
NTTデータとPostgreSQLが挑んだ総力戦。PostgreSQLを極限まで使い切ったその先に見たものとは?(前編) NTTデータオープンソースDAY2015
現在のシステム構築では、オープンソースのソフトウェアを使うことは当たり前になってきています。PostgreSQLはそうした中で主にエンタープライズ向けのデータベースとして着実に事例を増やしてきています。
その中で、PostgreSQLを大規模なミッションクリティカルなシステムの中で使うには、どのようなノウハウが求められるのか。オープンソースの利用に積極的なNTTデータがその事例を、1月26日に開催されたイベント「NTTデータオープンソースDAY 2015」のセッション「NTTデータとPostgreSQLが挑んだ総力戦。PostgreSQLを極限まで使い切ったその先に見たものとは?」で紹介しています。講演内容をダイジェストにしました。
PostgreSQLでシビアな条件に立ち向かう
NTTデータ 基盤システム事業本部 澤田雅彦氏。
2012年入社以来、PostgreSQLの研究開発、技術支援に従事してきました。
大規模システムでも当たり前にPostgreSQLを使う現在でも、シビアな条件で使おうとするとまだまだ課題があります。そこで、そのような事例でPostgreSQLを使う際にどのような対策をしてきたのか、お話していきたいと思います。

PostgreSQLは、コミュニティが主体となって継続的に開発、保守されているRDBMSです。
進化のトレンドとしては、レプリケーションという大きな機能が入ったのがバージョン8から9にかけて。9.1では同期レプリケーションが入ってさらに高可用な方向に進化。9.2、9.3ではインデックススキャンの強化や、フェイルオーバーの高速化、最新版ではNoSQL機能の強化でスキーマレスのデータベースとしても使えるようになってきています。
このようにエンタープライズへの適応に向けて新機能の追加や性能改善が行われていて、同時に事例も年々大規模になってきています。近年では海外の政府、金融系、クラウドのネットワーク機能のバックエンドなど大規模システムでも使われるようになりました。
現在ではNTTデータも、PostgreSQLを大規模システムでも当たり前に使うようになりました。しかし、当たり前の使い方では太刀打ちできない要件が立ちはだかりました。
世界有数のエネルギー元売り会社の情報系システムです。
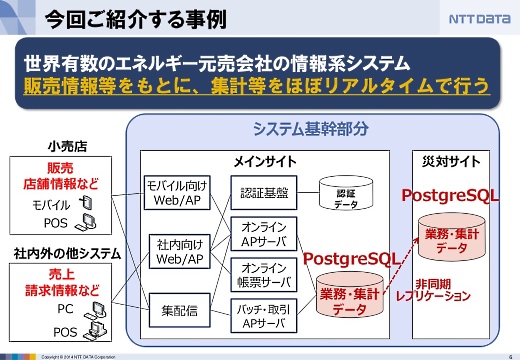
フロントエンドにはモバイルデバイスやPOS、PCなどがあります。ここから送られてくる情報を元に集計などをほぼリアルタイムに行います。システムが落ちると社会的な影響が大きいので、災害対策サイトへディザスタリカバリをしていて、情報系とはいえミッションクリティカル性の高いシステムです。
開発体制も1000人体制で、データベースは約10テラバイト、SQL文が約2万本、データベースへのアクセスは200TPS以上です。
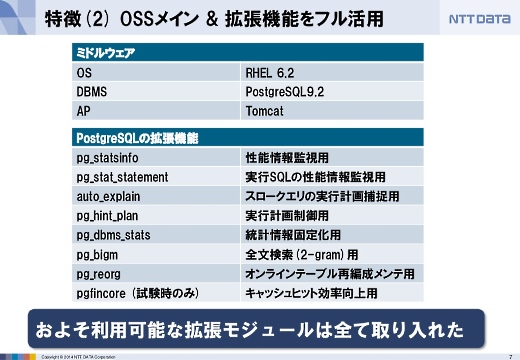
このシステムをRed Hat Enterprise Linux 6.2、PostgreSQL 9.2、Tomcatなどオープンソースをメインに用いて構築しました。
また、PostgreSQLは拡張機能が豊富なのが特長の1つですが、よく使われている拡張機能はほぼ全て取り入れるというチャレンジングなシステムです。これだけの拡張モジュールを入れてPostgreSQLのポテンシャルを引き出さなければいけないぐらい、シビアな要件だったということです。
この開発の中での5つの課題のうち、3つのトピックについて紹介したいと思います。
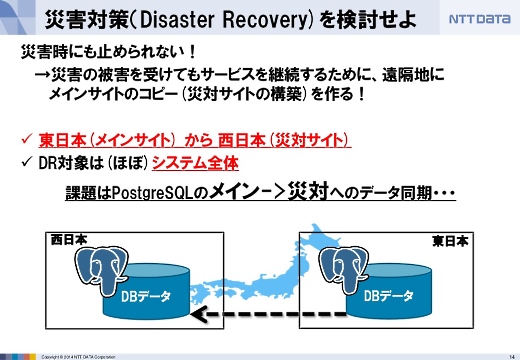
東日本と西日本のあいだでディザスタリカバリを実現
1つ目は、いかにしてディザスタリカバリを実現したかです。
災害時にも止められないようなミッションクリティカルなシステムなので、万が一のときにも災害対策サイトで動き続けるように、システム全体を対象として東日本と西日本のあいだでディザスタリカバリをするようにしました。
このとき、データベースのデータをどのようにメインのシステムから災害対策サイトへ同期させるかがいちばんの課題でした。
今回はPostgreSQLに標準で入っている非同期レプリケーション機能にあたる、Streaming Replicationを選びました。標準機能なので運用が楽なのと、さらに弊社のFujii MasaoがこのStreaming Replicationの主要な開発者の1人だったので、なにかトラブルがあったとしても根本解決がしやすいというのが後押しになりまいた。
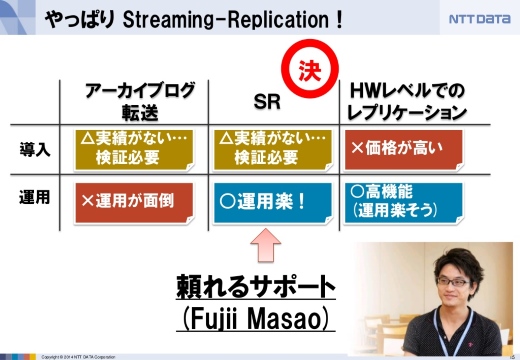
ただ、これほど大規模なデータベースの長距離でのレプリケーションをディザスタリカバリ用途に使ったことはなかったので、いろんな検証をしました。例えばネットワークのサイジングや同期方法などです。
マスター側の転送負荷や送るデータ量など、ひとつひとつ検証して本当に使えるかを検証しました。
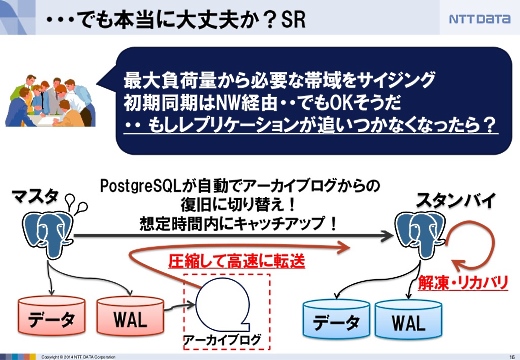
その結果、十分実用的だということが分かりました。

SQL文のトラブルを5つの関門で解決
次は開発の時のエピソードです。
このシステムの開発規模は約1000人ですが、データベースエンジニアは数名しかいませんでした。この数名で2万本ものSQL文の性能をどう守ったか。
アプリケーション開発者が複雑すぎるSQL文を書いてしまうと、メンテナンス性や可読性が落ちて、トラブルや性能低下があったときに対策が難しくなります。ですので、そうした問題のあるSQL文は撲滅しなければなりません。

そこでSQL文に5つの関門を設けました。
1つ目は「SQLガイドライン」です。まずSQLのメンテナンス性を確保し、そこにPostgreSQLのノウハウを付加しました。
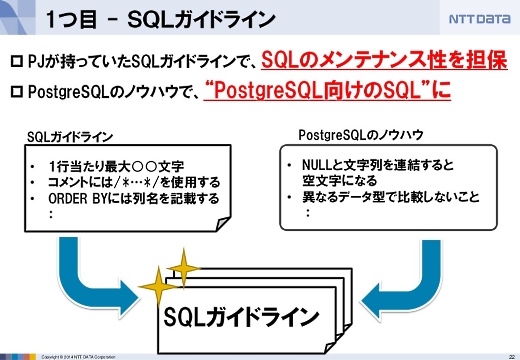
それでもSQL文を書くのは人なのでガイドラインを外れることがあります。そこで2つ目の「SQLチェックツール」で自動的にチェックする仕組みを作りました。SQLのシンタックスレベルでチェックしました。
これが通ったSQLは、シンタックス的には問題のないSQLということになります。

≫後編に続く。後編では、実行計画のチェックの実現方法、本番直前に起きたセグメンテーションフォルトの原因追及などについて。
あわせて読みたい
NTTデータとPostgreSQLが挑んだ総力戦。PostgreSQLを極限まで使い切ったその先に見たものとは?(後編) NTTデータオープンソースDAY2015
≪前の記事
2014年第4四半期、Amazonクラウドのシェアは28%で年50%成長、続くマイクロソフトはシェア約10%ながら年96%成長で猛追中。Synergy Research Group

