
Facebook、分散SQLエンジン「Presto」公開。大規模データをMapReduce/Hiveの10倍効率よく処理すると
Facebookは、数ペタバイト級の大規模データに対しても、対話的にアドホックな問い合わせを可能にする分散SQLエンジン「Presto」を、オープンソースで公開しました。
PrestoはFacebook社内で大規模データの分析のために開発され、すでに同社社内使われているもの。
FacebookはPrestoを開発した背景として、大量のデータをHadoop/HDFSベースで保存したものの、バッチ指向のMapReduceではなく、リアルタイム性に優れた処理が必要になったためだと、次のように説明しています。
Facebook’s warehouse data is stored in a few large Hadoop/HDFS-based clusters. Hadoop MapReduce [2] and Hive are designed for large-scale, reliable computation, and are optimized for overall system throughput. But as our warehouse grew to petabyte scale and our needs evolved, it became clear that we needed an interactive system optimized for low query latency.
Facebookのデータウェアハウスは、いくつかの大規模なHadoop/HDFSベースのクラスタに保存されている。Hadoop MapReduceとHiveは大規模で信頼性の高い処理のために設計され、システム全体のスループットに最適化されている。しかし、そのデータウェアハウスがペタバイト級に大きくなるにつれ、私たちのニーズも変わってきた。それは即時性に最適化された対話的なシステムになっていった。
2012年頃から使えるソフトウェアを探したが見つからなかったため、自社でPrestoを開発する決断をしたとのことです。そしてPrestoは、MapReduceでSQLを実行する仕組みを持つHiveよりも、CPUの効率やレイテンシの面で10倍優れていると。
Presto is 10x better than Hive/MapReduce in terms of CPU efficiency and latency for most queries at Facebook.
Prestoはほとんどの社内のクエリにおいて、CPUの効率とレイテンシに関してHive/MapReduceよりも10倍は優れている。
Hive/MapReduceとは異なるアーキテクチャ
Prestoは、アドホックなクエリの結果をインタラクティブに得ることに最適化された分散SQLエンジンです。ANSI SQLに準拠し、ジョイン、アウタージョイン、サブクエリ、一般的な集計関数やカウントなどに対応。
Facebookは以前、SQLに似たHiveQLをMapReduce上で実行し、大規模分析を行うオープンソースの「Hive」(現在はApache Hive)を開発していますが、PrestoのアーキテクチャはMapReduce/Hiveとは異なっています。
クライアントからSQL文がコーディネイター(下図の右上)に送られると、そこでパース、アナライズ、実行プランが立てられます。スケジューラが実行プランを実行パイプラインへと組み上げ、データに近いノードに対してジョブを割り当て、進捗を監視。クライアントが結果を引き出してきます。
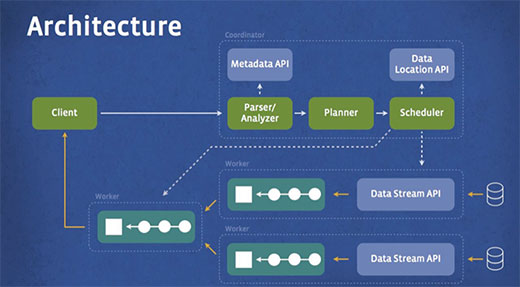
すべての処理は各サーバのインメモリで行われており、Presto自体はJavaで開発されているとのこと。
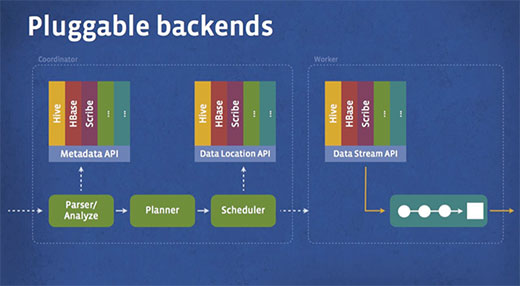
また開発初期に、データがさまざまなデータストア、例えばHDFSやHBase、FacebookのNews Feed Backendなどに分散していたためPrestoは当初からデータストアを抽象化するプラガブルな構造を採用したと説明されています。
あわせて読みたい
JavaScript MVCフレームワーク「AngularJS 1.2」リリース。要望の多かったアニメーション機能が追加、脆弱なコードを制限するモードも
≪前の記事
2013年10月の人気記事「迷ったら健全な方」「エンジニアに高い給料を払ってる会社」「この1年の優れたIT系書籍はどれか?」ほか

