
Cassandra入門と、さらに詳しく知るためのリソース集
クラウド時代の新しいデータベースとして、非リレーショナルな構造を持つNoSQLデータベースが話題になっています(NoSQL=Not Only SQL。命名の経緯はこちら)。そのNoSQLの中で、もっとも注目されているデータベースの1つがApacheのCassandraです。
Cassandraは、Facebookで大規模データ処理のために開発され、その後オープンソースとなり、現在ではApache Software Foundationのプロジェクトとして開発されています。
現在、CassandraはFacebookやDiggなどで使われている、もしくは使うことが検討されているとされ、Twitterでも(ツイートデータの格納には使われないようですが、それ以外の用途で)利用されています。
しかしまだCassandraに関する情報はそれほど豊富ではありません。そこでこの記事では、Cassandraについて理解するための情報を集めてみました。
Introduction to Cassandra
この記事を書くきっかけとなったのは、6月17日にパロアルトで行われたSilicon Valley Cloud Computing Groupのイベントで使われた資料「Introduction to Cassandra」がとてもよくできていたためです。
まずはこの資料のポイントを見つつ、Cassandraの概要を把握してみましょう。作成者はRackSpaceのGary Dusbabeck氏。

Cassandraは、分散処理に対応したスケーラブルなデータベース。単一障害点(Single Point of Failer:SPOF)がなく、ノードの追加はシンプル。クラスタのメンテナンスも自動的に行われる。

データをいくつのノードにレプリケーションするかは指定可能。コンシステンシレベル(一貫性のレベル)も複数ある。
- Zero:一貫性の保証なし
- One:(書き込み)1つのノードの書き込みを保証。(読み込み)最初のノードからの読み込みをすぐに返す
- Quorum:(書き込み)レプリケートするノード数の半分+1ノードへの書き込みを保証する。(読み込み)すべてのレプリカの中から最も新しいデータを返す
- All:(書き込み)すべてのレプリカへの書き込みを保証する。(読み込み)すべてのレプリカから読み込んでもっとも新しいデータを返す
(この説明は、後述する「Cassandraのアーキテクチャまとめ」を参考にさせていただきました)。

クラスタ内のノードはリング構造となっており、トークンが割り当てられている。
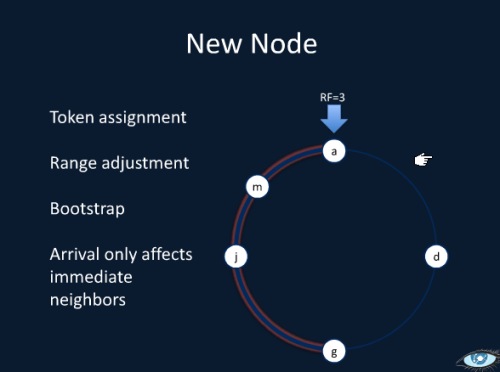
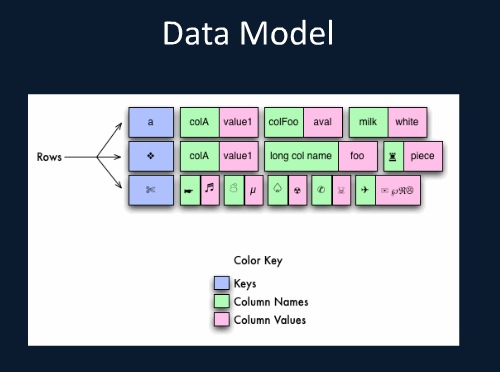
データモデル。キーバリュー型だが、階層的な構造を持つ。

データモデルを図解すると、このようになる。
コンシステンシ(一貫性)レベルを選択できるのも、Cassandraの特徴。その場合、強い一貫性を設定するためにはA(Availability:可用性)とP(Partition Torrerant:分断耐性)を少しだけあきらめる。

「Introduction to Cassandra」は全部で47枚のプレゼンテーションとなっています。ぜひ、直接参照してみてください。
日本語でCassandraを解説したプレゼンテーション
日本語でCassandraを解説したプレゼンテーションとしては、サイバーエージェント 桑野章弘氏の「インフラエンジニアのためのcassandra入門」を、まず紹介しましょう。5月14日に行われた、ハートビーツが主催するインフラエンジニア勉強会でのプレゼンテーションです。Cassandraの概要、仕組みが把握できるようになっています。
同じくサイバーエージェントの名村卓氏による、同社内で5月に行った勉強会のプレゼンテーション資料も、Cassandraのデータモデル、内部の仕組みの解説など、分かりやすいものになっています。
サイバーエージェントは現在、Amebaのバックエンドに現在約300台ほどのMySQLサーバ(ブログ用に120、それ以外に170)を利用しているとのことで、これをNoSQLへ置き換える候補の1つとしてCassandraを検討されているようです。
4月28日のCassandra勉強会の資料として公開されている@yukim氏の「Cassandraのしくみ データの読み書き編」も、データの書き込み時にCassandraがどのように分散したノードへデータを書き込むのか、読み込み時にはコンシステンシレベルに応じてどのような仕組みでデータを読み込むのか、といった動作が詳しく解説されています。
Cassandraのアーキテクチャ、動かし方、公式ドキュメント
「Cassandraのアーキテクチャまとめ」という記事を公開しているのはdann@webdev氏。API、ツール、ストレージの仕組み、パーティショニングなど、Cassandraのアーキテクチャを解説しています。
技術評論社のWebサイト「gihyo.jp」に掲載されている記事「Cassandraのはじめ方─手を動かしてNoSQLを体感しよう」は、実際にCassandraをインストールし、動かしつつその動作や仕組みについて紹介している記事。
この2本の記事は、Webで読めるまとまった日本語の記事としてもっとも充実したものだと思います。
そして、日本語で読めるCassandraの公式ドキュメントといえば、「Cassandra Wiki」。公式ドキュメントの翻訳だけでなく、主要なリソースへのリンクもここに集積されています。
ユーザー向けドキュメントとして、Cassandraの動かし方、アーキテクチャオーバービューなどが読めるほか、高度なセットアップとチューニングについて、開発者向けの内部アーキテクチャの仕組みなど、実際にCassandraの採用を検討するのならば必読のドキュメントといえます。
コンシステンシに関する2つのプレゼンテーション
Cassandraのコンシステンシにフォーカスして解説したプレゼンテーションを2つ、最後に紹介しておきましょう。
もしもほかにもおすすめしたいCassandraの情報があったら教えてください。
関連記事
- TwitterとDiggがNoSQLの「Cassandra」を選ぶ理由
- Twitterが、Cassandraの本採用を断念。「いまは切り替えの時期ではない」
- MySQL+Memcachedの時代は過ぎ、これからはNoSQLなのか、についての議論
- 「NoSQL」は「Not Only SQL」である、と定着するか?
そのほか、NoSQLデータベースの話題については「NoSQL)」タグからどうぞ。
あわせて読みたい
仮想化は、クラウドのインフラとしては不要ではないか?
≪前の記事
グーグル、「政府専用Google Apps」発表。しかし、ロサンゼルス市はセキュリティの懸念でGoogle Appsの導入延期へ

