
OpenFlowはなぜ生まれたのか? 開発者マーチン・カサード氏によるOpen Network Summit 2011基調講演(前編)
ネットワークの機能をソフトウェアで定義してしまおうという「Software Defined Network」(SDN)をテーマにしたイベント「Open Networking Summit」が、10月17日から米国スタンフォード大学で開催されました。
SDNはいまネットワーク業界でもっとも熱いテーマであり、今年3月にはグーグル、マイクロソフト、Yahoo!、FacebookらがSDNを推進する団体「Open Networking Foudation」を結成しています。
そのSDNを実現する技術とされているのが「OpenFlow」。Open Networking Summitの基調講演では、OpenFlowの開発者であるマーチン・カサード(Martin Casado)氏が登壇し、OpenFlowの開発の経緯、アーキテクチャ、そしてそのインパクトについて解説を行いました。カサード氏は現在、Nicira NetworksのCo-Founder&CTOです。
公開されている基調講演のビデオから、内容のポイントを紹介しましょう。
Origins and Evolution of OpenFlow/SDN
Martin Casado氏。
今日はOpenFlowについて歴史物語風に説明しようと思う。また、OpenFlowについてのよくある質問にも答え、その後で、なぜOpenFlowがこれだけ成功してるかよく考えてみたい。今後もこの成功を続けるためにはどうすればいいかについてもね。

OpenFlow以前。2002年~2003年頃、僕は国防省のインテリジェントセクターで仕事をしていた。米国内でもすごくセンシティブなネットワークをセキュアに管理していた。ここに侵入されたら文字通り人々が死んでしまうような重要なものだったから、真剣だった。
指令は単純で、ネットワークに対してポリシーを適用すること。ただしネットワークは稼働させたまま。それだけなのにすごく難しくてショックだった。
例えば、ルータにポリシーを適用しつつ可用性も維持したいので、ポリシーをレプリケートできるようにシンメトリックなトポロジーが必要だという制約があったし、一方でエッジでは別のポリシーが要求された。
さらにマシンを追加したり移動するたびに、ポートセキュリティ、VLAN、ACLなどなど8カ所ものステートを変更しなければならなかった。だからマシンを移動するような変更には数時間かかった。ルーティングはすぐに対応できたとしても、人間による設定はそうではなかったから。
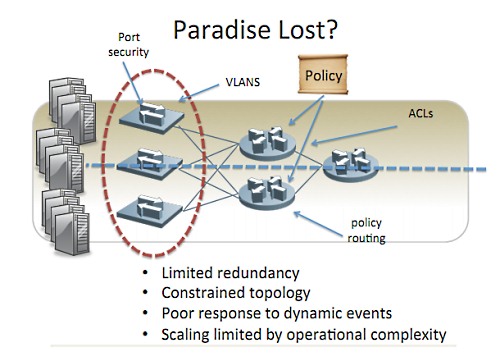
つまり自分たちが作ったネットワークシステムは、自分たちの管理能力によって制限されてしまっていたのだ。
あの頃も、そして今も信じているが、おそらくこれはまだ起きていない進化の途中にあることなんだ。だから次はそれについて話そう。
人間はネットワークのステート管理が苦手だ
ここに僕が理想とするスイッチのパイプラインがある。
パケットがやって来て、いろんなテーブルへと流れ込む。テーブルがパケットの運命を決める。このパケットはドロップされるのか、フォワードされるのか、複製されるのか、とかね。そしてパケットは出口から出て行く。
これがネットワークのすべてだ。
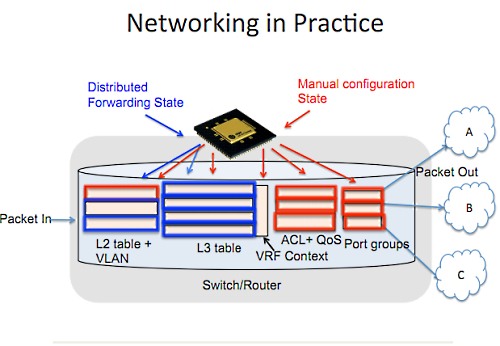
これらのテーブルのうち一部は、ダイナミックなルーティングアルゴリズムを使って設定される(L2 tableやL3 tableのこと)。それぞれのノードで変更され、あるいはほかのノードと通信を行うだろう。ネットワークがこれだけなら、スケーラブルだし冗長性や可用性も備えた素晴らしいものだろう。
でもほかに考えなければならない。ACLやQoSやタギングなどだ。ここは人間によって設定される、あるいはスクリプトによってかもしれない。
問題は3つある。
まず、人間はネットワーク上のステートの管理が苦手だ。ルーティングアルゴリズムはステート管理が得意で計算も速い。もしもネットワークのプラグが抜けたら、ルーティングはすぐにアルゴリズムによって別ルートへ修正するけれど、人間ならポケベルが鳴って、ああ修理に行かなくちゃ、みたいになる。
人間が苦手だったら、そこはプログラムにやってもらおう。そこで僕らはそうしたことができるスイッチを探し始めた。でも、そのころはプログラムを作りたくても、そのために定義されたAPIがなかった。もしもあったとしても、ステートをディストリビュートするのにどんなアルゴリズムが正しいのか、まだ明らかになっていなかった。

理想的なセキュアネットワークとは、下位のトポロジーなどとは切り離され、最上位レベルでポリシーを定義できる言語がある。そしてその定義が自動的に実際のネットワークに適用される。これこそネットワークの楽園のようなものだ。
だとすると、こういうアーキテクチャを実現するには純粋な分散環境に対応したデータログコンパイラを構築する方法を考えなくてはいけなかった。
僕は政府の仕事からスタンフォードに向かうことになり、Nick(Nick McKeown)やScott(Scott Shenker)と一緒にこの問題に取り組むことができてすごく幸運だった。
ネットワークはプログラムできるようには進化してこなかった
2004年から今まで、OpenFlowの開発期について。
どうすればネットワークをプログラムできるか、ということは、ネットワーク内のデータパスのステートをどうしたらプログラミングできるか、ということ。これが僕らが解決したかった問題だ。
4年間の研究で2つの結論にたどり着いた。
まず1つは、ネットワークはプログラムできるようには進化してこなかった、ということ。L2やL3などでよく使われていた多くのアルゴリズムはハードウェアに固定されていた。スイッチのチップには多くの機能が固定されていたけれど、僕たちは汎用的なプログラミング環境を作りたかった。
もう1つは、スイッチのSDKが入手できたとしても、チップの中身がそのまま露出しているようなものだったこと。だから知る限り、この時期にステートを操作できる一貫したAPIというものはなかった。
だから最初に提案したのが、まずデータの経路を汎用化すること。ハードウェアに固定された機能ではなく、柔軟なテーブルを用いる。これがFlow Tableだ。
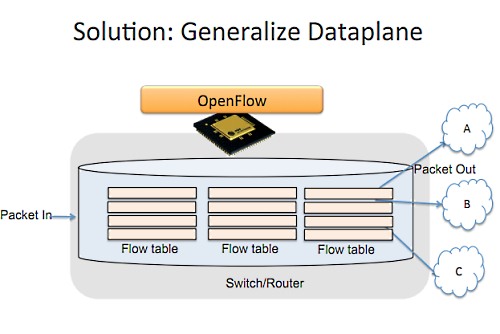
そして次に、それらをソフトウェアでコントロールするためのディストリビューションモデルを、トポロジーから切り離す。
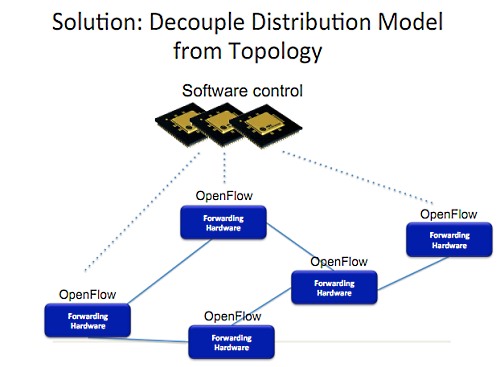
これが僕たちが最終的に到達した結論だ。汎用化されたハードウェアに抽象化レイヤを乗せる。これで上位レベルのインターフェイスが実現できる。コントロールロジックは分離されていて、ロジックはどんなディストリビューションモデルでも配布できる。その上に、僕が構築したポリシーコンパイラが乗るというわけだ。
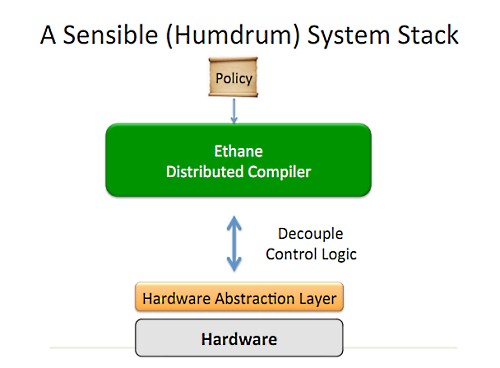
OpenFlowのモデルはNetwork OSのモデル
OpenFlowが登場する前はスイッチを入手するのが困難だったから、Fry'sに行って安いサーバを買っていた。だからこれらが初期のプロトタイプだ。OpenFlowの祖先は、x86ボックスの山だった。

ここからNetwork OSを考え付くのは自然なことだった。これらのほとんどは2007年にはできていて、これがNOX(OpenFlowコントローラのオープンソース実装)などになって現在に続くんだ。
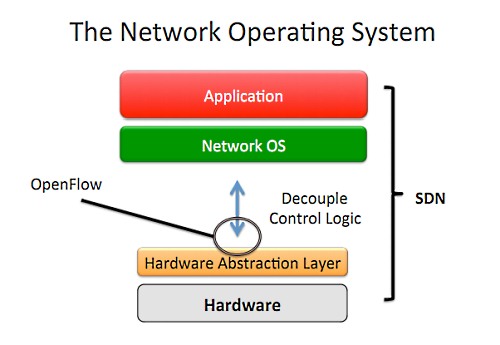
OpenFlowはこの抽象化レイヤの上のインターフェイスで、使いやすく、標準化された重要なものだ。
次の記事に続きます。「OpenFlowはイノベーションの速度を上げる。開発者マーチン・カサード氏によるOpen Network Summit 2011基調講演(後編)」。
OpenFlow関連記事
あわせて読みたい
OpenFlowはイノベーションの速度を上げる。開発者マーチン・カサード氏によるOpen Network Summit 2011基調講演(後編)
≪前の記事
連載マンガ:Mr. Admin「Excelの計算を電卓で確認してみる」

