表
Amazon Aurora、地域をまたがったリードレプリカが可能に。ある地域で災害が起きても、別の地域のレプリカがマスターに昇格
≪前の記事
CoreOS、コンテナに最適化した分散ストレージ「Torus」を発表

