
Hadoopの最新動向を「Hadoop World:NY 2009」の資料から(前編)
Hadoopは、グーグルが大規模分散システムのために用いているMapReduceという技術を、オープンソースとして実現するために開発されたJavaベースのソフトウェアです。開発が始まったのは2005年頃で、当時Yahoo!に所属し現在はClouderaに所属するDoug Cutting氏が中心となって進めてきました。
Hadoopが実現するMapReduce処理とは、簡単にいえば大量のデータを小さく分割して多数のノードに割り当て(Map処理)、各ノードで処理を行ったらそれを集約して結果を出す(Reduce処理)、という分散処理の方法です。数テラバイトにもおよぶ大容量のデータを高速かつ低コストに分散処理する方法として注目を集めています。
ニューヨークでHadoop Worldが開催される
そのHadoopのカンファレンス「Hadoop World:NY 2009」が10月2日にニューヨークで開催されました。主催は、Hadoopの商用ディストリビューションを提供しているClouderaです。
カンファレンスで行われたセッションのプレゼンテーションはほとんどすべて公開されており、Hadoopの最新動向を知る貴重な資料となっています。
この記事では、そのHadoop Worldのプレゼンテーションに全部目を通して興味深い部分を集めたので紹介します。前編の今回は、午前中のゼネラルセッションの資料から。

主催社Clouderaは、まずHadoopの歴史を振り返ります。2004年にHadoopの基となるMapReduceの論文がグーグルから公開。2005年にプロトタイプ、2006年に20ノードで稼働。

その後、2006年にYahoo!が本格的に注力を始め、2007年に200ノードで稼働、2008年には大規模なソート処理のTerasortベンチマークで新記録を達成しています。

Clouderaは、オープンソースコミュニティや企業が公開するHadoop関連のソフトウェアや自社開発のソフトウェアをまとめてパッケージングし、Hadoopのディストリビューションを提供する企業。
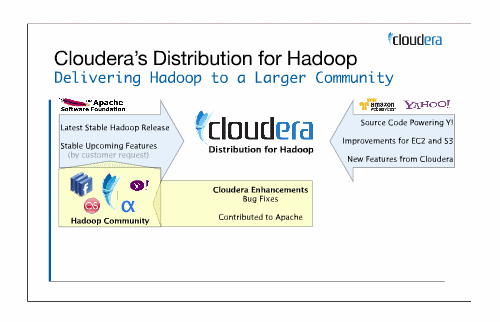
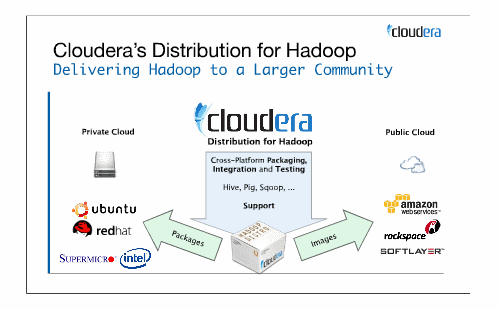
ビジネスモデルは、ディストリビューションパッケージを、UbuntuやRed hatなどのパッケージベンダや、Amazon Web ServicesやRackspaceなどのクラウドベンダへライセンスすることのようです。
Yahoo!はHadoopにおいて最大の貢献とテスト、利用を誇り、今後も積極的な支援を約束しています。

Yahoo!はHadoopを利用することで、調査期間が数カ月から即日に短縮、その結果プロジェクトは調査中心から結果を出すことに注力でき、また操作法も簡単に学べるというメリットを得られている(ただしこれは皮肉になっている可能性あり)。

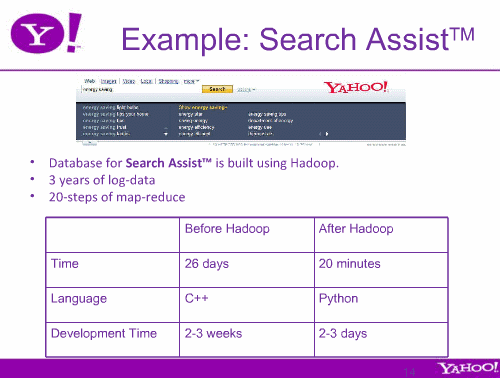
そして以前は26日もかかっていた過去3年分のログデータの分析が、Hadoop導入によってわずか20分になり、分析アプリケーションの開発もC++からPythonに変わり、2~3週間から2~3日に短縮。
Yahoo!が現在開発中のHadoop関連プロジェクトとして、Hadoop本体のほか、PIG、Oozieなどについても説明。

Hadoopの大規模ユーザーの1社であるFacebookは、Hadoopの利点を性能の低いサーバを集めることで非常に高い可用性とスケーラビリティ、管理のしやすさなどとする一方で、Hadoop処理のプログラミングの困難さを挙げています。そして、その解決策として「Hive」があると。

HiveはSQLに似たHiveQLという問い合わせ言語でHadoopの処理を記述することができます。HiveQLを用いると、下記のスライドのように簡潔な文で複雑な処理が記述できるのです。HiveはFacebookが開発し、その後オープンソースとなっています。

Facebookは現在4TBのデータが毎日生成され、135TBのデータを毎日処理しているとのこと。そのために7500以上のHiveによる処理が毎日行われています。

ビデオも一部が公開されています。以下は、ゼネラルセッションの最初に行われた、ClouderaのChristophe Bisciglia氏による「elcome to Hadoop World」、約10分間のビデオです。
Welcome to Hadoop World - Christophe Bisciglia from Cloudera on Vimeo.
ここまでが午前のセッション資料でした。午後のセッション資料の紹介も、興味深い部分を集めて後編で紹介します。

