
DeNAによる大規模なMySQLノンストップ運用の裏側にある、フェイルオーバー自動化ツール
4月11日から米サンタクララで行われた「MySQL Conference & Expo 2011」。このイベントでDeNAの松信嘉範(まつのぶよしのり)氏が、同社の大規模なMySQLの運用を支えている技術とツールについてのセッション「Automated, Non-Stop MySQL Operations and Failover」を行いました。
プレゼンテーションの中で、社内で利用しているフェイルオーバーの自動化ツールをオープンソース化することにも触れています(英語のドキュメントも作成中とのこと)。
MySQLの大規模運用における自動フェイルオーバーは、特にクラウドでのMySQLの利用が増えるにつれてニーズが高まる分野と思われます。セッションのスライドが公開されていますので、そのポイントを紹介していきます。
自動化されたノンストップなMySQLの運用

ソーシャルゲームでは高可用性が強く求められている。課金サービスでは利用者からの要求は厳しく、ダウンが長引けば業績にネガティブなインパクトを与える。

そこで目指すのは「No Single Point of Failure」(単一障害点がないこと)だ。
DeNAでは700以上のMySQLを運用しており、150以上のMaster/Slaveのペアが構成され、主にMySQL 5.0/5.1を利用している。そして統計的にみて数カ月に1度マスターが落ちている。原因はLinuxかハードウェアが原因。できればこのとき、ダウンタイムを最小にするためにマニュアルでのフェイルオーバー操作をなくしたい。
しかしMasterを非単一障害点化するのは難しい。SlaveをMasterに自動的に昇格させる仕組みを、通常のMySQL 5.0/5.1/5.5以上で構成したい。

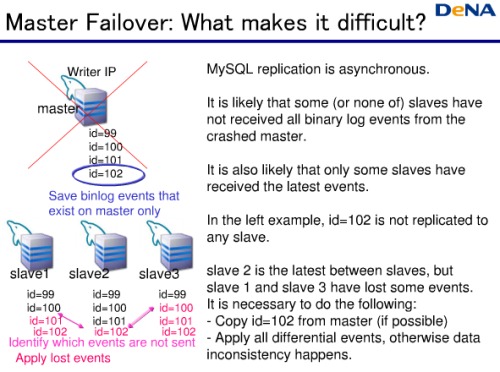
フェイルオーバーのときに発生する課題がある。MySQLのMasterからSlaveへのレプリケーションは非同期なため、Masterがダウンしたときに、まだSlaveにレプリケートされていないデータがあるのだ。
例えばこの図ではid=102がレプリケートされていない。Slaveごとにどこまでレプリケートされているか状況も異なる。もっとも最新のSlaveを見つけ、他のSlaveと同期させる必要があるのだ。
現在ある高可用性のソリューションについて。Heartbeart+DRBDは書き込み性能が落ちるなどの問題がある。MySQL Cluserは、残念ながらInnoDBを使っているので採用できず。

そこで、高可用性の目的を達成するにはどうすればよいか。Masterが落ちたときにスレーブを昇格させてフェイルオーバーさせる。手順としては、可能ならMasterからbinary log eventsを救済し、最新のSlaveを見つけ、ほかのSlaveとの差分を更新。救済したログを当て、Masterに昇格させ、新Masterに対してSlaveのレプリケーションを開始する。
これを自動化していく。

(ここから20枚以上のスライドを使って、上記を技術的にどう解決するのかの詳細が解説されています。興味のある方は記事末のスライドでぜひご確認ください。この部分がこのセッションの核心ではあるのですが、記事で紹介するにはテクニカルすぎるので省略させていただきます……)
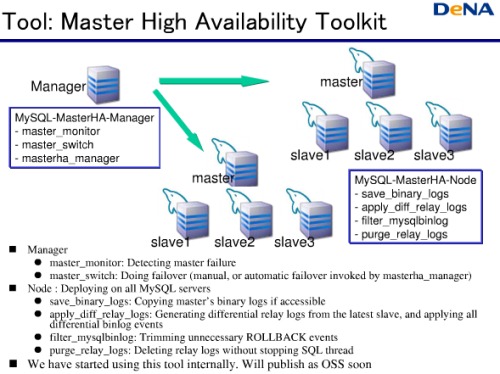
これを実現したツールが「Master High Availability Tool」だ。Masterがダウンしたかどうかを監視するManagerがあり、フェイルオーバーを行う。DeNAはこのツールを社内で使い始めており、いずれオープンソースソフトウェアとして公開するつもりだ。
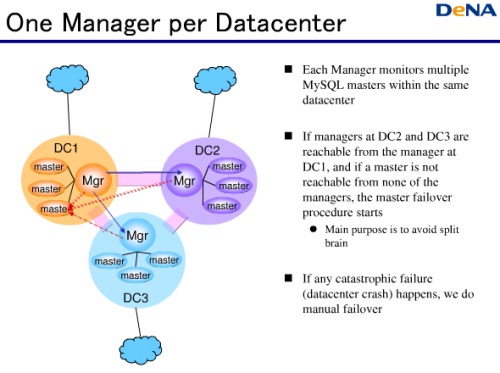
1つのManagerはデータセンター内の複数のMasterを監視する。
実際のケース。Masterでカーネルパニックが起きたとすると、Masterが本当にダウンしているかどうかをチェックするのに10秒、Masterのダウンを確定するため強制的にパワーオフをするのにかかる時間はハードウェアに依存するが4秒~5秒、もしくは5秒から10秒、Masterのリカバリは1秒以内、スレーブのリカバリに1秒以内。

公開されているスライドは以下です。

