
グーグルが構築した大規模システムの現実、そしてデザインパターン(4)~デザインパターン編
グーグルが「Evolution and Future Directions of Large-Scale Storage and Computation Systems at Google」(グーグルにおける、大規模ストレージとコンピュテーションの進化と将来の方向性)という講演を、6月に行われたACM(米国計算機学会)主催のクラウドコンピューティングのシンポジウム「ACM Symposium on Cloud Computing 2010」で行っています。
講演の内容を4つの記事(MapReduce編、BigTable編、教訓編、デザインパターン編)で紹介しています。この記事は教訓編の続き、デザインパターン編です。
大規模システムデザインの指針
よりよく使ってもらうためのインフラのデザインと開発方法を考えてみよう。
インフラに対する機能の要望についてさまざまなグループと話すと、多くのリクエストがでてくるだろう。そのうち6つを満たすデザインはできるだろうが、7つ目を満たそうとするととたんに難しくなり、8つを見たそうとするとかえって悪くなってしまう。
だからすべての要求を満たそうとする必要はない。その中から一般的な課題を特定し、それを解決するべきだ。

システムを開発するときに重要なのはスケーラビリティだ。しかし、どこまでもスケールするようなシステムを作る必要はない。
それよりも、スケールが2桁変わるときには、オリジナルデザインをもういちど考え直した方がよい。無限のスケーラビリティについて、最初からそれほど思い悩む必要はない。

大規模分散処理のデザインパターン
ここからはデザインパターンを紹介していこう。
パターン:Sigle Master, 1000s of Workers
分散システムを作るときのパターンの1つ。中心的なマスターを備えている。GFSマスターやBigTable、MapReduceなどで使われているパターンだ。
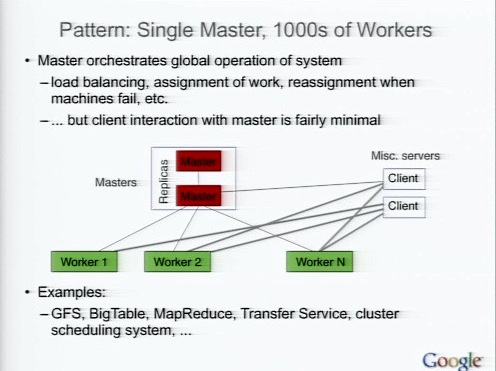
このパターンではしばしばマスターに対してホットスタンバイが使われる。また、大量のデータがクライアントからワーカーのあいだで転送されている。

パターン:Canary Requst
変なリクエストによってクラッシュが引き起こされる可能性があるとき、また、それをどうしても取り除けない場合、Canary Requestsというパターンを使う。
この場合、もし同じ変なリクエストが数千のサーバに送られたら全部のサーバがクラッシュしてしまう。そこで、Canary Requestを使う。これは、最初にCanary Requestを送り、それが成功したら、送信を続けるというもの(訳注:炭鉱のカナリアに由来するのかも)。

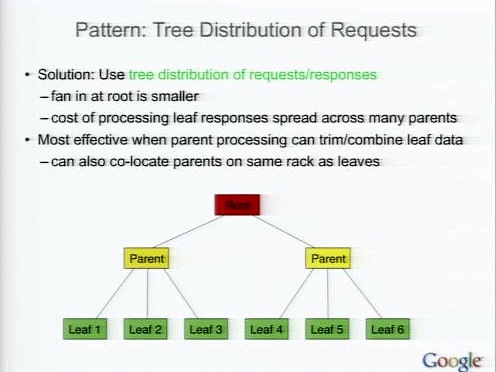
パターン:Tree Distribution of Request
別の大規模処理のパターン。数千台のマシンにリクエストを送る際には送信側のNICやCPUがボトルネックになる。このときには、Tree Distribution of Requestsを使う。
パターン:Multiple Smaller Units per Machine
クラッシュしたときのリカバリ時間を最小にしたいとき、適切な単位でロードバランスしたいときに使える。大きな処理のかたまりではなく、複数の小さな処理ユニットを管理する手法。
それぞれのマシンを1ユニットとして管理すると、リカバリ時のためにマシンまるごとの新しいレプリカを作成するのは大変。それをロードバランスするのはもっと難しい。

そこで、マシンごとの処理を小さなユニットに分ける。
するとユニット数の調整でロードバランスがやりやすくなるし、もしマシンがフェイルしても、それぞれのユニットをN個のマシンが分担してリカバリできるので、すばやくリカバリできる。

パターン:Range Distribution of Data, not Hash
キーバリュー型データストアなどを複数のマシンで分散処理しているとき、さらにマシンを追加する場合。そのマシンにどうデータを割り当てるか。
コンシステントハッシングでは、マシン間で平等にデータを分散できる。しかし、どのマシンにどうデータが分散しているのかをユーザーが知ることは難しい。
Range Distribution of Data, not Hashでは、キーの範囲を複数の連続した範囲に分割し、新しいマシンに割り当てている。BigTableのTabletなどがこの方法を採用している。
この方法はコンシステントハッシングに比べて実装が難しくなるが、ある範囲のキーのデータを同じTabletに入れるなどのコントロールができ、データを取り出すときに少数のマシンにアクセスするだけで済むといったことができる。

パターン:Elastic Systems
負荷に対して柔軟なシステムを作りたいときのパターン。
負荷に対して大きなシステムを作ればリソースのムダだし、負荷を低く見積もってしまえばメルトダウンしてしまうだろう。できれば負荷が小さいときは自動的にシュリンクしてリソースを節約し、ピークの時には自動的に拡張して対応するのが望ましい。
そのためには高負荷に対して柔軟に作るのがよいだろう。われわれは負荷に対して最大2倍程度のキャパシティを計画している。

パターン:One Interface, Multiple Implementations
私たちの検索サービスでは、同時に達成することがほとんど不可能なほど多くの異なる属性を同時に達成しようとしている。
- つねに最新のインデックス
- 大容量
- 高品質な取得
- 大規模
1つの実装だけでこれらをなしとげるのは非常に困難だ。なので、課題を分解し、それぞれを解決するような実装を目指すことになる。

これからのチャレンジ
弱いコンシステンシの上にアプリケーションを構築するというのは課題の1つだ。プログラマはコンシステンシがある状態が分かりやすく、それを好む。
そこで、これは一貫性がある、ない、といったことを考えることのないような、コンシステンシを選択するための一般的なモデルを作り上げるのは新たなチャレンジだ。
また、データのアップデートによる競合状態をどのように解決すればいいか、そのための分かりやすい抽象化レイヤの開発もチャレンジである。

また、MapReduceはある種の大規模分散コンピューテーションの抽象化としてはなかなかよいと思うが、そのほかのものを構築するのはチャレンジとなる。

そしてもっとも困難なチャレンジは、幅広い用途のドキュメントに対応するストレージシステムにある。例えばGoogle Documentでは、あるドキュメントはプライベートだし、あるドキュメントはパブリックに公開されている。こうした幅広いアクセスコントロールのストレージシステムをどう作るか。

いまの時代は非常に面白く、データインテンシブなサービスを構築する時代にきている。データセンターの処理能力を使う大規模なシステムを使うところに、本当のチャンスがあるのではないだろうか。


