
HadoopはいずれOLTPも実現し、エンタープライズデータハブとなる。Hadoop Conference Japan 2014
7月8日に開催されたHadoopに関する国内最大のイベント、「Hadoop Conference Japan 2014」には、Hadoop創始者のDoug Cutting氏が来日、基調講演「データの未来」に登壇しました。
Cutting氏はデータの重要性の高まり、オープンソースソフトウェアがソフトウェア市場で勝ち残ると指摘し、Hadoopはビッグデータのプラットフォームとしてさらに進化し唯一の存在になるだろうとの予想を披露しました。
Cutting氏の講演をダイジェストで紹介します。
データの未来
Hadoop創始者でClouderaチーフアーキテクト Doug Cutting氏。

私はとてもラッキーだった。開発に関わったいくつかのオープンソースは成功し、みんなからは私には未来が分かると思われている。
実際に未来を知ることなどできないが、事実を元に予測することはできる。ロケットならどれだけのスピードでどこへ向かっているかが分かれば、着地点が分かる。そのように、事実を集めてそれを基に考え、複数の視点から見ることでデータの世界がどこへ向かっていくのか予想しよう。
それにはまずムーアの法則から始めるのがいいと思う。
この50年以上、コンピュータの発展は劇的であり、プロセッサ、ストレージ、メモリ、ネットワーキングなどのすべてが爆発的に安く、高性能になっている。システムを構築するテクノロジーが変われば、システムそのものも根本的に変わっていくだろう。
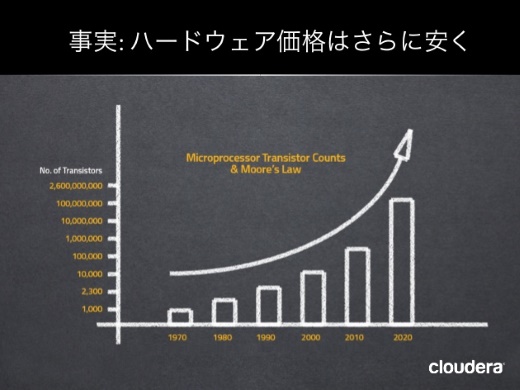
そこで予想できるのは、将来、システムはさらに大量のデータを処理できるようになるということだ。
コンピュータが安くなるにつれ、自動車やポケットの中などあらゆる場所で使われるようになった。産業や社会のあらゆる部分でデータが使われるようになり、データを分析することでものごとをより理解し、改善につなげられる。企業は競合に勝つためにデータを活用するようになってきた。データの重要性は高まっていくだろう。

そしてデータ分析にはハードウェアとともにソフトウェアが必要だ。
私たちはオープンソースという開発手法のソフトウェアを見てきた。そしてオープンソースのソフトウェアが成功してきた。例えばLinuxはもっともポピュラーなOSになったし、AndroidはモバイルOSとして普及し、Apacheはもっともよく使われるWebサーバだ。
企業がビジネスの基盤にテクノロジーを採用するとき、そのテクノロジーを誰かがコントロールしているのはビジネス上のリスクになると考え、だからオープンソースを使うようになってきた。もう誰もプロプライエタリなテクノロジーを使わなくなるのではないかと私は考えている。

私の予想だが、プラットフォームのテクノロジー、とりわけデータの分野はオープンソースが主流になるだろう。
Hadoopの改善は続いていく
2002年にNutchというサーチテクノロジーを作って、それを分散システムとしてどう作ろうかと言うときにGoogleが彼らの作ったフレームワークの論文を公開した。そこで私たちは試しに実装したところ、Yahoo!がそれに興味を持って、そのおかげでYahoo!でフルタイムで働き始めた。
やがて数千台ものマシンでの分散処理によって、以前はできなかったようなことが可能になる。とはいえMapReduceの処理はできても、セキュリティや単一障害点、ノードダウンしたときの処理といった課題はあった。
しかしこの制限も取り除こうと開発が進み、多くのセキュリティが改善され、単一障害点が取り除かれ、MapReduceもYARNになる。こうしてつねに改善が続いていく。
だから予想は、Hadoopはさらに改善されたソリッドな基盤となり、ビッグデータのためカーネルとなるだろう。

さらに素晴らしいことに、Hadoopが当たり前になり、MapReduceの上にはPigやHiveが乗って、SQLさえ知っていれば大規模な分散コンピューティングを容易に使えるようになる。
さまざまな機能、ストリーミング処理、グラフ処理、インメモリデータベースなどが今後もHadoopというプラットフォームの上に乗ってくる。Hadoopがより多機能になっていくだろう。
そしてHadoopが業界を席巻し、競合はなくなっていく。いまではHadoopが標準的なプラットフォームになろうとしていて、IBMもオラクルもマイクロソフトも、すべてのビッグプレイヤーがビッグデータのプラットフォームにHadoopを採用している。

HadoopにはOLTPさえ乗るだろう
この進化はどこまで行くのだろうか? 私はどんなソフトウェアでも、例えばオンライントランザクション処理(OLTP)であってもHadoopで動くと考えている。
OLTPは広域分散処理ではうまくいかないと考えられていた。しかし2年前、GoogleがSpannerに関する論文を発表し、その実現を示した。いちど誰かが成功したのなら、私たちにもできるはずだ。

私たちはまだ、Hadoop上で動くOLTPを手にしていないけれども、誰かが作ることだろう。それはHadoopの、安価でシステム管理しやすいといったメリットを得られるからだ。
これが私たちの見ている将来像だ。それは「エンタープライズデータハブ」であり、データをひとつのところに蓄積するものとなる。

オリジナルのまま大量のデータを低コストで保存でき、最適な処理方法を選択でき、セキュアで可用性のあるオープンソースによるプラットフォームとなる。
こうしたデータ処理革命の中に、私たちはいるのだ。そして革命には恐怖もつきものだが、Hadoopはそこで安全な道筋を示してくれるものだ。
公開されているスライド。
あわせて読みたい
Internet Explorer 11で縦書き表示と縦書きのルビ表示が改善。教科書や電子書籍などに
≪前の記事
YARNの登場によりHadoopは複数の並列分散処理エンジンを併用できる環境へ。Hadoop Conference Japan 2014

