
PaaSの動向(後編):PaaSのスケーラビリティとマルチテナント方式の違い
先週10月13日にクラウド利用促進機構(CUPA)というNPOが主体となって「オープンクラウドキャンパス」というイベントが開催されました。テーマはPaaSです。
僕はそのイベントの冒頭で「PaaSの動向」についてプレゼンテーションをしてもらえないか、と依頼をいただきまして、お話をしてきました。
この記事は、そのプレゼンテーションの内容を紹介したものです。本番では時間があまりなくて省略した部分もあったので、記事化にあたってはそうした点の補足もしました。
本記事は「PaaSの動向(前編):初期のPaaSは完成度が高いがロックインされやすい」の続きです。
ベニオフ氏対エリソン氏、対決の中身を知る
最近のPaaSの動向で欠かせないトピックが、マーク・ベニオフ氏とラリー・エリソン氏の師弟対決です。

ベニオフ氏は「クラウドだと言って箱を売ってる会社がある。偽のクラウドに気をつけろ!」と数年前から言っていました。先週エリソン氏がオラクルのクラウド参入の発表でこれに反撃したのです。「偽のクラウドに気をつけろ? たしかにその通りだ。ただし独自言語で囲い込んで、仮想化の分離もしておらず、リソースに制限もあるようなクラウドは、そっちの方が偽物だろう!」と。
次にベニオフ氏がどう反論するのかなど、この対決そのものも面白いのですが、エリソン氏が指摘していることを少しよく見てみると、PaaSが抱える課題が見えてきます。
そこで、PaaSの抱える課題「スケーラビリティをどうするか」と「テナント分離をどうするか」の2つを見てみます。
スケーラビリティをどう解決するか
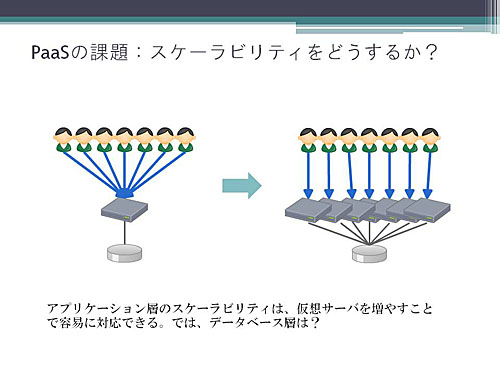
PaaS上のあるアプリケーションに多数のアクセスがあったとします。このとき通常はアプリケーション層を実行するインスタンスを増やすことで対応します。
アプリケーション層はこうして比較的容易にスケーラビリティを実現できるのですが、データベース層はどうでしょう? PaaSによってデータベース層のスケーラビリティを実現する方法は異なります。
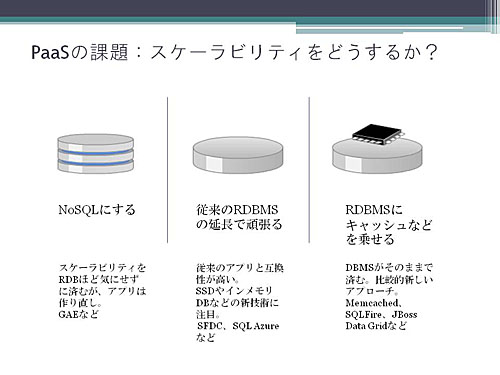
データベース層のスケーラビリティを実現する方法の1つは、NoSQLにしてしまうことです。シンプルな方法ですがアプリケーションはNoSQL用に作り直しになるでしょう。
リレーショナルデータベースの延長線上で頑張る、という方法もあります。最近ではFusion-IOのようなSSDの採用や、インメモリデータベースのような新しい技術を採用するなどでリレーショナルデータベースのスケーラビリティを高めることも行われています。
いちばん右の方法は、リレーショナルデータベースの上にキャッシュを載せる方法です。これの利点は今までのリレーショナルデータベースがそのまま使えるところですね。キャッシュはMemcachedなどがよく知られていますが、SQLがそのまま使えるVMwareのSQLFireや、レッドハットのJBoss Data Gridなどの製品も出始めています(セールスフォース・ドットコムは独自キャッシュを乗せているため、真ん中より右側に近いだろう、という情報をツイートでいただきました)。
そしてもう1つの課題がテナントの分離です。
テナント分離をどう解決するか?

パブリッククラウド上でA社、B社、C社がPaaSを利用した場合、A社のデータをB社がアクセスできては困ります。B社のアプリのクラッシュがC社に及んでも困ります。こうしたテナントの分離をどうするのかが課題です。これもPaaSによっていくつかの選択肢があります。
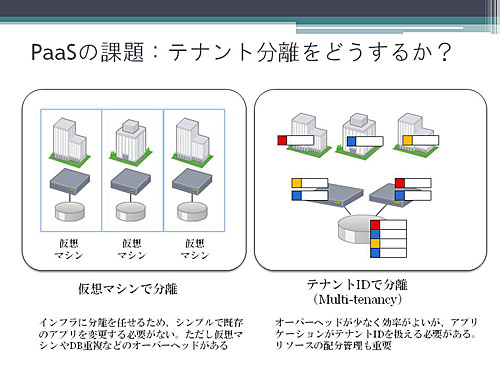
左に示したのが、仮想マシンによってテナントを分離する方法です。シンプルな方法で、従来のアプリケーションもそのまま動きます。ほとんどのPaaSはこの方式です。
しかし、例えば1つの物理サーバにA社、B社、C社を乗せる場合、それぞれにOSやミドルウェアやデータベースサーバが重複して稼働するため、メモリやプロセッサの利用効率が悪く、一般にチューニングなども難しい方式でもあります。
右側は、テナントIDで分離する方式です。この場合、アプリケーションが取り扱うデータには会社ごとにすべてテナントIDが付き、A社は自動的にA社のテナントIDが付いたものだけが参照、操作できるようになっています。
ただし同一プロセスの中で複数のテナントが同居するため、特定のテナントが重い処理を始めるとすぐに別の会社の処理にも影響が出始めます。そこで、テナントが重い処理を始めたらそれを止めたりするリソース管理も必要ですし、アプリケーションがクラッシュしないようなプラットフォーム上の工夫も必要です。また、この場合、プラットフォーム全体でテナントIDを扱うように設計しておく必要があるため、既存のアプリケーションがそのまま動くことは望めません。
セールスフォース・ドットコムはこのテナントID方式をとっていることがよく知られていて、Force.comでは検索結果が大量になるような重い処理などに「ガバナ制限」と呼ばれる制限がかかっています。
エリソン氏が「仮想マシンで分離しておらず、リソースに制限もある」と言っているのはこうしたことを指摘しているのです。
しかしテナントID方式は仮想マシン方式に比べて仮想マシンのオーバーヘッドやプロセスの重複などがないため非常に効率のよい方式です。
ベニオフ氏は以前、セールスフォース・ドットコムは全部で3000台のサーバしかなく、しかも半分はディザスタリカバリ用なので実質1500台で稼働している、と言っていました。これで約8万社のユーザーに対応できているわけで、自慢するだけのことはある驚異的な効率性の高さだといえます。
仮想マシン方式とテナントID方式を合わせた方式もありえます。
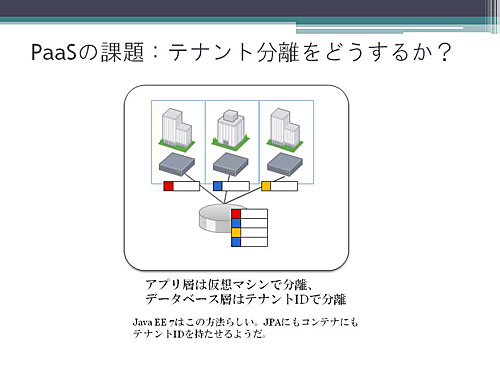
先週発表されたJava EE 7のアーキテクチャは、どうやら上記のようにアプリケーション層は仮想マシンで分離し、データベース層はJPAにテナントIDを持たせてテナントID方式にする、というような方式をとっているらしいことが、JavaOneの発表から読み取れました。

さて、PaaSは範囲が広いので、最後にここまでで触れられなかった動向についても少し紹介しておきます。
1つはほかのデータやアプリとの連係も重要になるだろうということ。例えば顧客管理アプリを作るとすれば、帝国データバンクやD&Bのような企業情報データベースと連係したくなります。セールスフォース・ドットコムはそのためにJigsawという会社を買収したりしていますし、これからはアプリケーションとソーシャルメディアの連係なども増えてくると思うので、そういう環境を整えることがPaaSでも大事になってくるのではないでしょうか。
それから、PaaSでアプリケーションを作ると、それを売りたくなる企業は多いはずです。アップルがAppStoreで開発者を引きつけたように、クラウド上のアプリケーションマーケットの展開は、PaaSに開発者を引きつける上で大事になってくるでしょう。
PaaSはプログラミングやデータベース、それにインフラのことも関わってくる多様な技術の積み重ねで、これからさらに多数の技術が関わってくると思います。PaaSを選び、活用するにはそうした情報収集がこれからさらに大事になってくるはずです。

