
非分散データベースを分散データベース化する「Dynomite」、Netflixがオープンソースで公開
RedisやMemcachedといったインメモリデータベースは非常に高速にレスポンスを返してくれるデータストアですが、それ単体ではスケーラビリティや可用性などに限界があります。
Netflixがオープンソースで公開した「Dynomite」(ダイナマイトとは綴りが違うのに注意)は、こうしたデータストアを分散データベース化し、高速なデータストアの特長を活かしつつ高いスケーラビリティや可用性を実現するためのソフトウェアです。
アプリケーション側でシャーディングのような面倒なデータ構造を設定することなく、RedisやMemcachedをノードとし、CassandraやAmazonクラウドのDynamoDBのような大規模分散データベースを構成できます。
DynomiteはAmazon DynamoDBにインスパイアされて作ったと説明されています。Dynomiteという名前の由来もそこにありそうです。Netflixのブログ「Introducing Dynomite - Making Non-Distributed Databases, Distributed」から引用します。
Dynomite is a sharding and replication layer. Dynomite can make existing non distributed datastores, such as Redis or Memcached, into a fully distributed & multi-datacenter replicating datastore.
Dynomiteはシャーディングとレプリケーションのレイヤだ。Dynomiteは既存の非分散データストア、例えばRedisやMemcachedなどを、マルチデータセンターでレプリケートされる完全な分散データストアにする。
Dynomiteノードによる分散データベース
「Introducing Dynomite - Making Non-Distributed Databases, Distributed」の図などを基に、Dynomiteの仕組みを手短に紹介しましょう。
Dynomiteは複数のノードから構成されるラックの1単位で、データ全体を保持します。ラックは複数存在でき、お互いにレプリケーションを行うことで可用性とスケーラビリティを実現します。
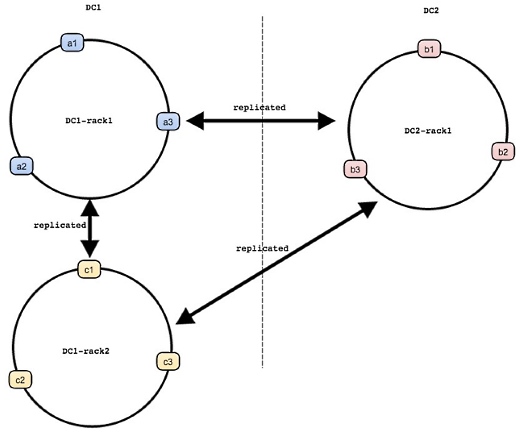
それぞれのラックは複数の「Dynomiteノード」で構成されており、これがプロキシ、トラフィックルータ、Gossipperの役割を果たします。Dynomiteノードとは、DynomiteプロセスとRedisやMemcachedなどのシングルデータストアが組になったものです。
クライアントからDynomiteノードへデータを書き込むときには、どのノードへ接続してもよく、あるノードにデータが書き込まれると、自動的に同じデータが同一ラックの別ノードと別のラックに書き込まれます。ただし同一ラック内の別ノードに書き込んだ時点でクライアントにOkが返され、ほかのラックへの書き込みは非同期となります。
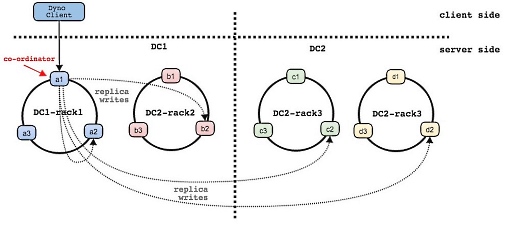
データの読み込みでも、クライアントはラック内のどのノードへ接続してもよく、読み込み要求を受け取ったそのノードにデータがなかった場合、自動的に同一ラック内の別のノードにその要求が転送されます。
Dynomiteのクライアントは、やはり同社が開発した「dyno」が用意されており、コネクションプーリング、トポロジーを考慮したロードバランス、ローカルのDynomiteラックが落ちたときの自動フェイルオーバーといった機能を備えています。
あわせて読みたい
メルカリ×さくらインターネットTOP対談。グローバルで通用するプロダクト作りへのこだわり[PR]
≪前の記事
Google、クラウドとオンプレミスを接続する「Google Cloud Interconnect」発表。専用線、キャリア接続、VPN接続に対応

