
MapReduceとパラレルRDBでベンチマーク対決、勝者はなんとRDB!
大量のデータを処理する手法として登場したMapReduce。クラウドに対応した分散処理の定番として話題に上ることが増えてきました。
MapReduceは、大量のデータを分割し、分割したデータを分散したノードに投げてノードごとに処理を実行、結果を集約して最終的な答えを求める、といった手法です。
しかしMapReduceが登場する以前から商用レベルで使われていた分散処理手法があります。データを分散したデータベースに格納し処理を行うパラレル・リレーショナルデータベース(パラレルRDB)がその1つです。
パラレルRDBは、データを複数のデータベースに分散して配置、データベースごとに処理を行い、結果を求める手法です。中央に共有メモリを配置するなどの方法で分散したデータベース同士の連携を行うことが一般的です。
ではパラレル・リレーショナルデータベースはMapReduceより遅いのか? 劣るのか? 両者を実際にベンチマークを走らせて比較調査したのが、論文「A Comparison of Approaches to Large-Scale Data Analysis」(PDF)です。
比較の結論は、この論文を紹介してくれたSAPのPaul Hofmann氏のブログ「Parallel DBs faster than Google's MapReduce」から引用しましょう。
The good news is, parallel databases are still 3 to 6 times (on the average) faster than MapReduce. RDBMS is better with regards to speed, query automation, less code to implement per task, etc.
良い知らせとして、パラレルデータベースは平均で3倍から6倍、MapReduceよりも高速だった。パラレルデータベースは、速度、問い合わせの自動化、タスクごとに必要な記述も少ないといった点で優れていた。
一方で、MapReduceのほうが優れていた点もあったようです。
The paper also shows that RDBMS has disadvantages compared to MapReduce like lack of ease of setup and slow when importing a lot of data.
論文では、セットアップの難しさ、そして大量のデータのインポートに時間がかかるといった点が、MapReduceと比較してデータベースの課題として指摘している
ベンチマークはさまざまな処理に対して行われましたが、その中の1つのグラフを論文から引用します。
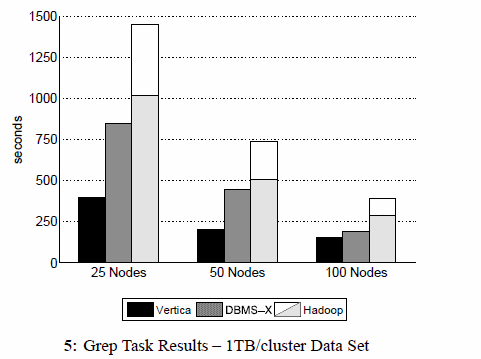
上記のグラフは、1TBのデータからgrep処理で特定の文字列を抜き出す処理にかかった時間を示しています。パラレルRDBMSとして、Verticaと、某ベンダーの商用製品(DBMS-X)が用いられています。また論文によると、パラレル・リレーショナルデータベースではデータ圧縮機能を用いたとのことです(そのほうが約2倍の性能がでるとのこと)。
なぜパラレルRDBの方が速かったのか。論文では、Bツリーのインデックスによる高速化、最新のストレージ機構、圧縮機能、洗練された並列処理などを挙げています。また、「GoogleバージョンのMapReduceはHadoopより高速だと噂されているが、入手はできなかった」とも書いています。
パラレル・リレーショナルデータベースが分散環境でうまく稼働するには、前提条件として各ノードの性能がある程度高く、かつ信頼性が高い場合でしょう。その前提さえ揃えば、業務アプリケーションのプラットフォームとしては、リレーショナルデータベースというのはクラウドのような環境でも十分な競争力を持っている、ということを示しているのではないでしょうか。
またクラウドには実は、ノードごとにそれなりの性能と信頼性を確保しリレーショナルデータベースを走らせるのに向いたクラウドや、低い性能のノードを大量に集めて並列処理を得意としたクラウドなど、それぞれの特徴があるはずです。アプリケーションを実装する場合にはそれにあったアーキテクチャのクラウドを選ぶ、といったことが必要になってくるのでしょう。
関連記事 on Publickey
- 結果整合性(Eventual Consistency)についての分かりやすいプレゼン資料
- マイクロソフトが開発中の新言語「Axum」は並列処理用
- グーグルはリレーショナルデータベースをクラウドに乗せるか
- 続、グーグルはリレーショナルデータベースをクラウドに乗せるか?

