
カラム型データベースでトランザクション処理を実現するカラクリとは? インメモリとカラム型データベースの可能性を調べる(その5)
SAPのHANAは、最初からインメモリデータベースとカラム型データベースの技術を用いて高速な集計や分析処理と高速なトランザクション処理とを両立させることを目指して開発されたと、HANAの開発者でありSAPの共同創業者であるハッソ・プラッタナー氏はHANAの設計思想と実装を解説した著書「In-Memory Data Management」で書いています。
ここでは、その書籍および公開されている論文「Efficient Transaction Processing in SAP HANA Database – The End of a Column Store Myth」(SAP HANAデータベースにおける効果的なトランザクション処理 ― カラムストア神話の終焉)からの情報を中心に、HANAの仕組みについて解説していきましょう。
RowストアとColumnストア
HANAには2つのデータベースエンジンが搭載されています。従来のデータベースと同じ行指向のデータベースエンジン「Rowストア」と、カラム指向のデータベースエンジン「Columnストア」です。
どちらのエンジンを使うかはテーブルを定義するときに決定されます。テーブル定義の時点でRowストアのテーブルとして定義すれば、そのテーブルは自動的にRowストアとして操作されることになり、Columnストアのテーブルとして定義すれば、そのテーブルは自動的にColumnストアとして操作されることになります。
「なんだ、結局2つのエンジンを使い分けるのか」と思ってしまいそうですが、そうではありません。HANAにおいてメインのデータベースエンジンはあくまでColumnストアであり、アプリケーションに対する処理のほとんどはこのColumnストアによって行われます。Columnストアは、集計や分析処理が得意であると同時に、カラム型データベースエンジンでありながらトランザクション処理能力も備えています。
Rowストアは、おもにシステムテーブル管理などの用途で使われます(利用者が明示的にRowストアのテーブルを定義してアプリケーションで使うことも可能です)。
デルタバッファでトランザクション処理対応
カラム型データベースが集計や分析処理に長けている一方で、データの追加削除更新などのトランザクション処理が苦手であることはすでに紹介しました。
HANAのColumnストアでもデータは列方向に圧縮されているため、そのままではデータの追加や削除、更新などを行おうとすると、1件操作するごとにすべての列でデータの圧縮、展開が必要になります。いかにインメモリデータベースといえども、これでは高速な処理が実現できません。HANAではこれをどう解決しているのでしょうか。
HANAではこれを、「デルタバッファ」という仕組みで解決しています。デルタバッファは「L1デルタ」と「L2デルタ」に分かれています。L1デルタとL2デルタ、そしてカラム型データベースであるメインストアの3つが、Columnストアの実態です。当然、すべてインメモリで処理されます。
L1デルタとL2デルタ、メインストアはまとめて外部に対して抽象化され、1つのColumnストアに見えます。
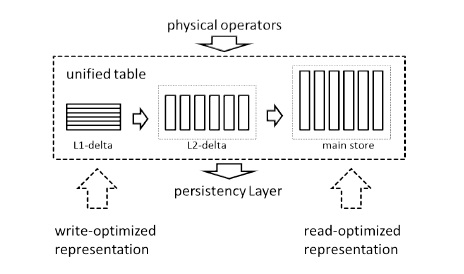 「Efficient Transaction Processing in SAP HANA Database – The End of a Column Store Myth」から引用
「Efficient Transaction Processing in SAP HANA Database – The End of a Column Store Myth」から引用データベースに対する追加、更新、削除が行われると、その操作はすべてL1デルタに書き込まれます。L1デルタは行指向のデータベースと同じ構造になっており、圧縮もされず、変更内容はすべて追記されるだけなので、この書き込み処理はきわめて高速に実行されます。
そしてL1デルタに書き込んだ時点で(そしてその操作をログに書き込みが終了した時点で)、アプリケーションからは見た処理は完了します。これにより、HANAはきわめて高速にデータの追加削除更新の処理を行ったように見えます。
L1デルタに書き込まれた内容は、バックグラウンドでL2デルタに変換されます。L2デルタはカラム型データベースの形式になっており、辞書による圧縮(重複する情報の圧縮)が行われます。
L2デルタでカラム型に変換されたデータは、次にメインストアにマージされます。メインストアではさらに高度な圧縮や高速アクセスのための辞書のソート配置、列の中の特定データの位置をすぐに指し示すための転置インデックスの配置などが行われます。
L1デルタにはおおむね1万から10万件のデータが保持されることが想定され、L2デルタにはおおむね最大1000万件のデータが保持されることが想定されています。メインストアには、それ以上の全データを保存することが想定されます。L1デルタからL2デルタ、L2デルタからメインストアへの変換は、すべてマルチコアを活用したバックグラウンド処理で行われます。
これが、カラム型データストアで高速にデータの追加削除更新を行うHANAの仕組みです。
カラム型データベースに対して直接、追加削除更新などを行うのではなく、その手前に従来のデータベースと同じ行指向のデータベースを置き、そこでとりあえず高速に処理を済ませてしまう。その後バックグラウンドでカラム型データベースへ変換する。
デルタバッファを使うこの仕組みは、マルチコアを搭載した現代のCPUの能力を最大限に引き出せるインメモリデータベースだからこそ実装できたといえます。そしてこれが、カラム型データベースエンジンで高速にデータの追加削除更新などを伴うトランザクション処理を高速に実現するHANAのポイントになっているのです。
カラム型データベースを選んだのはデータの圧縮率ゆえか
なぜHANAは、このような複雑な機構を加えてまでカラム型データベースにトランザクション処理を組み込んだのでしょうか? 逆に、従来の行指向型データベースのままインメモリデータベースにしてしまえば、トランザクションも集計処理もどちらも同時に劇的に速くすることを、シンプルなままのアーキテクチャで実現できたのではないでしょうか?
その大きな理由はデータ圧縮にあると考えられます。インメモリデータベースの大きな課題は、高価なメインメモリ上に大規模なデータベースを載せなければならないため、データベースの圧縮に高い効率が求められる点です。行指向データベースでの行方向のデータ圧縮よりも、列指向データベースで列方向にデータ圧縮を行った方が圧倒的に圧縮率が高いのです。
実績を問われるフェーズを迎える
ここまで5回連続の記事でインメモリデータベースとカラム型データベースについて見てきました。この2つの技術を基盤にしたHANAが、インメモリデータベースの高速性を活かして、カラム型データベースにトランザクション処理の技術を組み込んだ仕組みはうまくできているな、と感心します。
SAPは米国で先週開催されたイベント「SAPPHIRE NOW」で、同社のクラウドサービスの基盤をすべてHANAをベースに構築すると発表しました。これからHANAは、その仕組みが現実にうまくいくものなのか、その実績を厳しく問われるフェーズを迎えています。期待して見守ることにしましょう。
インメモリとカラム型データベースの可能性を調べる
- インメモリデータベース、カラム型データベースは使い物になるのか? インメモリとカラム型データベースの可能性を調べる(その1)
- 従来のデータベースをメモリに載せるだけではだめなのか? インメモリとカラム型データベースの可能性を調べる(その2)
- インメモリデータベースでサーバが落ちたらデータはどうなる? インメモリとカラム型データベースの可能性を調べる(その3)
- カラム型データベースはなぜ集計処理が高速で、トランザクションが苦手なのか。インメモリとカラム型データベースの可能性を調べる(その4)
- カラム型データベースでトランザクション処理を実現するカラクリとは? インメモリとカラム型データベースの可能性を調べる(その5)
あわせて読みたい
Amazonクラウド、国内初の技術者認定試験を6月5日開催。AWS Summit Tokyo 2013の会場で
≪前の記事
カラム型データベースはなぜ集計処理が高速で、トランザクションが苦手なのか。インメモリとカラム型データベースの可能性を調べる(その4)

