
Amazonクラウドが大規模分散処理の機能を強化。SQLライクな検索ができるHiveを搭載へ
クラウドのサービスを提供するAmazon Web Servicesは10月2日、新機能として「Apache Hive」をサポートするとブログで明らかにしました。
Hiveは、もともとFacebookが開発した、MapReduceによる大規模分散処理のオープンソースフレームワーク「Hadoop」と組み合わせて利用するフロントエンドアプリケーションです。Hive QLというSQLに似た言語でHadoop上のデータを操作できるため、柔軟でアドホックな問い合わせを簡単に実現できるようになり、Hadoopを基盤としたデータウェアハウス的な処理がいままでより容易に構築できるようになります。
すでにAmazonはHadoopを、ウィザードのような簡単な操作で実現するサービスを提供しています。Hiveも以下の画面のようにウィザードから操作できるようになっています。
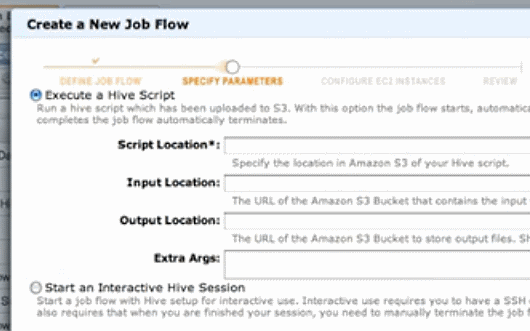 Hadoopのウィザードから、Hiveのスクリプトを実行するか、対話的に命令を入力するかなどが選べる(Amazonのチュートリアルビデオから)
Hadoopのウィザードから、Hiveのスクリプトを実行するか、対話的に命令を入力するかなどが選べる(Amazonのチュートリアルビデオから)また、統合開発環境のNetBeansからHadoop処理の開発、デバッグ、展開などが可能になる「Karmasphere Studio For Hadoop」のサポートも開始したと発表しています。
AmazonクラウドはPaaSへ向かうのか?
Amazonが提供するAmazon Web Servicesは、そもそもサーバとストレージなどの提供を基本とするIaaS(Infrastracture as a Service)です。しかし、Hadoop、Hiveの提供によってクラウドをデータウェアハウスとして利用しやすくするなど徐々にPaaS(Platform as a Service)の色彩を濃くしはじめています。と同時に、Amazon Private Cloudの提供によって企業による利用を打ち出してもいます。
PaaSのレイヤは、グーグルのGoogle App Engine、マイクロソフトのWindows Azure、そしてセールスフォース・ドットコムのForce.comなどがサービスを展開する激戦区。AmazonはIaaSの強みを活かしつつ、このレイヤでの戦いを挑むつもりなのでしょうか?

