
グーグルはコードの品質向上のため「バグ予測アルゴリズム」を採用している
グーグルでは、社内のプログラマによって作り出される大量のコードの品質を保つため、チェックイン前にユニットテストとコードレビューが行われているそうです。しかし、コードが大量になってくると、ユニットテストやレビューをすり抜けるバグも少なからず発生します。
そこでコードの品質をさらに高めるために、グーグルでは「バグ予測アルゴリズム」を採用。バグがありそうな部分をレビュアーにアドバイスする仕組みを採用したとのこと。
そのバグ予測アルゴリズムとはどんなものなのか。Google Engineering Toolsブログに投稿されたエントリ「Bug Prediction at Google」(グーグルにおけるバグ予測)で説明されています。
ソースコードの修正履歴を基に予測
コードの中にバグがありそうな箇所を分析する手法としては、「ソフトウェアメトリクス」がよく用いられます。これはコードを静的に分析して、モジュールや関数の行数、ネストの深さ、モジュール間の依存関係が多いか少ないか、といったことを数字に置き換え、そのスコアを見てバグが起きやすい箇所を推測する方法です。ソフトウェアメトリクスのためのツールは、さまざまなベンダから市販されています。
しかしグーグルが用いたのはもっとシンプルな方法でした。ソースコードの修正履歴を基にバグ予測をすることにしたのです。
Well, we actually have a great, authoritative record of where code has been requiring fixes: our bug tracker and our source control commit log! The research (for example, FixCache) indicates that predicting bugs from the source history works very well, so we decided to deploy it at Google.
そう、私たちはコードのどこが修正を必要とされてきたかという、本物の記録を持っています。それはバグトラッカーとソース管理のコミットログです。例えばFixCacheなどの研究によると、ソースコードの履歴を元にしたバグ予測は非常にうまく働きます。そこでこれをグーグルで運用することにしました。
それは、過去にそのコードがバグフィックスのため、いつ、何回修正されたか、という情報を基にした実にシンプルなアルゴリズムです。
They found that simply ranking files by the number of times they've been changed with a bug-fixing commit (i.e. a commit which fixes a bug) will find the hot spots in a code base. Simple! This matches our intuition: if a file keeps requiring bug-fixes, it must be a hot spot because developers are clearly struggling with it.
彼らが発見したのは、そのコードに対してこれまでバグフィックスのコミットが何回行われたかをランキングすることで、コードの中のホットスポットを見つけられるだろう、というものです。まさにシンプル! そしてこれは私たちの直感、もしも何度もバグフィックスが必要なファイルはデベロッパーが苦労しているところだからホットスポットに違いない、というものにマッチするのです。
試行錯誤の結果、グーグルは以下の式を導き出しました。前述のブログから引用します。
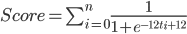
eはネイピア数です。右辺の分数が分かりにくいので、以下に書き直しておきます。
1/(1+exp(-12×ti+12))
nは、コードに対してバグフィックスが行われた回数を示します。tiは修正が行われた時点のタイムスタンプで、コードが生成されたときを0、現在を1と置いて、その間の少数値をとります。つまり、12月1日にコードを書き始め、今日が12月30日であるとすると、15日にバグフィクスをしたらti=0.5になります。
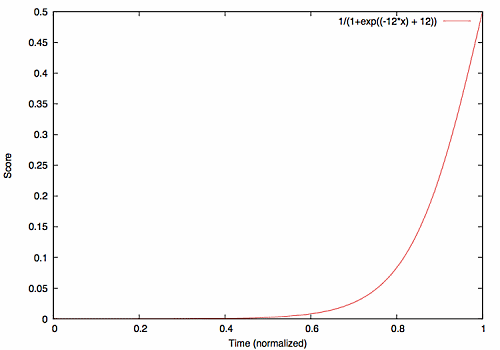
ti=0のとき、1/(1+exp(-12×ti+12))≒0 となり、
ti=1のとき、1/(1+exp(-12×ti+12))=0.5 となります。
右辺のtiをxと置いてグラフを描くと以下のようになります。最近のタイムスタンプほど急激に値が大きくなります。このグラフも前述のブログから引用します。
右辺には合計を表すΣがありますので、複数回バグを修正したのなら、その修正ごとにタイムスタンプの値をtiに入れて計算し、それを全部合計したのがスコアとなります。
つまり、より高頻度にバグを修正し、かつ最近になって集中的に直しているほど、スコアが大きくなります。そしてスコアが大きいほど、相対的に見てそのコードにはバグがある可能性が高い、というのがこのアルゴリズムが示すところです。
マイクロソフトリサーチでも研究が
コードの変更回数などのメトリクスを用いてバグの発生を予測するという研究は、以前の記事「「少人数のチームの方がソフトウェアの品質は高い」実証的ソフトウェア工学の研究会が開催」で、マイクロソフトリサーチのDr. Thomas Zimmermann氏の研究を紹介したことがあります。
このときのパラメータは、以下の4つでした。
- 変更の回数
- 変更を行った開発者の人数
- 会社を辞めた人数
- 関係者のまとまり
ここでもやはり変更の回数が含まれており、バグを発見するのに重要なパラメータであるということが示されています。
こうしたソフトウェアメトリクスなどをコードの品質向上を活用している現場というのは、あまり多くないようです(解析ツールも比較的高価なものが多いからかもしれませんが)。しかしプログラマが自分の技術を駆使して品質向上をはかるのは自然なこと。この機会にソフトウェアメトリクス(あるいはソースコード解析など)が注目され、デベロッパーの生産性向上につながるといいのですが。
追記:Googleはこのアルゴリズムを実装したツールをオープンソースで公開しました。

