
Hadoopによる分散システムの構築と運用の落とし穴。ClouderaとCiscoのエバンジェリストが語る[PR]
データを分析することで得られるさまざまな知見は、企業の製品開発、製造、マーケティング、営業などのあらゆる分野でこれから大きな変革をもたらすと考えられています。
そうした大規模データの処理基盤として存在感を高めているのがHadoopです。しかしHadoopのような大規模分散システムの構築や運用は容易ではありません。そこにどんな課題があり、解決策があるのでしょうか。
シスコシステムズとClouderaが8月に共同開催したイベント「実際動いているIoT&Hadoopから学ぶ会」から、Hadoopによる分散システムの落とし穴とソリューションについて紹介しましょう。
ひとつのプラットフォームにすべてのデータを集める

いま注目されているビッグデータは、従来のように顧客や商品、売上などの基本的なデータが大量に集まるだけでなく、例えば製造業や金融や医療などの業種ごとに、Webサイトのログ、ソーシャルネットワーク、モバイルデバイスやセンサーなどからの地理的情報や稼働情報、画像、音声、動画など多種多様にわたっています。
そしてそれを分析して有意義な知見を得るには、複数のデータソースを横断的に分析することが求められます。
こうした多様かつ大量のデータの保存や横断的な解析は、従来のデータ分析で主に用いられていたリレーショナルデータベースでは困難です。
「そこでわれわれは『エンタープライズデータハブ』という新しい基盤を提唱します」と、Clouderaのテクニカルエバンジェリスト 嶋内翔氏。

エンタープライズデータハブとは、ひとつのプラットフォームにすべてのデータを集めて、ひとつのプラットフォームで処理するという考え方でできています。Hadoopをベースにした、データの種類を選ばず統合マルチフレームワークアクセスが可能なデータ基盤です。既存のデータベースを置き換えるのではなく、データベースやデータウェアハウスを残しつつ、そこに加えていくものとされています。
エンタープライズデータハブの利点は「非常に安価なコストでデータを1カ所に統合し、分析できる点」(嶋内氏)。これをいまあるデータベースやパートナーのソリューションと組み合わせることで、さまざまな形のビッグデータ処理基盤を実現することができるのです。
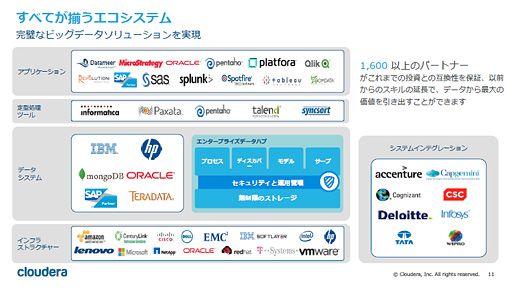
実際に、このエンタープライズデータハブは証券会社のJPMorganChaseにおいて大量の金融商品のヒストリカルデータ分析によるリスクモデリングや、保険会社Allstateにおいてパーソナライズされた保険契約といった事例で使われ始めています。
アーキテクチャ設計に落とし穴がある
エンタープライズデータハブ、あるいはHadoopを本番環境として構築し運用する上で、気をつけるべきいくつかの落とし穴があると嶋内氏は指摘します。
1つはサービスレベルをどう定めるか。ある処理を10秒以内で実現すべきか、5秒以内で実現すべきかといったサービスレベルの設定はシステムのコストに直接影響するため、本当にそのサービスレベルが必要なのかどうかを慎重に考える必要があります。
そしてアーキテクチャ設計。ストレージ層のファイルフォーマットやスキーマなどの選択によって読み書きの性能とデータの圧縮率が決まり、データが増えてからの変更は時間もコストもかかるため、設計時に十分考える必要があります。
またオンプレミスで構築するかクラウドを利用するかの選択もあります。性能の面ではクラウドよりもオンプレミスの方が一般的には有利ですが、最近はクラウドでもストレージにSSDが選択できるなど性能面での改善も進んでいます。そのため初期投資を抑えるためにクラウドでスタートすることも重要な選択肢である一方、ネットワークの面で大量のデータ投入が大変な面があります。

「いずれにせよ間違ったアーキテクチャ設計は無駄なコスト、性能や安定性の低下など多くの問題を引き起こしますので、ここは慎重に設計する必要があるでしょう」(嶋内氏)
また必要なストレージ容量の見積もりも「私の経験上、100%はずれます。しかも上の方に。どのお客様とお話ししても例外なく起きています」(嶋内氏)。Hadoopのシステムを構築し運用がうまく行き始めると、その評判を聞きつけて社内のデータがさらにどんどん集まってくることになるというのです。
そのため、長期的な計画よりも3カ月ごとにどれだけ増えるかを予想するなど、柔軟な計画が望ましいと嶋内氏は指摘します。
優秀なスタッフが引き抜かれてしまったら?
設計時だけでなく、もちろん運用時にも落とし穴はあると嶋内氏。
ひとつはHadoopなどシステムのバージョンアップを行う場合。すでに業務の中にHadoopやエンタープライズデータハブによるデータの収集と分析が組み込まれていると、バージョンアップのときにそれを止めることが難しくなってきます。
その解決策として、例えば分散メッセージキューのKafkaを用いて入力されてくるストリームデータの流入を維持しつつ、アップグレードするなどの手段を考えなければなりません。
また、Hadoopは比較的難しいシステムであるため、それを理解している優秀なスタッフは多方面から引っ張りだこです。社外からよい条件が提示されて転職してしまう可能性もあります。
これに対応するにはチームとして設計や運用スタッフを育成すること、外部のトレーニング、コンサルティングやサポートを積極的に活用すると行ったことを考えるべき、と嶋内氏はアドバイスします。
素早くHadoop環境の構築を実現する
そういった比較的難しいシステムの導入を容易にする、エンタープライズデータハブやHadoopのシステムのための検証済みビッグデータ統合基盤「Cisco Integrated Infrastructure for Big Data」を提供するのがシスコシステムズです。

同社 アドバンスサービス 茎沢信氏は、シスコのアプローチを「シスコとClouderaでテストをし、検証済みの構成をデザインガイドとしてまとめ、市場に展開している」と説明。スターターパック、パフォーマンス最適化パックやキャパシティ最適化パックなど、用途別にシステムがパッケージされた「Cisco Integrated Infrastructure for Big Data」を提供しています。
これはできるだけ個別のチューニングなしで使えるように考慮されており、既存の仮想基盤との統合運用も可能なパッケージ。サーバなどインフラの管理とHaddop関連の管理運用を一括管理できるUCS Director Expressなどをオプションでつけることも可能です。
Hadoopの環境は、サーバ、ネットワーク、ストレージなどの物理構成からOSとHadoopのインストールなども含めて手間がかかるものです。これが数台ではなく数十台やさらに増えたときには、その手間だけで膨大なものになり、また人為的ミスや抜けを完全になくすことも難しくなってくるでしょう。
シスコが提供する「Cisco Hadoop Starter Kit Service」では、構築済みのHadoopの基礎実行環境が素早く入手できるだけでなく、顧客の利用形態に合わせた設定書やプロジェクト計画書と合わせて構築されたHadoop環境の説明会によるナレッジトランスファも行われるため、ビッグデータ環境の検討、構築における時間とコストの短縮を図ることができます。

シスコ自身もHadoopアプライアンスを自社サービスで活用
シスコ自身もHadoopを自社のサービスで利用しています。それが同社マネージドスレットディフェンス リードデータサイエンティストのJames Sirota氏が紹介した「Advanced Threat Analytics」です。
このサービスは、シスコが顧客向けに提供しているセキュリティ分析サービス。ネットワークのパケットを分析し、マルウェアなどなんらかの脅威が存在しないかどうかを機械学習などによって発見、対策するというもの。
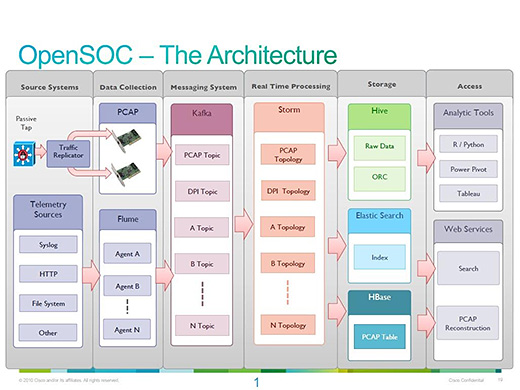
このために同社は365日24時間のセキュリティ対策センター(SOC)で分析を行っていますが、客先に設置したHadoopアプライアンスによってパケットの収集や基本的な分析などを行っています。
このHadoopアプライアンスは、シスコのUCSサーバを中心としたハードウェアに、Hadoop、Kafka、Elastic Search、MySQL、Storm、Sparkなどのビッグデータ向けソフトウェアで構成されています。

同社はこうした自社でビッグデータ基盤を活用した経験や知見を、さらに優れた製品やサービスを提供するためにフィードバックしているのです。
(本記事はシスコシステムズ提供によるタイアップ記事です)
あわせて読みたい
マイケル・デル氏自身がブログで、EMC買収後もVMwareは独立した公開企業のままにすると改めて表明
≪前の記事
OpenStack 12番目のリリースとなる「OpenStack Liberty」が登場。コンテナ管理の「Magnum」がフルリリース。そして次は「Miataka」!

