
分散ストレージの整合性をいかに解決するか。プライマリ-バックアップ方式と分散コミット~クラウドコンピューティングの雲の中(その2)。NII Open House 2013
クラウドはどのような仕組みで構成されていて、この先どう進化していくのでしょうか。6月14日に開催された国立情報学研究所主催のオープンハウス「NII Open House 2013」が開催され、国立情報学研究所 佐藤一郎教授が「クラウドコンピューティングの雲の中」と題した講座を行いました。
(本記事は「クラウド事業者がテクノロジーリーダーになる理由~クラウドコンピューティングの雲の中(その1)。NII Open House 2013」の続きです)
クラウドのストレージ最大の問題、不整合をいかになくすか
世界には2種類のコンピュータしかありません。「壊れたコンピュータと、いずれ壊れるコンピュータ」です。

クラウドでは大量のサーバが使われています。Googleによるとサーバの故障率は0.55%だそうで、例えばデータセンターにサーバが50万台あるとすると、毎日2750台が壊れていることになります。
つまりクラウドでは、サーバ壊れることを前提にしてシステムを作るしかありません。それはどうやるのかというと、ソフトウェアの技術を使ってハードウェアの故障を補う、冗長性を上げるということです。
ちなみに0.55%という故障率は高い値だと思います。これはGoogleの管理が悪いというより、高度なモニタリングシステムを入れて、普通では見つからないような故障まで数に入れているためではないかと思います。
サーバの冗長性を上げるとはどういうことかというと、あるデータが1台のサーバに入っていったとき、そのデータの複製を作って別のサーバにも入れる。するとサーバが1台壊れてもほかが生きているという、これが基本的な考え方です。
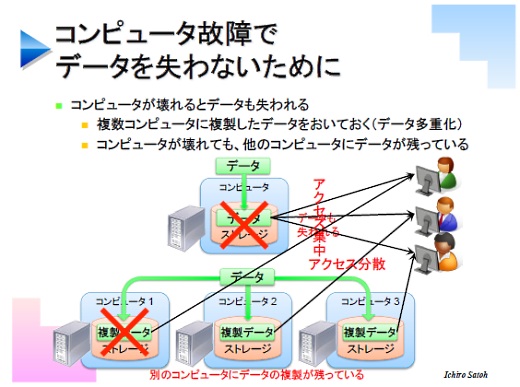
これはほかにもメリットがあります。ユーザーがデータをアクセスしにいったとき、サーバが1台だけだとそこにアクセスが集中しますが、複数のサーバに入っていればアクセスが分散できます。
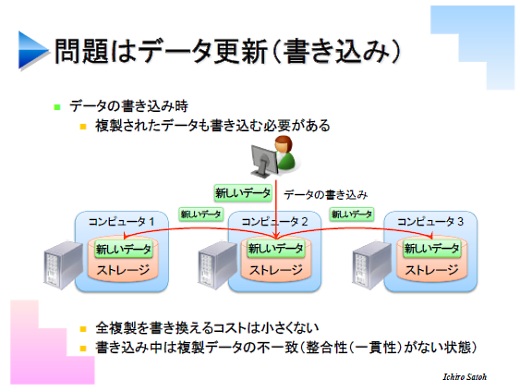
いいことばかりではありません。データの書き込みや更新のときの問題があります。あるサーバのデータを更新したときには、そのデータの複製を持っているほかのサーバにも更新されたデータを渡さなければなりません。この手間は結構大きい。
新しいデータと更新前の古いデータが混在してしまい、古いデータを参照して処理をしてしまうことで大きな問題になることもあります。クラウドではこのことをデータの整合性や一貫性と呼んでいて、この整合性をシビアに考えるか、いずれは更新されて全部新しくなる、これをEventual Consistencyと言いますが、と考えるか。どう考えるかアプリケーションごとに違います。
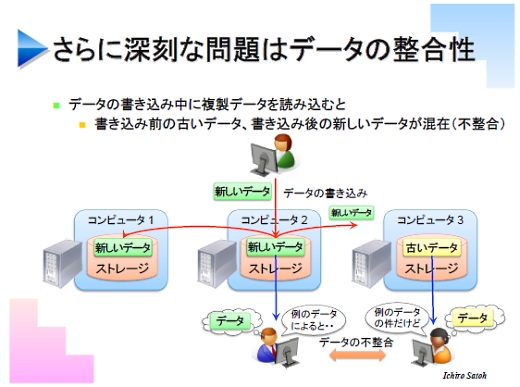
この不整合をいかに減らすか、というのが、クラウドのストレージ最大の問題です。クラウドでは複数のサーバにデータを配置することで信頼性と性能を高めていますが、データ更新時の不整合をどう解決するかという課題があります。
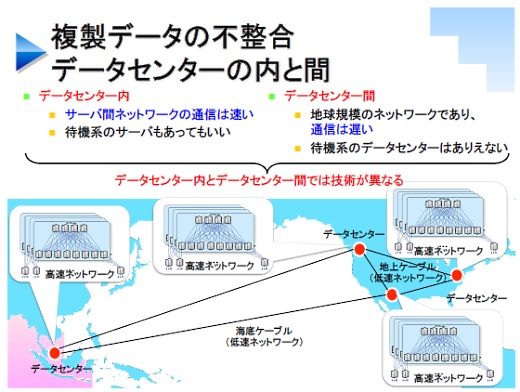
これはデータセンターの中と外では事情が異なります。データセンターの中ではネットワークは非常に高速ですが、データセンター間のネットワークは海底ケーブルなどを通るので遅い。ですので、データセンターの中と外で整合性の技術は分けて作られています。
プライマリ-バックアップ方式とROWA方式、そしてクオラム
不整合を起こさないためにデータセンターの中でよく使われている技術は、プライマリ-バックアップという方式です。データの複製をいくつか作るのですが、その1つをプライマリ、それ以外をバックアップにします。データの読み書きは必ずプライマリデータに対して行います。書き込みの場合にはプライマリデータが更新されるので、更新情報を残りのバックアップに伝えます。
単純なプライマリ-バックアップ方式では、マスターが書き換わり、それ以外のバックアップも書き換わるまではデータの読み書きをしない。ブロックすることで整合性を保ちます。
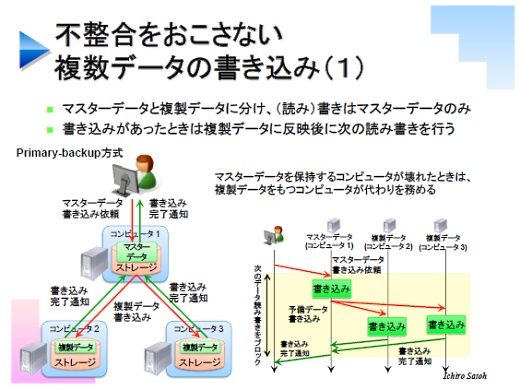
この方式では、仮にプライマリデータが壊れてもバックアップがその代わりを務められるので壊れても大丈夫、というのが基本的な考え方です。
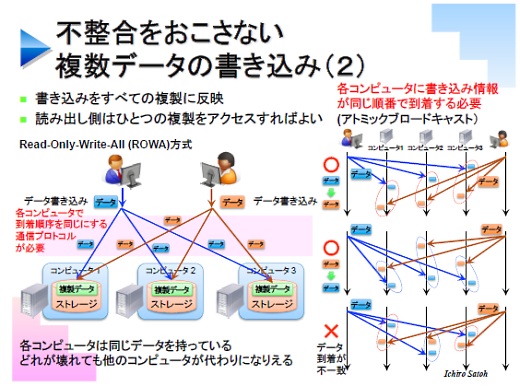
もう1つの方法が、アクティブレプリケーションとかRead-Only-Write-All(ROWA)と呼ばれる方式です。
これはマスターとそれ以外に分けずに、とにかく書き換え情報を、複製を持っている全部のサーバに伝えて更新していきます。単純に聞こえますが結構難しい方式です。
なぜかというと、ブルーとオレンジという2つデータの書き換えがほぼ同時に起きたとき、必ず全部のサーバでブルーを書き換えたら次にオレンジを書き換える、というように書き換えの順番を揃えなければなりません。順番が間違っているとバックアップにならないからです。
そのためにアトミックブロードキャストという、複数のサーバに書き換え情報を送ったときに、どのサーバでも書き換えの順番が同じになるという特殊なプロトコルを使います。
でもこの方法はコストが大きいので、サボる方法がいくつかあります。有名なのがクオラム(Quorum)という方法です。
これは全部のサーバでデータを更新するのだけでなく、一部のサーバだけ更新する。その代わりデータを読み出すときには複数のサーバから読み出すことで、負担を下げるという方法です。
例えば、5台のサーバがデータの複製を持っているときに、3台だけ更新する。読むときに3台で読むと。ただし、書き込むサーバと読み出すサーバの合計が、全体のサーバ台数より大きいというのが条件です。こうすると、少なくとも1台のサーバは書き込みと読み出しで重複します。そして書き込みのデータに順番を付けておくことで、最新の書き込み情報を選ぶことができる、という方法です。
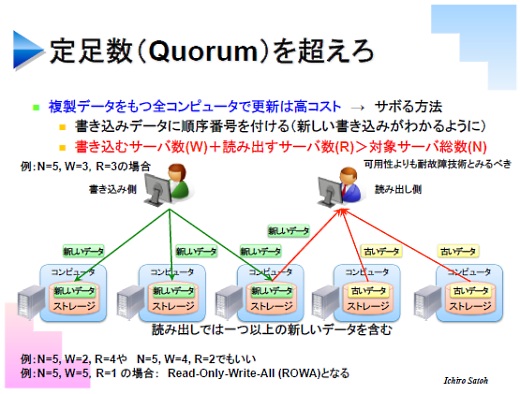
これはなかなか賢い方法ですが、運用は難しくて、でもメリットがあります。それはサーバが壊れたとき、それも遅延や挙動がおかしいといった中途半端に壊れたときにはそのサーバにアクセスしなくて済むという点です。
これがデータセンターの中での話です。数年前までは、整合性よりも性能やスケーラビリティを上げた方がいいんだとNoSQLデータベースなどが注目されていましたが、アプリケーションにとってデータ整合性がないのは扱いにくい。いまはデータセンター内のネットワークも速くなっているので、厳密な整合性を保ってもそこそこの性能がでます。
もう少し言うと、いまのボトルネックはネットワークではなくHDDの性能で、整合性を犠牲にするよりもHDDをSSDにしたほうが効果的です。そのときどきで性能向上に適した技術は変わるのです。
データセンター間は分散コミットを用いる
次にデータセンター間の話です。複数のデータセンターにデータを複製しておけば、ユーザーは最寄りのデータセンターにアクセスすることで遅延も少ないですし、自然災害などでデータセンターが壊れたときにもデータを失う危険性が減ります。
でもそのためには、世界中にデータセンターでデータの複製を持っていなければならず、データの書き換えに気をつけないとデータセンターごとに違うデータを持っている、ということになってしまいます。
整合性を保つ方法として、先ほどアトミックブロードキャストという技術を紹介しましたが、これはデータセンター間では使えません。データセンター間の通信は遅いですし、レイテンシも変動するので更新データが各データセンターに届く順番をコントロールするのは難しいのです。
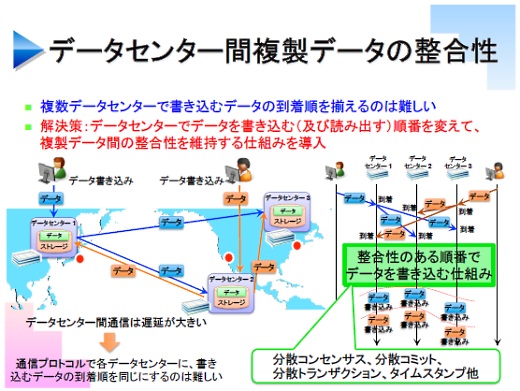
ではどうすればいいのでしょうか。それは、データセンターに更新データが届くタイミングと、実際にデータを書き換えるタイミングを分けて考えます。
いちばん典型的なのは分散コミットです。ある操作をメンバー全員でやるか、やらないか、どちらかにする。よくクラウドに使われているのが2フェーズコミットプロトコルです。これは映画の撮影をするときに監督が「レディ」と言ったらスタッフが「OK」と答えて「アクション」で撮影をするのと同じ、仮にスタッフの誰かが「ノー」といったら撮影しない。
あるデータセンターがそれ以外のデータセンターに「書き込みますか?」と聞いて、みんなからOKをもらったら、コーディネート役のデータセンターが「では書き込んでください」と言って操作が行われます。
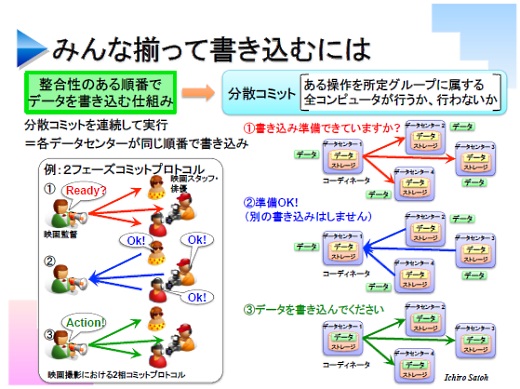
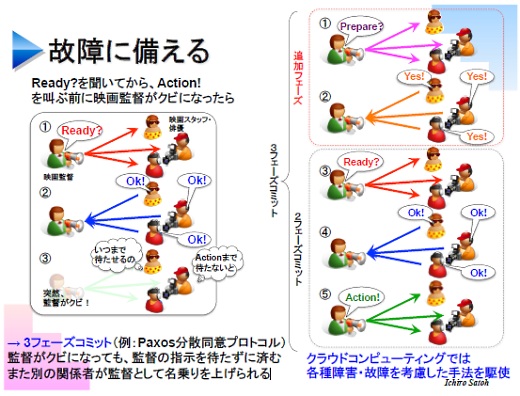
ただ、この2フェーズコミットでは、例えば監督が「レディ」と言った後で突然クビになってしまうと、ほかのスタッフがOKと返事をしたままずっと監督の「アクション」を待っている、という状態が発生します。スタッフは監督がいなくなったのか、それとも自分が「アクション」を聞き逃したのかが分からないままです。
この解決策の1つはPAXOSと言って、細かい説明は省きますが2フェーズコミットにもう1つ「レディ」「オーケー」を足した3フェーズコミットの一種です。
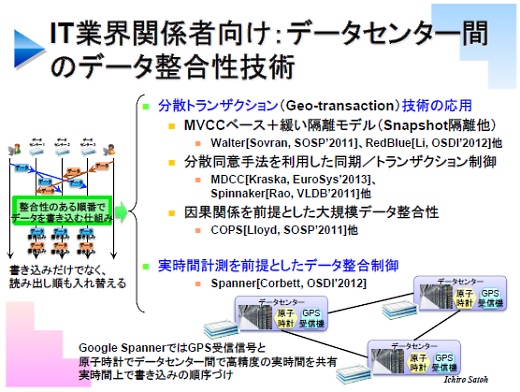
ここまででここ1~2年の研究内容に追いついてきましたが、分散トランザクションやもっと高度な方法で、いかにたくさんのコンピュータで性能よく、効率よくデータの整合性を保ちながら書き換えを行うのか、そういうことを研究しているのがいまのトレンドです。
≫次の記事「チップスケール原子時計やSoCがこれからクラウドを変えていく~クラウドコンピューティングの雲の中(その3)。NII Open House 2013」に続きます。
- クラウド事業者がテクノロジーリーダーになる理由~クラウドコンピューティングの雲の中(その1)。NII Open House 2013
- 分散ストレージの整合性をいかに解決するか。プライマリ-バックアップ方式と分散コミット~クラウドコンピューティングの雲の中(その2)。NII Open House 2013
- チップスケール原子時計やSoCがこれからクラウドを変えていく~クラウドコンピューティングの雲の中(その3)。NII Open House 2013
関連記事
2年前の2011年、佐藤教授のクラウドに関する講演。
あわせて読みたい
PR:業務アプリを超高速に開発する「Wagby」。データモデルを基に、オープンソースを基盤にしたJavaコードを自動生成
≪前の記事
クラウド事業者がテクノロジーリーダーになる理由~クラウドコンピューティングの雲の中(その1)。NII Open House 2013

