
Google App Engineにデータストアの障害発生。復帰まで約6時間、原因は現在も不明
クラウド上で誰でもJavaやPythonによるアプリケーションが構築できるプラットフォーム「Google App Engine」。
そのGoogle App Engineで、米国太平洋夏時間の7月2日午前6時半(日本時間7月2日深夜11時半)頃から障害が発生し、約6時間のあいだデータストアへの書き込みなどができなくなり、データストア機能を利用する全アプリケーションが影響を受けました。
この障害は午前8時半頃からApp Engineチームによって対応が行われ、午後12時半過ぎには解決した模様です。App Engineチームは逐次作業状況を報告しましたが、何が原因だったのかについては一切明らかにされていません。
Google App Engine System Statusを見ると、たしかに7月2日にDatastoreとMemcacheに障害が発生しているのが分かります。
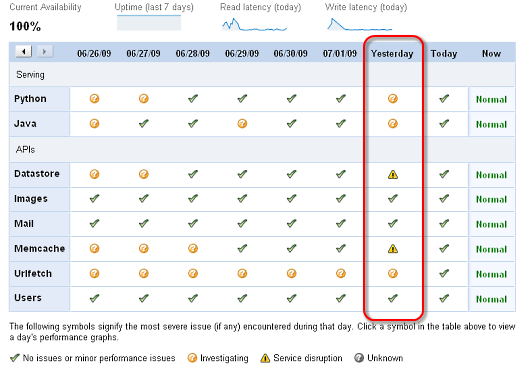 Google App Engine System Statusの画面。DatastoreとMemcacheに警告マークが付いている
Google App Engine System Statusの画面。DatastoreとMemcacheに警告マークが付いている7月2日のDatastoreのGet機能についてのグラフを見ても、午前6時半ころから12時過ぎくらいまで、大きなレイテンシが発生していることもよく分かります。
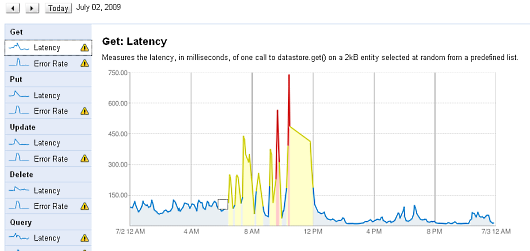 DatastoreのGetのレイテンシ。6時半頃から12時頃まで急激に上昇し、グラフの色が変わっている
DatastoreのGetのレイテンシ。6時半頃から12時頃まで急激に上昇し、グラフの色が変わっている対策チームからの原因報告はないまま
Googleグループの「Google App Engine Downtime Notify 」には、このときに対策を行ったApp Engineチームからの状況報告が「Elevated Datastore latency, error-rates, serving errors - Google App Engine Downtime Notify」というスレッドで逐次行われていました。
どのような報告だったのか、目を通してみましょう。日時は米国太平洋時間の7月2日です。
AM 8:39 現在、データストアのレイテンシとエラー発生率が上昇しています。この問題は午前6時半頃から発生していた模様です。データストアにアクセスする全アプリケーションが影響をうけています。私たちのチームは調査を開始しており、なるべく早く復帰報告ができるようにします。
AM 8:45 現在、予告なくメンテナンスモードへ移行しており、アプリケーションのデプロイ、データストアへの書き込み、メムキャッシュへの書き込みなどが一時的に無効になっています。プログラム中の例外ハンドラでこれらの例外をキャッチするようにしておいてください。
AM 10:02 データストアへのリードオンリーの状態を継続中です。また、データストアのリードのレイテンシやエラー発生率の上昇も変わっていません。メムキャッシュへの書き込みは、リードオンリーの状況を緩和するために再開しています。エンジニアリングチームがこの問題の原因を突き止めるために調査を続けており、分かり次第また報告します。
AM 11:45 根本的な原因となったものは排除しましたが、別の問題が発生しています。データストアの読み込みはすべてのアクセスに対して失敗している状況です。ダイナミックなリクエストも静的ファイルの読み込みも、エラー発生率が上昇しています。この状況を修正するために懸命に作業中です。
PM 0:07 データストアの読み込みは、現在正常に稼働しています! ダイナミックなリクエストと静的なファイル読み込みも正常に復帰し、レイテンシも正常域となりました。ただし、データストアへの書き込みは無効のままです。できるだけ早く書き込み可能へと戻せるように作業中です。
PM 0:35 データストアへの書き込みが可能になり、正常動作しています! Google App Engineのすべての状況が正常へと戻りました。
Google App Engineで明らかになった3つの大きな不安
今回の障害の発生と対応を見ると、3つの大きな不安要素が表出したように思えます。
1つは、Google App Engine全体に影響する障害がデータストアで発生したことです。Google App Engineのデータストアは大規模かつ高度な分散と冗長化が行われ、たとえ一部に障害が発生したとしても全体としては問題なく動き続けるアーキテクチャを備えていたはずです。ある部分の異常が全体に影響するようなSingle Point of Failerが存在するような現象など考えにくい、と誰もが思っていたはずです。少なくとも僕はそう思っていました。
ところが今回、すべてのアプリケーションが影響を受ける障害が発生しました。一体データストアに何が起きたのでしょうか? この障害でデータの整合性は(そもそも保証されていないとしても)どの程度失われたのでしょうか? 何かをトリガーとしてデータストア全体を使用不能に陥れる弱点があったという事実により、データストアの信頼性にやや疑問符が付いたのではないかと思います。
その信頼を取り返すには、今回の原因をしっかりと調査して明らかにすることが不可欠です。しかし、上記の報告に見るように、復帰作業中の報告には原因について一切触れられていませんでした。以前のエントリで取り上げた、障害発生時のアマゾンからの報告とは対照的です。できるだけ速やかに、今回の原因と対策をグーグルは明らかにするべきでしょう。
そして3つめは、今回の障害の対応が、発生から2時間たってようやく始まったと思われる点です。上記のエラー発生率のグラフを見ても分かるように、午前6時半頃からエラー発生率が上昇し、グラフの色が黄色に変わっています。明らかな警告です。
ところがApp Engineチームが第一報とともに対策を開始したのはそこから2時間後の午前8時半過ぎです。これが顧客を抱えるホスティングセンターだったら、顧客から電話でたたき起こされて「なにをぐずぐずしているんだ!」と罵声を浴びせられても全くおかしくありません。こうした対応についても、今後の対策をグーグルは明らかにするべきだと思います。
クラウドでは、万が一問題が発生しても顧客がクラウドのデータセンターの誰かをたたき起こしてどなりつけることができない体制になっています。いまのところ指をくわえて復帰を待つことしかできません。
それゆえにクラウドは低価格で高機能を提供する仕組みを備えているわけですが、しかし企業がクラウドを使用するには何らかの方法でそこを乗り越えて一定以上の信頼性や対応体制を確保する必要があります。「障害で止まった分は返金します」では明らかに不足です。今回のグーグルの障害の発生と対応は、そうした信頼を確立するための課題がまだまだ多いことを示しているように思えます。
関連記事 on Publickey
- アマゾンのクラウドが落雷で一部停止、そのとき何が起きたか?
- FBIが令状によりデータセンターを押収、巻き添えの顧客は大損害
- 障害の原因の7割は運用・保守中に起こる。総務省がまとめたITの信頼性とセキュリティへの取り組み
- ついに無制限に解放されたGoogle App Engine/Java。RoRやPHP、もちろんJavaも試そう
- [速報]Google AppEngineがついにJavaサポート開始!
参考記事 on the Web
- Google App Engine - Google Code
- Google App Engine System Status
- Elevated Datastore latency, error-rates, serving errors - Google App Engine Downtime Notify | Google Groups
- Google App Engine、約6時間ダウン - ITmedia エンタープライズ
- 「Google App Engine」でサービス障害--4時間ほど利用不可能に:ニュース - CNET Japan
- Google App Engine Stalled Out For About 6 Hours Today

