
米Yahoo!がシステムダウンしない5つの理由
昨年の10月14日、米Yahoo!のトップページがダウンしたと、米Huffington Postが記事「Yahoo DOWN: Yahoo.com Outage Reported」で伝えました。米Yahoo!にとってトップページがダウンすることはきわめてまれなことで、この件が発生するまでほぼ10年にわたりトップページのダウンは起きていなかったと言われています。
その米Yahoo!はシステムダウンを防ぐためにどのような取り組みをしているのか? 米オライリーが主催したイベント「Velocity 2011」で、Yahoo!サービスエンジニアリング部門のVice President、Jake Loomisが行ったセッション「Why the Yahoo FrontPage Went Down and Why It Didn't Go Down For up to a Decade before That」の資料が公開されています。
資料を基にポイントを紹介しましょう。
Lessons from Yahoo’s Homepage: 5 Tips for High Availability
Tip #1 あらゆるものの多重化
サーバはディスポーザブル(使い捨て)で、リブートしたりオフラインになってもユーザーへの影響はほとんどないようになっている。
コロケーションも多重化している。BCP(Business Continuity Plan、事業継続計画)シナリオをつねに実践する。プロバイダと協力し、彼らの限界を理解した上で、プロバイダが落ちたことも想定した設計をする。

Tip #2 リリースプロセスの実践
チェックインごとに自動ビルド、ユニットテスト、デプロイ、テストを行う継続的インテグレーション環境を構築する。ビルドを壊した人は「犯人はこいつ」帽子をかぶってもらう。
本番環境へのデプロイはダークローンチコードを含めておき、レビューと有効性を確認したうえでアクティベートする(参考 : Twitterの大規模システム運用技術、あるいはクジラの腹の中(前編)~ログの科学的な分析と、Twitterの「ダークモード」)。

Tip #3 グローバルなロードバランシング

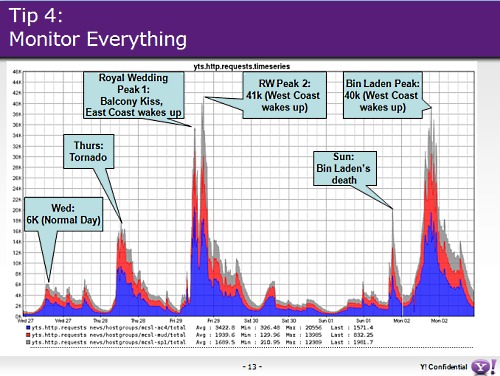
Tip #4 あらゆることをモニタせよ
予算が許すかぎりあらゆるものを測定する。
System level monitoring (per host)
End-to-end functionality (per host)
Content “freshness” (per host)
Client side performance (overall)
Server side duration (per hostgroup, per colo)
Traffic levels, week over week (per hostgroup, per colo)
Tip #5 障害発生時のフォールバックプランを持つ
アドサーバに障害が発生したら、CMS管理の広告やスタティック広告へ。ページ表示に障害が発生したらcronで生成しておいたスタティックページへ。
障害発生箇所はすぐに分離し、キャパシティが不足しているときは機能を制限する。

サービスエンジニアリング部門の責任範囲とは。

技術ですべてをまかなえるわけではない。自分がしていることに情熱を持とう。
デベロッパーは運用の敵ではなく仲間である。要件定義の段階の早い段階から運用を巻き込む。
コードをよく見て、ログをレビューし、意見を言う。運用プロセスにデベロッパーを巻き込もう。彼らは「何が起きているのか」を知りたがるはずだ。
モニタリングの結果をシェアし、意見や要望を歓迎しよう。そしてビールをおごったり仲良くすることが、長期的な関係につながる。

