
マイクロプロセッサはこの先どのように進化するのか?
コンピュータの分野で最も有名な学会であるACM(アメリカ計算機学会)のWebサイトで「The Future of Microprocessors」(マイクロプロセッサの未来)という記事が公開されています。
インテルのShekhar Borkar氏とAndrew A. Chien氏によって執筆されたこの記事は、クロック速度の上昇などによる性能向上の限界を迎え、マルチコアによる性能向上へと舵を切り始めたマイクロプロセッサがこの先どのような進化をたどろうとしているのかが説明されています。
長い記事なのですが、マイクロプロセッサの変化はソフトウェアにまで影響を及ぼそうとしており、多くのITエンジニアが興味を持ちそうな中身になっています。ポイントを紹介していきましょう。
電力消費量が性能に制限をもたらす
記事ではこれまでにマイクロプロセッサの進化を振り返り、現在が大きなターニングポイントであることを示しています。
The transistor-scaling-and-microarchitecture-improvement cycle has been sustained for more than two decades, delivering 1,000-fold performance improvement. How long will it continue?
トランジスタの規模とマイクロアーキテクチャの改善が20年ものあいだ繰り返され、1000倍もの性能向上を実現してきた。これはどこまで続くのだろう?
この疑問の答えは以下の図に示されています。プロセスルールの精緻化が進むにつれて性能向上の度合いがどんどん下がっているのです。単純にトランジスタを増やし、クロック数を高めるといった従来の方法では、これまでのような性能向上は望めなくなってきていることを示しています。
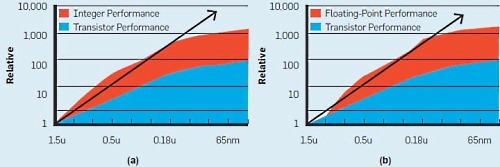
では、この先のマイクロプロセッサの進化はどうなるのでしょうか?
Microprocessor technology has delivered three-orders-of-magnitude performance improvement over the past two decades, so continuing this trajectory would require at least 30x performance increase by 2020.
マイクロプロセッサの技術は過去20年で3桁もの性能向上を果たしてきた。この勢いを続けるとすれば、2020年までに30倍の性能向上が必要となる。
これまでプロセッサの性能向上を引っ張ってきたクロック数向上の代わりに、いまはコア数の増大へと向かっています。しかしこのままコアを単純に増やしていけば性能向上につながるというわけにも行かないようです。
If chip architects simply add more cores as transistor-integration capacity becomes available and operate the chips at the highest frequency the transistors and designs can achieve, then the power consumption of the chips would be prohibitive.
もしチップアーキテクトがトランジスタの統合が可能な限りコアを増やしていき、そして可能な限り高い周波数で稼働させようとすると、電力消費量が跳ね上がっていくことになる。
Chip architects must limit frequency and number of cores to keep power within reasonable bounds, but doing so severely limits improvement in microprocessor performance.
電力消費を適切な範囲に収めるためには、チップアーキテクトはコア数と周波数を制限せざるを得ないだろう。しかしそれはマイクロプロセッサの性能向上への厳しい制限となる。
クロック数の向上も難しく、単純なコアの増加にも上限があるとすれば、今後どのような方法でマイクロプロセッサの性能向上は実現されるのでしょうか? 記事ではいくつかの項目が挙げられています。
Organizing the logic: Multiple cores and customization.
ロジックの組織化:マルチコアとカスタマイゼーション。
マルチコア化にもいくつかの選択肢があります。例えば150万トランジスタを用いた場合、以下の3つの選択肢があります。
option (a) is six large cores (good single-thread performance, total potential throughput of six); option (b) is 30 smaller cores (lower single-thread performance, total potential throughput of 13); and option (c) is a hybrid approach (good single-thread performance for low parallelism, total potential throughput of 11).
選択肢aは、6つの大きなコア(高性能なシングルスレッド性能で、合計のスループットが6倍)。選択肢bは、30の小さなコア(シングルスレッド性能は低いが、合計のスループットが13倍)、選択肢cはハイブリッドなアプローチ(小さな並列性のため高性能シングルスレッドで、トータルのスループットが11倍)
こうした中から有望な選択肢を選ぶこと。そしてもう1つがハードウェアカスタマイゼーションです。
Customization includes fixed-function accelerators (such as media codecs, cryptography engines, and compositing engines), programmable accelerators, and even dynamically customizable logic (such as FPGAs and other dynamic structures).
カスタマイゼーションには、特定機能用アクセラレータ(メディアコーデック、暗号化エンジン、複合エンジン)、プログラマブルアクセラレータ、それに動的カスタマイズ可能なロジック(FPGAやそのほかの動的構造)を含む。
In general, customization increases computational performance by exploiting hardwired or customized computation units, customized wiring/interconnect for data movement, and reduced instruction-sequence overheads at some cost in generality.
一般に、カスタマイゼーションはハードワイヤやカスタマイズされた計算ユニット、データ転送のためのカスタマイズされたワイヤリング/インターコネクトによって計算性能を向上でき、通常の計算コストにかかるオーバーヘッドを減じられる。
並列性に関するカスタマイズにも触れられています。
Another customization approach constrains the types of parallelism that can be executed efficiently, enabling a simpler core, coordination, and memory structures;
もう一つのカスタマイゼーションのアプローチは、よりシンプルなコア、協調動作、メモリ構造を可能にし、効率的に実行できるように並列性の種類を制限することである。
このように、コア数をどのように増やしていくのか、そしてそのコアをどのような役割にするのかが、マイクロプロセッサの性能向上のカギの1つになると説明されています。
Orchestrating data movement
プロセッサ内のデータ転送。
Today's processor performance is on the order of 100Giga-op/sec, and a 30x increase over the next 10 years would increase this performance to 3Tera-op/sec. At minimum, this boost requires 9Tera-operands or 64b × 9Tera-operands (or 576Tera-bits) to be moved each second from registers or memory to arithmetic logic, consuming energy.
今日のプロセッサ性能は100Giga-op/secの桁である。そして次の10年で30倍の性能向上があるとすれば、少なくとも3Tera-op/secとなる。この性能向上を果たすには、9Tera-Operandsもしくは64b × 9Tera-operands (あるいは576Tera-bits)を毎秒ごとにレジスタかメモリから計算ロジックに移動しなければならず、そこに電力消費が発生する。
プロセッサ内のデータ転送が桁違いに増大することから、そこにかかる電力消費量について目を向けなくてはならなくなる、というのです。そのためにプロセッサ内のデータ転送アーキテクチャについて改善が必要になるとのこと。
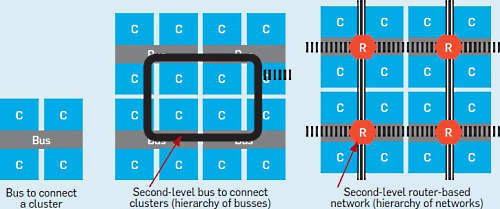
Figure 12 describes a return to hybrid switched networks for on-chip interconnects. Small cores in close proximity could be interconnected into clusters with traditional busses that are energy efficient for data movement over short distances. The clusters could be connected through wide (high-bandwidth) low-swing (low-energy) busses or through packet- or circuit-switched networks, depending on distance.
図12(以下の図)は、オンチップインターコネクトのためのハイブリッドスイッチネットワークへの回帰を示している。近接する小さな複数のコアはこれまでのようなバス構造でクラスタとして相互接続される。これは近接しているので電力効率もよい。
クラスタ間は広帯域で低消費電力のバスもしくはパケットかスイッチネットワークによって接続される。これは距離に依存する。
Software challenges renewed: Programmability versus efficiency
新たなソフトウェアの挑戦:プログラマビリティか、効率か
The end of scaling of single-thread performance already means major software challenges; for example, the shift to symmetric parallelism has created perhaps the greatest software challenge in the history of computing, and we expect future pressure on energy-efficiency will lead to extensive use of heterogeneous cores and accelerators, further exacerbating the software challenge.
シングルスレッド性能の向上が終わったことは、すでにソフトウェアでの大きな挑戦が始まったことを意味している。例えば、シンメトリックな並列性への変化はおそらくコンピューティングの歴史上、ソフトウェアでの最大の挑戦だ。そして将来やってくる電力効率のプレッシャーは、ヘテロジニアスなコアやアクセラレータの拡大へとつながり、それはソフトウェアの挑戦をさらに拡大するだろう。
マルチコアをうまく性能向上につなげるには、ソフトウェアによる並列性を高めたプログラミングが不可欠であると同時に、ここでは「ヘテロジニアスなコアやアクセラレータ」と表現されている、前述のカスタマイズされたコアを使いこなすのもソフトウェアの役目であることが強調されています。
並列処理がコンピューティングの歴史上最大のチャレンジであることは以前の記事「コンピュータサイエンス史上最大の課題「並列処理による性能向上」~情報処理学会創立50周年記念全国大会の招待講演」でも、女性で初めてチューリング賞を受賞したIBMのFran Allen氏が指摘していました。
そのためには既存の言語のコンパイラを改良するにとどまらず、あらたな言語やフレームワークといったもの、あるいは並列性を最初から意識したソフトウェアアーキテクチャといったものが必要になってくるかもしれません。
プロセッサを搭載したサーバそのものが変化を始める
記事「The Future of Microprocessors」の内容を中心に将来のプロセッサの姿について書いてきましたが、今後10年、20年を考えると、プロセッサを内蔵したサーバそのものも大きく変化することは間違いありません。
手短に言えば、Infinibandやイーサネットなどの高速化が進んだ結果、サーバの筐体を超えてプロセッサやメモリを融通するようなクラスタ全体が密結合したような柔軟なシステムが登場してもおかしくないのです。その上にハイパーバイザを載せたら、複数台のサーバをまとめて大量のコアとメモリを積んだ1つの巨大な仮想マシンに見える、なんてことだって十分にありえます(それを何に使うんだ、というのは置いておいて)。
長くなるのでこの話はまた別の機会に書こうと思いますが、サーバやプロセッサのアーキテクチャは今後数年で大きく変化しようとしていますし、その変化はクラウドやネットワーク、そしてソフトウェアの姿でさえ大きく変えるほどのインパクトを秘めています。

