
グーグルが取り組む次世代Bigtable、全世界規模でサーバ1000万台を自動化して構築する「Spanner」プロジェクト
米国の計算機学会であるACM(Association for Computing Machinery)が開催した、大規模分散システムのワークショップ「LADIS 2009(Large Scale Distributed Systems and Middleware)」の2日目、10月11日のキーノートスピーチで、グーグルが現在取り組んでいる「Spanner」プロジェクトの中味が明らかになりました。
キーノートスピーチを行ったのは、グーグルのSystems Infrastructure Groupに所属するフェローのJeff Dean氏。同氏は、現在グーグルが「Spanner」というプロジェクトに取り組んでおり、それは「Storage & computation system that spans all our datacenters」(グーグルの全データセンターにまたがるストレージとコンピュテーションのシステム)になるとのことです。
公開されているプレゼンテーション資料から、ポイントとなるシートを引用します。

グーグルが現在取り組んでいるプロジェクト「Spanner」は、グーグルの全データセンターにまたがるストレージとコンピュテーションのシステムで、単一のグローバルな名前空間を持ち、Bigtableに似ているが、階層型のディレクトリときめの細かい粒度でレプリケーションが行われる、とあります。
さらに、データセンター間での強い一貫性と弱い一貫性をサポートし、データの強い一貫性(strong consistency)に関してはPaxosによるtabletのレプリケーションによって実現される予定。この部分は以前の記事「データセンターが「落ちる」ことを想定したグーグルのアーキテクチャ」も参照してみてください。
そして、データのアロケーションなどは自動的に行われることになるそうです。
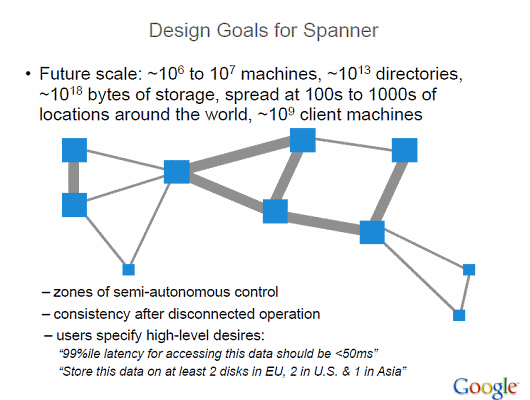
「Spanner」のゴールとして想定されているのは、100万台から1000万台のサーバを全世界で運用すること。サーバは数百から数千の地域に分散して世界中に置かれ、10億台のクライアントをサポートすることになるとのこと。
そして99%の範囲のレイテンシが50ミリ秒以下、保存されるデータは少なくとも2つを欧州、2つを米国、1つをアジアに保存するとあります。
ちなみに、2008年度の日本国内でのサーバ/ワークステーションの出荷実績は約45万台。約3億ユーザーをサポートするFacebookの現時点でのサーバが約3万台ですから、100万台から1000万台のサーバという数字がいかに莫大な数なのかお分かりいただけると思います。
マイクロソフトのWindows AzureやAmazon EC2などに関わり、大規模分散システムの分野で著名なJames Hamilton氏は、このJeff Dean氏のプレゼンテーションをブログで取り上げ、「Working on next generation Big Table system called Spanner」(グーグルはSpannerと呼ばれる次世代のBigtableに取り組んでいる)と書いています。
また、国立情報学研究所の佐藤一郎氏はTwitterで次のようにつぶやいています(その1、その2)。
管理の多くを自動化したうえで、その運用をどこかにアウトソースするのではないかとの読みです。たしかにこう指摘されるとありそうですね。
以前の記事「グーグルの最新のデータセンターは非常識なほど進化している」では、「月を追いかけるデータセンター」というコンセプトがあると紹介しましたが、Spannerはまさにそれを地でいく構想ということになりそうです。

