
基幹システムをクラウドへあげるのは簡単ではなかった。ノーチラス・テクノロジーズがクラウドの現実を語る(前編)
基幹システムをクラウドで実現する。その過程でどのような技術を用い、どのような苦労があったのか。小売り流通業である西鉄ストアの基幹システムをAmazonクラウド(以下、AWS:Amazon Web Services)の上で実現したノーチラス・テクノロジーズが、その詳細について紹介したセミナーを5月15日、アマゾンジャパン本社のセミナールームで開催しました。
大規模システム開発の現状、Hadoopの可能性、クラウドのメリットとデメリットなど、参考にすべき多くの内容が語られたセミナーでした。この記事ではその概要を紹介します。
止まってはいけない基幹システムをクラウドへ
ノーチラス・テクノロジーズ 代表取締役社長 神林飛志氏(写真中央)。

西鉄ストア様の本部基幹システムをクラウドへ移行する事例を紹介します。
結論から言えば、簡単ではありませんでした。プロジェクトとしては、ピーク時には50人から60人がかかわる典型的な大規模SIになりました。
売上げの計上、債権やクレジットカードの計上や回収、請求書の発行と入金の消し込みや、費用、仕入れ、買い掛けや未払い金の対応など、いわゆる本部のバックエンド全般です。
また、テナント管理やリベートの処理などは、非常に複雑な処理です。そして管理会計もあり、てんこ盛りです。
もともとはオフコンをメインにして動かしていたものを全部リプレースして、機能を拡張しています。ノンストップが求められるシステムで、特に売上げの部分は止まると店舗の営業が全面的に止まります。
もともと某国内クラウドで最初は運用していましたが、いちど営業が3時間くらい止まりまして、それが今回アマゾンさんに移行した背景でもあります。
対象業務は売上げ管理、消費税計算、管理会計など
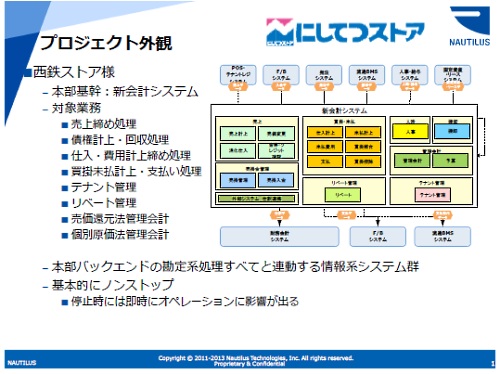
業務目的について。まずは売上げの締めです。店舗と本部どちらでも締めができるアーキテクチャになっていまして、これはパッケージに手を入れて、機能をひきはがして実装したものです。
債権の計上、回収。これはいわゆる名寄せ処理で、非常に重い処理になります。フルマッチをシステムでやっています。ただ全部はマッチングができないので、ヒューリスティックな処理(類推的な処理)も入れていて、なかなか大変です。
そして話題の消費税処理。これは結構大きなインパクトがありました。というのは、段階課税(消費税を2014年に8%、2015年に10%へと段階的に上げていく政策)が視野に入っていますし、いまの流れだと食品は非課税、非食品は課税だろうと考えられていまして、スーパーマーケットですとどちらも扱っています。
そうすると、いまは伝票単位で消費税を計算しているのが、明細単位での計算が必要になります。そうなったとたんに複雑さが数倍から十数倍になります。

テナント管理は、おそらく日本でHadoopを使ったバッチ処理としてはおそらく最長です。3500段のバッチです。これは、テナントのレジの売上げから、かかった費用を計算してネット(差し引きして正味の売上げを計算)して、それにスキームを当てて料率を計算し、それをさらに控除する、という形になっています。
そしてリベート。小売り流通のリベートは複雑怪奇ですが、そこをできるだけシステム化しました。
最後に管理会計。データ総量でいうと管理会計が全体の3分の1を占めており、ここはなかなか苦労しました。

分散処理を業務に使うことで新しいことができる
管理会計をなぜやったかというと、IFRSです。
いま、売上げの管理から利益の管理へという流れがあります。売上げ管理は単純にデータをまとめるだけで計算できますが、利益管理はそこからコストを引かなくてはいけないので、マッチング処理が発生して計算が複雑になります。これを単品の流れを追いかけてやりましょうと。
これは過去20年にわたってどこもチャレンジしていました。私も十何年前にやって、サーバを100台並べた処理で24時間を超えてしまいました。計算量がそれだけ多いんです。今回それがなぜできたかというと、Hadoopを使ったからです。分散処理を業務に使うことで新しいことができるようになったと。

スケジュールの遅れやトラブルも発生
ここだけ聞けばなかなか先進的ですが、しかし苦労もしました。まずスケジュールが遅れに遅れました。
2010年にプロジェクトを開始して18カ月後の2012年3月末にカットオーバーの予定が、12カ月遅れました。ただ、全面的に遅れたわけではなく、順次リリースの最初は予定通りにいきましたが、全部をカットオーバーするのが遅れました。
これだけの規模ですので、あらゆる課題が発生しました。
例えば、JavaScriptで業務系の画面を作りましたが、これはもう絶望的なくらい大変でした。いろいろやりましたが、性能はでない、テストもできないなど、おそらく全日本的に絶望している人が多いと思います。業務系とWeb系では構成が違うので、なにかやらないとエンタープライズの画面系は全面的に崩壊します。
バッチ処理も、最初は全部をHadoopでやるつもりはなく、SQLを併用するつもりでした。しかしこれもダメで変えました。
プロジェクトマネージャも3回変わるという異常事態で、例によって病気になって出てこられませんとか。その理由はコストを重視して外注比率が上がりすぎたことでした。

ある局面でのHadoopの処理速度は圧倒的
今回のポイントはパフォーマンスでした。ヘビーバッチは最初から予想されていて、予想通りそうなりました。インフラは最初からクラウドを想定していましたが、これもなかなか苦労しまして、最終的にアマゾンさんにあげるという決断をしました。
このパフォーマンスとインフラの課題をどう解決したか、ということをお話ししたいと思います。
まずバッチの概要です。だいたい1日1億件の処理、明細の処理です。債権管理が900万件程度、仕入れ2700万件、これらもデイリーです。さすがに流通小売りだけあって、非常に細かいデータが多いです。特に原価計算はピーク時で5億件。
いかにHadoopといえども8時間くらいかかります。原価計算だけで3時間くらい。3時間でも早い方で、RDBなら100時間くらいかかるシロモノです。
これらのバッチ処理をRDBとHadoopでやろうとしたのですが、SQLでバッチ処理をまともに書ける人は残念ながら少ない。本来ならSQLのジョインなどをうまく使いながら1本のSQLで書くべきなのですが、おそらくそれを書ける人はそんなにいません。
どうするかというと、SELECTでデータをもってきて別プロセスでデータを作ってデータベースにインサートして、といった処理を書いてしまう。当然ながら遅くなります。これがSIにおけるSQLの実態で、やっぱり遅くなりましたと。
しょうがないのですべてHadoopで回すことになりました。
やはりHadoopは速いです。ある局面ではRDBや汎用機でも勝てません。特にFull-Outer-Joinは圧倒的に速い。全データにアクセスするようなときも圧倒的に速いです。向いている処理なら、例えばRDBで3~4時間かかる処理が本当に20分くらいで終わります。
ただ、SQLで1分とか5分で終わる処理は、これはHadoopでは速くなりません。オーバーヘッドというのはそれなりにあります。HadoopクラスタとRDBのやりとりするところが詰まるので、ここのパフォーマンスをどう上げるのかがポイントです。ここは苦労したところです。

優秀な人をどれだけレバレッジできるか
開発手法はAsakusa Frameworkを使いました。これはSQLを全部捨ててもおつりが来るくらい圧倒的でした。ただ、ちゃんと設計されていることが前提です。Asakusaがなかったらプロジェクトとしては破綻していたな、という気がします。
SIではエンジニアにばらつきがあって、優秀な人はそうでない人のカバーやフォローに追われてパフォーマンスが落ちるというのが実態です。
だからできないヤツはできるだけ書かせず、できる人をどうレバレッジするか。優秀な人をどれだけレバレッジできるかが課題だと思います。

ユーザーの視点からすると、SIerには任せない方がいいのではないかと思います。
ユーザーさん自身がどれだけチェックできるかがポイントです。業務系では、分からないことがあるとSIerは適当に作ってしまいます。そういうことに対する自衛策として、ユーザーさんもある程度関与しながら、管理しながら作る、ということができないといけません。レビューしながら、西鉄さんではそういう風に作りました。
≫後編に続きます。後編では、AWSへ移行せざるを得なかった理由。そしてクラウドのメリットやデメリットについて解説されます。
あわせて読みたい
基幹システムをクラウドへあげるのは簡単ではなかった。ノーチラス・テクノロジーズがクラウドの現実を語る(後編)
≪前の記事
Opscode Chefが、IBMと協業発表、Windows Azureにも対応。エンタープライズでの存在感を高める

