
GoogleがClouderaらと共同で「Google Cloud Dataflow」のオープンソース化提案。Apache Incubatorプロジェクトとして
Googleがクラウドで提供している「Google Cloud Dataflow」は、エクサバイトスケールもの大規模なデータ処理に対応したフルマネージドのサービス。
最大の特徴は、リアルタイム処理とバッチ処理のどちらも同一のプログラミングモデルを採用していることで、開発が容易になっている点にあります。
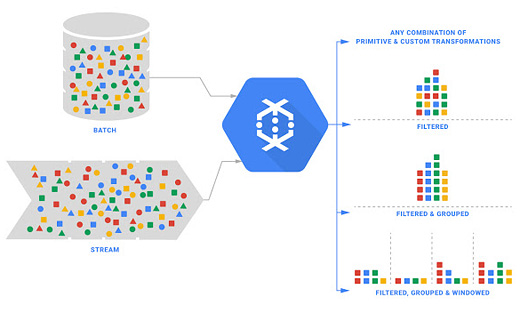 昨年8月に正式サービス化が発表されたときの資料から。左側のバッチ処理、ストリーミング処理がどちらでもDataflowが対応できることを示している
昨年8月に正式サービス化が発表されたときの資料から。左側のバッチ処理、ストリーミング処理がどちらでもDataflowが対応できることを示している このGoogle Cloud Dataflowのソースコードを、Apache Software FoundationのIncubatorプロジェクトとして提供する提案を、GoogleがCloudera、data Artisans、Talend、Caskらと共同で行っていることが発表されました。
Dataflowを用いることで、Dataflowという1つのプログラミングモデルでApache SparkやApache Flinkなど複数の処理基盤に対応し、しかもバッチとストリーミングの両方にも対応した処理が書けるというメリットが生まれるとのことです。
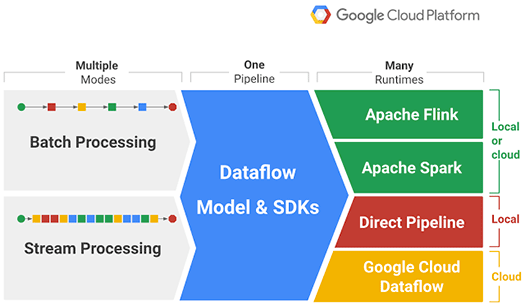
With Dataflow, you can write one portable data pipeline, which can be used for either batch or stream, and executed in a number of runtimes including Flink, Spark, Google Cloud Dataflow or the local direct pipeline.
Dataflowによって、1つのポータブルなパイプラインを書くことができる。それはバッチとストリームのどちらの処理にも使え、さらにFlink、Spark、Google Cloud Dataflowやローカルなパイプラインなどの多数のランタイムで実行できる。
「Dataflow and open source - proposal to join the Apache Incubator」から引用
これにより以下のメリットがあると説明されています
Pipeline first, runtime second
DataflowモデルとSDKにより、何で実行するかではなくデータパイプラインの定義にフォーカスできる
Portability
データパイプラインはさまざまな実行エンジンに対してポータブルであり、実行エンジンを性能やスケーラビリティなどから選択できる
Unified model
バッチとストリーミングが、ウィンドウイング、オーダリング、トリガリングなどを含む1つの強力なセマンティックを持つモデルで統合されている
Development tooling
Dataflow SDKにはポータブルなデータパイプラインを迅速かつ容易に開発できるオープンソースの言語、ライブラリ、ツールなどが含まれている(訳注:Dataflow SDKはすでにGoogleがオープンソース化済み)
Apache Software Foundationへの提案は「DataflowProposal」として公開されています。
あわせて読みたい
マイクロソフト、Node.jsのJSエンジンとして同社のChakraCoreも使えるように、Node.jsのメインラインにプルリクエストを投げたと表明
≪前の記事
開発者や企業が自由に製品を発表できるクラウド上のマーケットプレース「エコアライアンス」、IDCフロンティアが発表

