
Apache Sparkがスループットとレイテンシを両立させた仕組みと最新動向を、SparkコミッタとなったNTTデータ猿田氏に聞いた(前編)
最近ビッグデータ処理基盤として急速に注目を集めているのが「Apache Spark」です。
Sparkは、Hadoopと比較されることも多く、Hadoopよりも高速かつ高機能な分散処理基盤だと言われています。Sparkとはいったい、どのようなソフトウェアなのでしょうか? 今年6月にSparkのコミッタに就任したNTTデータの猿田浩輔氏に聞きました。
以下は猿田氏から伺ったSparkの紹介をまとめたものです。また、後編では猿田氏がコミッタになった経緯などもインタビューしました。
Hadoopでは複雑な処理に時間がかかる
 NTTデータ 基盤システム事業本部 システム方式技術事業部 OSSプロフェッショナルサービス 主任 猿田浩輔氏
NTTデータ 基盤システム事業本部 システム方式技術事業部 OSSプロフェッショナルサービス 主任 猿田浩輔氏Sparkとはなにかの前に、まずはHadoopの話から始めさせてください。
Hadoopとは、ざっくり言うと分散処理フレームワーク「MapReduce」と分散ファイルシステム「HDFS」の組み合わせです。最近ではYARNと呼ばれるクラスタ管理システムが加わるなど変わってきていますが、従来はこの組み合わせでした。
これまで、Hadoopの多くのユースケースではこの仕組みで事足りていましたが、複雑な業務処理の場合には1回のMapReduce処理では終わらずに多段処理が必要です。その多段処理は、一段ごとに中間データをHDFSに書き出して、次の段で読み込んで、という作りになることが多くありました。
こうした多段処理は、複雑なものだと数十段から百段以上になることもあり、また最近はMapReduceの上位でデータ処理を記述するApache Hiveのようなソフトウェアも、数十段もの多段処理を自動生成します。
しかし多段処理では毎回中間データを書き出し、読み込んでいるので、その分レイテンシが発生します。これが数十段、数百段と積み重なると処理全体のレイテンシは非常に大きなものになります。
また、段ごとにMapReduceのジョブを起動するので、そのたびにメモリなど計算リソースの確保やJavaVMの起動などが行われます。ここでもレイテンシが発生します。
Hadoopはもともとスループットを向上させることに最適化されていましたのでレイテンシは重視されてこなかったとはいえ、処理が複雑化するにつれて、レイテンシも重視されるケースで従来のMapReduceの課題が明るみになってきました。
スループットとレイテンシの両立を目指したSpark
その中で、スループットとレイテンシを両立させるものとして開発されたのがSparkです。
 スライド「メキメキ開発の進む Apache Sparkのいまとこれから」から
スライド「メキメキ開発の進む Apache Sparkのいまとこれから」からSparkの仕組みをイメージするとしたら、巨大な配列の各部分がクラスタにまたがっていて、それを一斉に分散処理する仕組みを持つといえます。
Sparkでの処理にはMapReduceでのMapやReduceといった区分けはなく、処理の途中で中間データの生成のような無駄なI/Oがなるべく発生しないようにスケジューラが処理を組み立ててくれます。また、機械学習のように何度もデータを繰り返して処理するものでは、キャッシュしたデータを使い回すことでもレイテンシを小さくしてくれます。
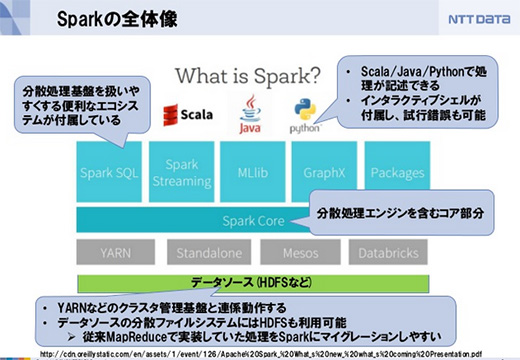 スライド「メキメキ開発の進む Apache Sparkのいまとこれから」から
スライド「メキメキ開発の進む Apache Sparkのいまとこれから」からSparkはインメモリの分散処理基盤と説明されることが多いのですが、内部でのレイテンシをできるだけ小さくするための手段としてインメモリ処理が使われている、ということで、それ以外にも中間データをできるだけ排除したり、何度もジョブの起動をしなくて済むといったこともレイテンシの改善に大きく効いています。
Sparkの登場で、もうHadoopは使わずにSparkだけあればいいとも思われがちです。しかしクラスタのメモリ量の10倍、100倍といった大規模データの処理には、やはりHadoopの方が安定していて堅実な処理ができます。
つまり大規模なデータを処理して絞り込むのはHadoopで行い、絞られたデータを基に機械学習などを行うのにSparkを用いるのが現在は適しているのではないかと思います。
Scala、Java、R、Pythonなどに対応
パッケージに最初からいろんなエコシステムが含まれているのもSparkの魅力です。SQLが使える人にはSpark SQLがありますし、IoTなどデータのストリーミング処理にはSpark Streaming。機械学習のMLlib、グラフ処理にはGraphXなどがあります。
HDFSもデータソースに使えるのでHadoopとの親和性も高く、従来HadoopのMapReduceで行っていた処理をSparkに移行しやすくなっています。
インタラクティブシェルで処理の試行錯誤することもできます。また、Scala、Java、データ分析処理が得意なRやPythonなどで処理が記述でき、データ分析が非常にしやすい環境が整っています。
Spark SQLはオプティマイザが走る
Sparkにはエコシステムのそれぞれの進化とコアの進化の2つの面があります。
エコシステムの部分では、Spark Streamingにおいて分散メッセージシステムのKafkaとの連係が強化されました。またMLlibでは機械学習のパイプライン処理を書きやすくするためのPipeline APIも提供されています。MLlibでは最近はPipeline APIの開発が活発になってきています
そして、いまもっとも注目されているのがSpark SQLです。SparkはRDD(Resilient Distributed Dataset)を中心に処理が進みますが、Spark SQLはそのRDDを包含するDataFrameを中心に処理をするものです。
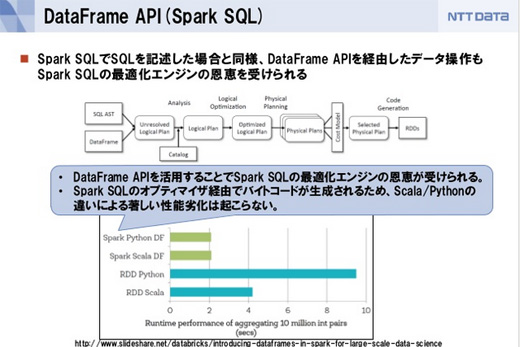 スライド「メキメキ開発の進む Apache Sparkのいまとこれから」から
スライド「メキメキ開発の進む Apache Sparkのいまとこれから」からDataFrameはRDBのテーブルのような、列があって型があるという、スキーマがあるようなデータを想像していただければいいと思います。DataFrameに対してSpark SQLで記述して処理できますし、Spark SQLはJDBCで接続できるのでレポーティングツールなど外部ツールからアクセスすることもできます。
Spark SQLやDataFrame APIを使う利点の1つがオプティマイザによる処理の最適化です。例えばScalaでSparkのコアAPIを使って複雑な処理を記述しようとすると、記述量が増えたり可読性が下がる場合があるほか、実効効率のよくない処理を記述してしまう場合もあります。
またコアAPIを用いて同様のRDDの変換処理を記述しても、APIを操作するプログラミング言語によって実効効率に差異がでてしまう問題もあります。
Spark SQLやDataFrame APIを使うと、JavaVMで走るジョブを最適化した上で生成してくれるので、効率の高い処理が実現できます。
あわせて読みたい
Apache Sparkがスループットとレイテンシを両立させた仕組みと最新動向を、SparkコミッタとなったNTTデータ猿田氏に聞いた(後編)
≪前の記事
IT系企業の平均給与/機械学習を誰でも使えるようにする「Cortana Analytics Suite」/Amazon API Gateway発表。2015年7月の人気記事

