
カラムナデータベース(列指向データベース)とデータベースの圧縮機能について、マイケル・ストーンブレイカー氏が語っていること
データベースの高速化技術の1つに、データの圧縮があります。データを圧縮して扱うことでディスクアクセスとI/Oが減少し、データへのアクセス速度が向上するのです。最近のCPUコア数の増大やメモリ単価の下落はデータ圧縮と伸長にかかるオーバーヘッドのコストを相対的に小さくしており、それもこの技術に有利に働いています。
Ingresの開発者であり、InformixのCTOなどデータベースベンダの要職を歴任、データベース研究者として大御所ともいえるマイケル・ストーンブレイカー氏が、データベースにおけるこのデータ圧縮と伸長処理について、ブログ「The Database Column」のエントリ「"Just in Time" Decompression in Analytic Databases」で解説しています。どのような内容を語っているのか、注目してみましょう。
一般的なデータベースにおける圧縮機能
ストーンブレイカー氏によると、従来のデータベースの圧縮機能でディスクに保存されたデータを処理する場合には、まず圧縮したデータを読み込んですぐに伸長し、元データへと戻してからクエリエンジンにデータを渡していました。
このアーキテクチャはクエリエンジンを圧縮データ対応に変更する必要がないため、従来のデータベースエンジンに圧縮機能を追加するのが容易で、それゆえに従来のデータベースの圧縮機能として実装されているそうです。
もちろんこの方法でもデータ圧縮によってディスクアクセスやI/Oを減らすには効果があるわけですが、ストーンブレイカー氏はさらに効率的な方法があるとしています。
カラムナデータベースは、列方向にデータを扱う
ストーンブレイカー氏による続きを読む前に、「カラムナデータベース」(Columnar Database)を紹介しなければなりません。というのも、ストーンブレイカー氏の説明は実はカラムナデータベースを前提にした説明だからです。
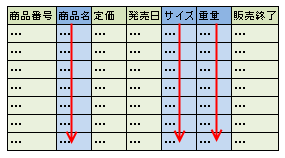 カラムナデータベースは、列方向にデータを扱うのが特徴
カラムナデータベースは、列方向にデータを扱うのが特徴カラムナデータベースは、列方向にデータをまとめて扱うデータベースのことです。ここで紹介しているストーンブレイカー氏の記事ではカラムナデータベースをカラムデータベース(Column Database)と書いています。日本語ではカラム指向データベース、列指向データベースなどと書かれることもあります。
一般的なリレーショナルデータベースでは、データを行単位で扱います。あるデータを参照したい場合には、目的のデータがある行を探して、その行を読み込むことで参照します。
一方、カラムナデータベースは列方向にデータをまとめて扱っています。この特徴は、データウェアハウスのような大規模なデータを分析するOLAP処理などで活きてきます(逆にいえば、OLTP用のカラムナデータベースというのは恐らく存在しません)。
例えば、商品番号、商品名、定価、発売日、サイズ、重量、販売終了フラグといった商品情報を3万件格納した「商品情報テーブル」があったとしましょう。このテーブルから商品名とサイズと重量だけを抜き出す処理を、カラムナデータベースは非常に高速にやってのけます。それはカラムナデータベースの内部では列方向に情報がまとまっていて、それを一気に読み出すため、必要な列以外は読み込まないからです。
これを通常のリレーショナルデータベースで行うとすれば、1行ずつ読み込んで該当列だけを切り出す、という処理の繰り返しになるため、いったんは全データを読み込むことになり、それだけ時間がかかるわけです。
カラムナデータベースについては、Wikipediaの「列指向データベースマネジメントシステム」の説明や、SQLblog.comの「Columnar Databases」が分かりやすく読めると思います。
圧縮効率も高いカラムナデータベース
さて、ストーンブレイカー氏は、新世代のカラムナデータベースでは列の抜き出しだけでなく、データの圧縮にも高い効果を発揮できると説明しています。
 株取引情報のテーブル
株取引情報のテーブル例として、右のような株取引情報のテーブルがあるとしましょう。IBM株が1004回取引され、そのあとSun株が1回取引された、という情報が格納されています。このテーブルを圧縮したら、1列目のシンボルは次のような情報に圧縮されてディスクに保存されるとします。
IBM 1004
Sun 1
これは、シンボルは生データそのままで、その後ろに繰り返しの回数、つまりIBMが1004回続いて、そのあとにSunが1回くる、という情報が付与された状態です。全部で1005件あるはずの情報が、わずか4ワードの情報に圧縮されたことになります。
このテーブルに対して、100ドル以上で取引されたIBMの取引データを検索しましょう。こんなSQL文です。
Select price From Stocks
Where symbol = "IBM" and price > 100
このとき、クエリエンジンは圧縮されてわずか4ワードになった最初の列「IBM 1004 Sun 1」をそのまま読み込みます。すると「IBM」が最初から1004まで続いていることが分かるので、それで検索の1つ目の条件を内部処理できてしまいました。あとはそれに該当する2列目を読んで伸長し、priceを評価するだけです。
このように必要なときだけデータを伸長して処理することをストーンブレイカー氏は「Just-in-Time Decompression」と呼び、データ分析に高い処理性能を発揮するとしています。
また、カラムナデータベースでは圧縮・伸長処理そのものも簡単に済むとストーンブレイカー氏は書いています。先ほどの株取引のデータを例にすると、通常のデータベースではすべての行ごとに圧縮、伸長が行われるため、全データを処理するには1005行分、つまり1005回の圧縮もしくは伸長処理が行われます。
一方、カラムナデータベースは列ごとにデータを処理するため、圧縮、伸長処理は2列分、2回の処理で済みます。それだけCPU処理の負担が小さいというわけです。しかも、同一列にはキャラクタや数値など同一データ型の情報が並んでいます。つまり似たようなデータが並んでいる可能性が高いわけで、それだけ圧縮効率も高くなるといえるでしょう。
情報爆発のカギを握る圧縮と分析
カラムナデータベースは10年前から存在していた技術で、有名な製品にはSybase IQがあります。しかし、この技術が広く注目されだしたのは比較的最近です。ストーンブレイカー氏は自身で2005年にVerticaというカラムナデータベース製品を商用化した会社を創業しており、最近ではSAPの共同創業者であるハッソー・プラットナー氏が、今年5月に行われた「SAP SAPPHIRE 2009」の講演で今後のデータ分析の有力技術としてカラムナデータベースに言及しています。
ストーンブレイカー氏は、データウェアハウス市場ではカラムナデータベースが従来の製品を駆逐すると予言しています(参考:InfoQ: Michael Stonebrakerが語る:主要RDBMSはレガシーテクノロジーである)。
いまは大量のデジタルデータが生成される「データ爆発の時代」とよく言われます。その時代に、大量のデータを効率よく保存できる圧縮技術、そして蓄積した大量のデータを活用するデータ分析の重要性は飛躍的に高まるはずです。
その圧縮と分析の両方で高い能力を発揮する新世代のカラムナデータベースは、比較的地味なDWH/OLAP分野において大きな注目を集める技術となるかもしれません。

