
PaaS基盤「Cloud Foundry V2」のアーキテクチャは、どうなっている?(後編)
Publickeyでは2011年10月に開催された「第1回 CloudFoundry輪読会」を基に「PaaS基盤「Cloud Foundry」のアーキテクチャは、どうなっている?」という記事を公開しました。あれから3年半経過した現在、Cloud FoundryはV2へバージョンアップしました。
そして「第18回 Cloud Foundry 輪読会」では、このCloud Foundry V2のアーキテクチャについて解説されました。本記事は、その内容をまとめたものです。
(本記事は「PaaS基盤「Cloud Foundry V2」のアーキテクチャは、どうなっている?(前編)」の続きです)
Cloud Foundry内部のRouterはリクエストを振り分ける
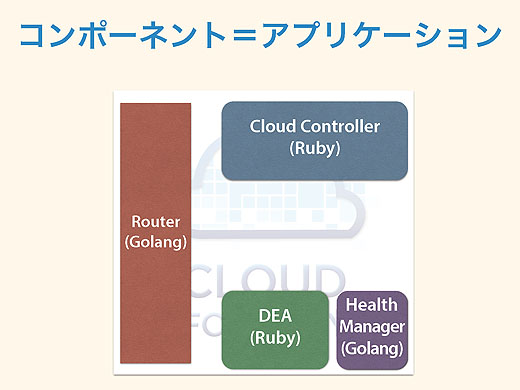
Cloud Foundryにおけるコンポーネントの役割を説明していきましょう。
コンポーネントとは何か。これはつまりアプリケーションで、1つのプロセスです。例えばRouterはGo言語で書かれたアプリケーションで、Health ManagerもGo言語になっています。DEAやCloud ControllerはRubyで書かれています。
これらはただのアプリケーションなので、やろうと思えば1つのVM(仮想マシン)上で動かせますが、一般に実運用を考えると、1コンポーネントずつ1VMで動かすことが多いでしょう。
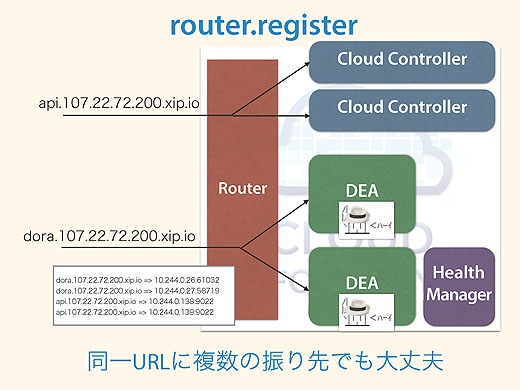
まずRouterですが、URLによってアクセスを振り分けるコンポーネントです。
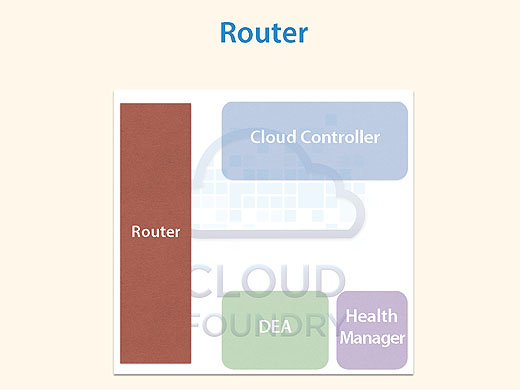
api.xxxだったり、dora.xxxだったり、URLを見て振り分けるわけです。ネットワーク機器のルータとは別のものですので注意してください。Cloud FoundryではGoRouterと呼ぶことが多いですね。

なぜRouterはリクエストの振り先を知っているのでしょうか。それはrouter.registerというメッセージの仕組みがあって、DEAやCloud Controllerが「このURLの振り先は実体がここだから転送して」とか「DEAはここだから、こっちに転送して」など、各コンポーネントがRouterに対してあらかじめ情報を送っておくんです。
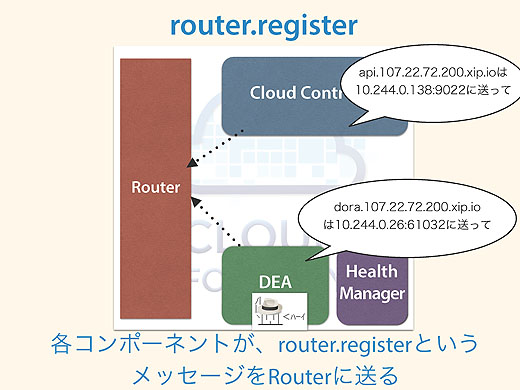
Routerはオンメモリデータベースを持っていて情報を格納しておき、実際のアクセスと突き合わせて振り先を判断しています。
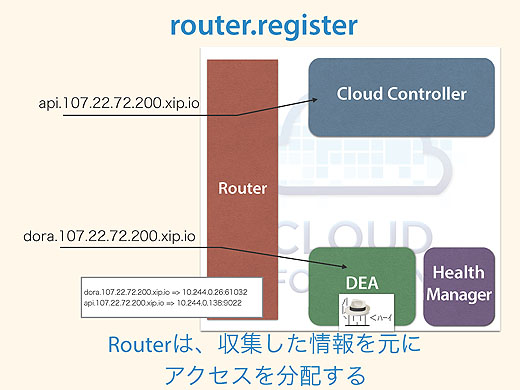
仮に同じアプリケーションが複数インスタンス合った場合でも、それぞれがデータベースに入っているので、ラウンドロビンで振り分けられるようになっています。ですから同一のURLに複数の振り先があっても大丈夫なようにできています。
Cloud ControllerはAPIの提供、DEAはアプリの実行
Cloud Controllerはいろいろ機能がありすぎて説明が面倒くさいのですが、基本的にはAPIを提供するコンポーネントだと考えてください。

DEAはユーザーのアプリケーションを動かすためのコンポーネントです。ユーザーアプリケーションはDropletという単位に分けられるので、DEAはDroplet Execution Agentの略となります。

Cloud Foundry V2ではユーザーアプリケーションのステージング作業、例えばRubyではバンドルのインストールとかそういうこともDEAがしています。またDEAはCloud Foundry V2からWarden(ウォードン)というLinuxコンテナを使っています(参考「すごく分かるwarden」。
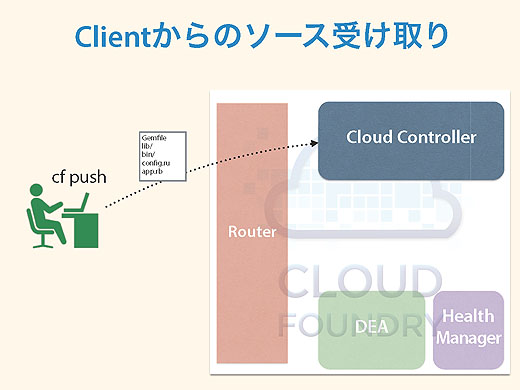
cf pushでアプリケーションをデプロイする流れを見てみましょう。クライアントからcf pushすると、Cloud Controllerがクライアントからソースコード一式を受け取ります。
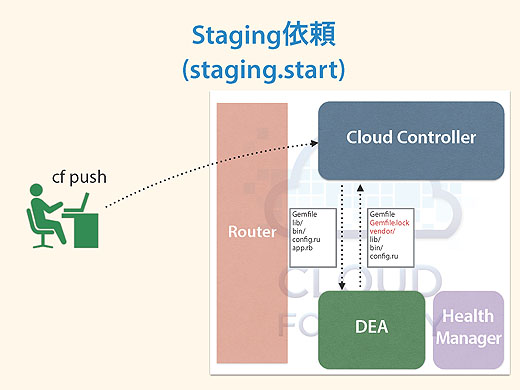
次にステージング依頼としてstaging.startという命令でCloud ControllerがDEAにバンドルのインストールを行うように要求し、DEAはその作業をします。
バンドルのインストールが終わった一連のパッケージを「Golden Package」と呼んだりしますが、Cloud Controllerはそれを手元に保存し、それをDEAに「実行して」と要求します。
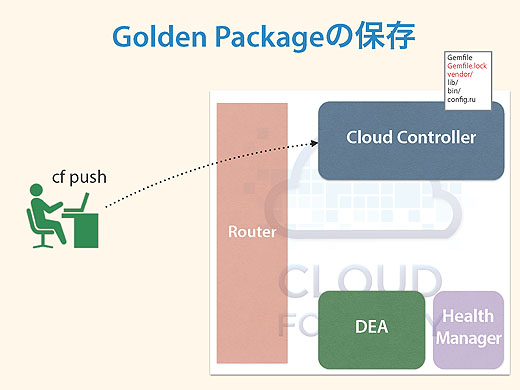
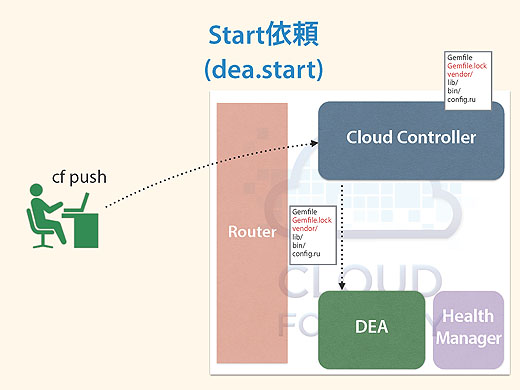
するとDEAはそれを自分のところのVMで立ち上げます。
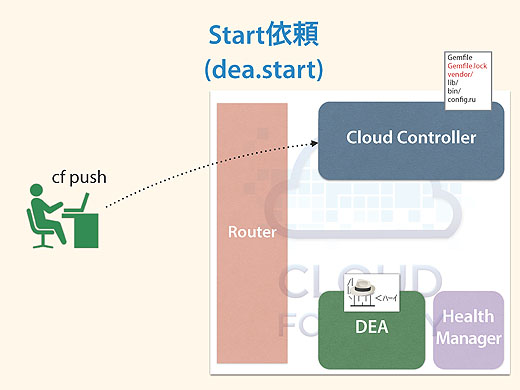
さっきcf scale -i 3でインスタンスを3つにしましたが、この命令はCloud Controllerがソース一式を持っているので、dea.startをDEAに依頼をして各DEAがインスタンスを立ち上げるということになっています。
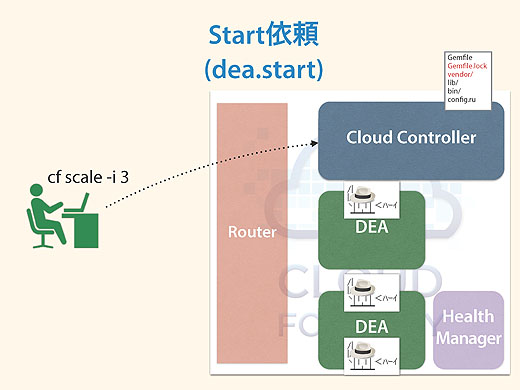
アプリケーションを監視するHealth Manager
Health Managerはユーザーアプリケーションがあるべき姿になてちるかどうか、監視を行うコンポーネントで、最新版はGo言語で書かれていて「hm9000」と呼ばれています。
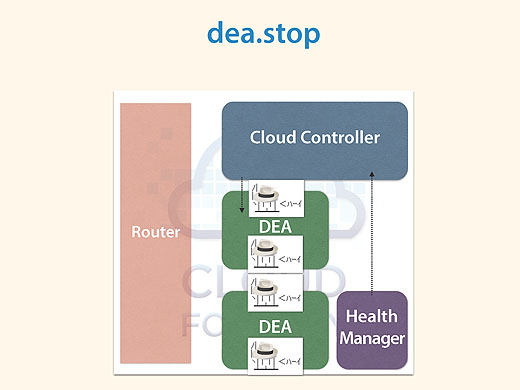
Health Managerは何をしているのかというと、例えばユーザーアプリケーションのインスタンスが突然死んだら、死んだことをDEAがHealth ManagerにDroplet.exitを送って伝えます。
Cloud Controllerはそれを基にdea.startをかけて、インスタンスが無事復活する、という仕組みです。
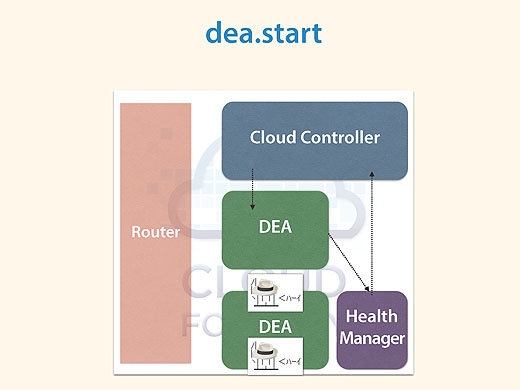
Health Managerは状態を見て、怪しかったらCloud Controllerに伝える役割なのです。
それから、たまにcf scaleコマンドでインスタンスを3つ起動したのに、4つ起動されることがあります。それはDEAが重たくてインスタンスの起動に手間取ってタイムアウトして、ほかのDEAに起動を依頼したところ、あとから重くて起動に手間取っていたインスタンスも上がってきてしまった、といった理由です。
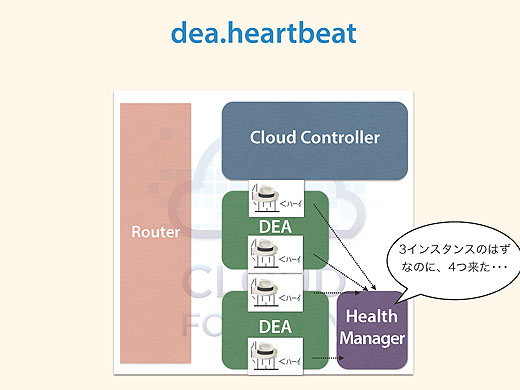
DEAはユーザーアプリケーションごとに定期的にハートビートをHealth Managerに送っています。するとハートビートが4つ来ることになるので、多いからなんとかしてとHealth ManagerがCloud Controllerに伝えると、Cloud Controllerがdea.stopで1つ減らすと。
けっこうよく考えられたよくできた仕組みですね。
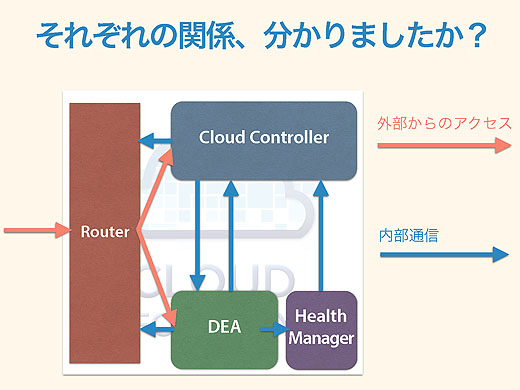
コンポーネント間の通信を知ろう
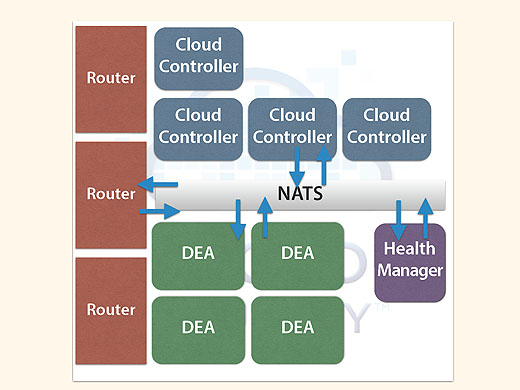
Cloud Foundryの内部の通信をもう少しよく見ていきましょう。さっきのこの図ですが。
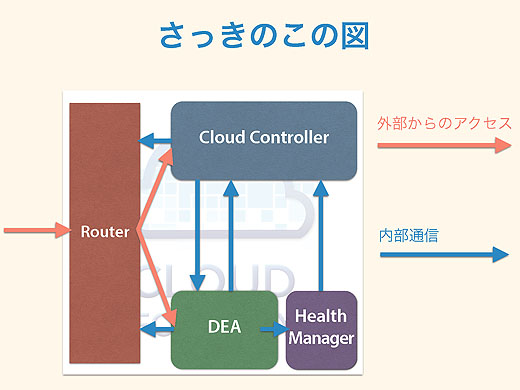
実はウソです。正確には、こういう仕組みになっています。
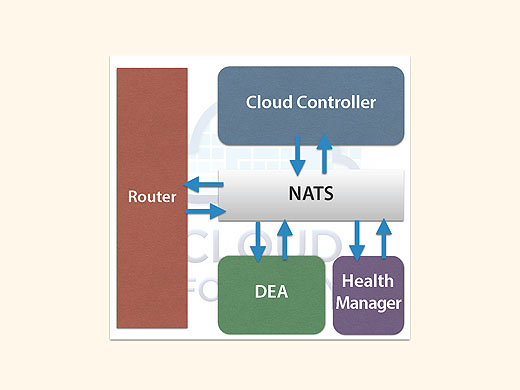
あいだに何かいます。これがNATSです。NATSがいろんなメッセージを仲介することになっています。
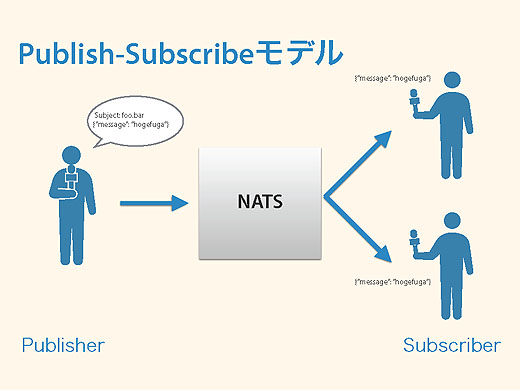
NATSはPublish/Subscribeモデルの軽量メッセージングシステムです。もともとCloud Foundryの生みの親、Derek Collison氏が作ったもので、彼はいまは違う会社にいますが、Cloud Foundryができたときからある仕組みです。
Cloud FoundryはNATSありきのアーキテクチャになっていると言っても過言ではありません。もともとNATSはRubyで書かれていましたが、いまはこれもGo言語になりました。Cloud Foundryの中心になるところはかなりGo化されてきていますね。
Publish/Subscribeモデル(Pub/Subモデル)は、発信するPublisherがいて、受け取るSubscriberがいて、Suscriberはfoobarというメッセージがきたらほしいです、とNATSに伝えておきます。で、Publisherがfoobarをしゃべると、Subscribeしている人たちに届けられます。情報をほしい人だけにほしい情報が届けられる仕組みです。
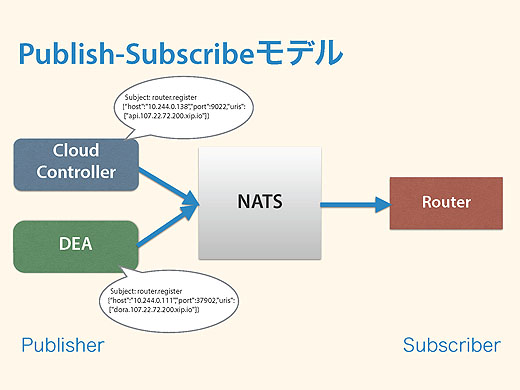
これをCloud Foundryがどう使っているかというと、さっきのRouterの例がそうですね。Cloud Controllerから、api.xxxというメッセージはここに届けてほしい、DEAからはdora.xxxというメッセージはこのホストに届けてほしいということを、router.registerという命令でNATSに送ります。
そしてRouterはrouter.registerという命令をSubscribeしているので、無事にこれらのメッセージを受け取れる、という仕組みです。
これでなにがうれしいかというと、Routerを増やしたときにそれぞれのRouterがまったく同じメッセージを受け取れる、というメリットがあることです。
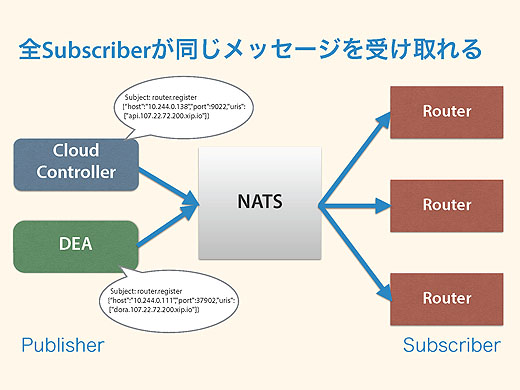
NATSがあれば、Routerを起動すれば、あとはRouterが自分でNATSのrouter.registerをSubscribeすれば受け取れます。だからRouterの起動だけで済みます。
NATSがないと、例えばRouterを起動する前にIPアドレスをデータベースか何かに登録してからRouterを起動し、DEAやCloud Controllerは定期的にデータベースを参照して、ルータが増えたことを検知したら、増えたルータにそれぞれ情報を送る、といったことが必要となります。やらなくてはいけないことが増えてしまいます。
Pub/Subモデルはスケールアウトに強いアーキテクチャになっています。
実際のCloud Foundryの運用ではRouterもDEAもCloud Controllerも複数あるという形態になっています。Health Managerは1つしかいませんが。
Cloud Foundryは自律分散型システム
まとめです。
Cloud FoundryのアーキテクチャはNATSを中心とした疎結合なコンポーネント連係の自律分散型システム。中央で管理している情報はほとんどなくて、それぞれのコンポーネントが勝手にしゃべって成り立っているシステムといえます。また自己修復機能で、アプリケーションが死んだりしても勝手に直ります。
そして単一障害点(SPOF)を排除しています。このあいだまではNATSがSPOFでしたが、NATSのクラスタ化ができるようになったので解決されつつあります。

Cloud Foundry V1とV2ではコアなコンポーネントやおおまかな仕組みは変わっていません。
ただDEAがDEAngになって、Wardenという独自開発のコンテナを使っていて、そこでアプリケーションを動かすようになっています。それからいろんなコンポーネントがGo言語で作られるようになって、だいたい半分がGo言語になっています。
今回は説明していませんが、HerokuのBuildpackが使えるようになりました。
そして大事なことですが、APIの互換性はV1とV2で一切ありません。アーキテクチャは変わってないのに、これはどうなんだとじゃっかん思わないでもないですが。

Cloud Foundry V2のアーキテクチャ
あわせて読みたい
Heroku Connect登場。Heroku PostgresがSalesfoece.comのデータベースと同期。RailsやJava、PHPなどで企業向けアプリ開発
≪前の記事
PaaS基盤「Cloud Foundry V2」のアーキテクチャは、どうなっている?(前編)

