
知られざる「マルチテナントアーキテクチャ」(3)~スキーマとメタデータの謎
セールスフォースが採用しているマルチテナントアーキテクチャでは、すべてのユーザーが同一データベース、同一スキーマを共有しています。
では、個別に入力項目を増やすようなスキーマの変更を伴うアプリケーションのカスタマイズや、新たなテーブルを作成してそこに独自データを保存するようなアプリケーションの新規作成はできないのか? といえば、そんなことはなく、セールスフォースが提供するプラットフォームの上で、自由に項目の追加や新しいテーブルの作成が可能です。
全ユーザーでスキーマを共有しながら、しかし個別のカスタマイズを許容する。この一見矛盾する要件を、セールスフォースはどのように実現しているのでしょうか?
(本エントリは「知られざる『マルチテナントアーキテクチャ』(2)~スケーラビリティのカギは組織ID」からの続きです。)
公開されているスキーマを見てみる
ユーザーがスキーマを変更したり、新規テーブルを作ったりできるのならば、セールスフォースのデータベースは何百何千というユーザーのテーブルであふれているか、というとそうではありません。
セールスフォースは、内部で利用しているデータベースのスキーマを公開しており、下記にみるようにそれはわずか10個程度のテーブルで構成されています。そしてこのスキーマにこそ、矛盾する要件をうまく実現するための答えが隠されています。JP Multi Tenant Architecture:Force.comのマルチテナント型アーキテクチャ - developer.force.comで公開されいてるPDF文書から、スキーマの部分を転載します。
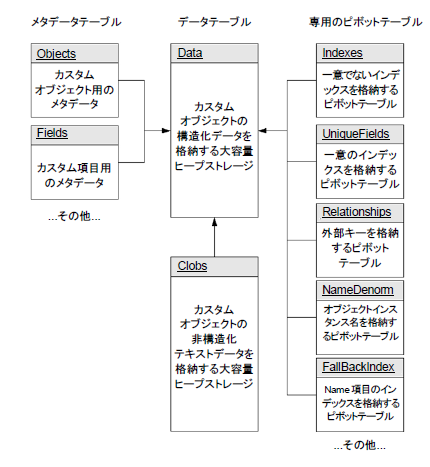 セールスフォースが採用しているデータベーススキーマ
セールスフォースが採用しているデータベーススキーマこのスキーマの最も重要な部分は、中央にある「データテーブル」と左側にある「メタデータテーブル」との関係です。ここだけを抜き出した図を、再びPDF文書から転載します。
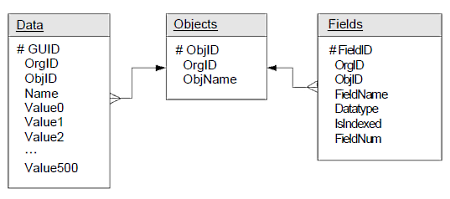 Dataテーブルと、メタデータテーブルとされるObjectsテーブル、Fieldsテーブルとの関係
Dataテーブルと、メタデータテーブルとされるObjectsテーブル、Fieldsテーブルとの関係なぜこういう構造になっているのでしょうか。ひとことで説明すると、セールスフォースのアプリケーションで扱われるすべての数字や文字のデータはDataテーブルに保存されるためです。まずはData、Objects、Fieldsの3つのテーブルの役割についてみていきましょう。
掟破りのスキーマ
セールスフォースのアプリケーションで扱われるすべての数字や文字のデータは、Dataテーブルに保存される。このことがセールスフォースのデータベーススキーマの核心です。
Dataテーブルはどんなデータでも受け入れられるよう、次のようなスキーマになっています。恐らく、データベースに詳しい方がみたらびっくりするようなスキーマです。
 Dataテーブルのおもな列とデータ型。Value0からValue500まで501列の可変長文字列型が特徴
Dataテーブルのおもな列とデータ型。Value0からValue500まで501列の可変長文字列型が特徴あらかじめ可変長文字列の列が501列用意されていて、ここにデータを格納していくのです。
例えば、以下のような顧客情報と商品情報をセールスフォースのデータベースに格納するとしましょう。
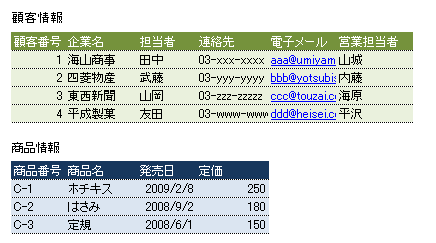
すべてのデータはDataテーブルに格納されます。どのように格納されるのかといえば、これらはDataテーブルに次のように格納されます(行の順番は順不同だと思ってください。)。
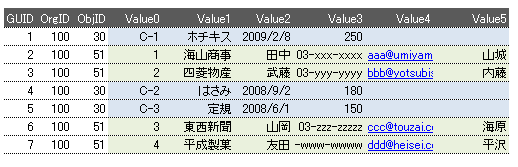
つまり、Dataテーブルは何でも受け入れてしまう魔法のテーブルとして使われているのです。
上のDataテーブルの例をよく見てみましょう。すべての行には、GUIDとして固有のシリアル番号が付いています。そしてOrgIDとは「組織ID」のこと。ユーザー企業ごとに発行される番号です。ObjIDは、データがどこに所属しているか行ごとに示しており、この例では、顧客情報は51番、商品情報は30番の番号が付いています。そしてValue0~Value500までの列に、データの実体が格納されています。
これを先のメタデータテーブルとの関係を表したスキーマと合わせてみてください。「Objects」テーブルのOrgID(組織ID)およびObjIDとジョインすれば、自動的にユーザー企業ごとのテーブル群が作成され、さらに「Fields」テーブルとジョインすることで、作成されるテーブルの列名、データ型、どの列がインデックス化されているか、などを知ることができます。
つまり、Dataテーブル、Objectsテーブル、Fieldsテーブルの3つがあれば、カスタマイズされたテーブルも、新規テーブルも、全部分解して格納でき、また元通りに組み立て直すことができるのです。
インデックスとリレーションの定義
ただし、ユーザーのテーブルを分解して格納できるだけでは使い勝手が悪すぎます。高速に検索するためのインデックスや、テーブル同士のジョインの機能などがほしいところ。
データを高速に検索するためには、データにインデックスを付けます。ところが、DataテーブルはすべてのValue列が可変長文字列であり、しかもそこには日付や数値や文字など本来はいろいろな型を持つデータが格納されています。ここにインデックスを設定するのは現実的ではありません。
そこで、Dataテーブルに対してIndexesというテーブルが用意されています。
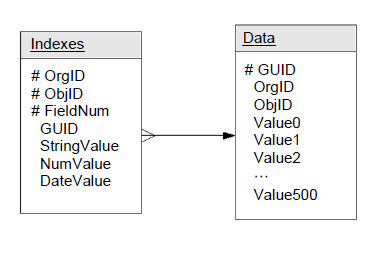 Dataテーブルの中に格納されたデータに対して、Indexesテーブルにコピーをしてインデックスを付けることができる
Dataテーブルの中に格納されたデータに対して、Indexesテーブルにコピーをしてインデックスを付けることができるユーザーは自分で設定したテーブルから列を1つだけ選び、インデックスを設定することができます。ObjIDが選んだテーブルを表し、インデックスを設定する列はデータ型によってStringValueかNumValueかDateValueのいずれかの列にコピーされます。この3つの列にはOracleによってインデックスが設定されており、高速に検索することができるのです。
同様に、リレーションのためにはRelationshipsというテーブルが用意されており、Dataテーブルに分解して格納された複数のテーブル間のリレーションを定義することができます。
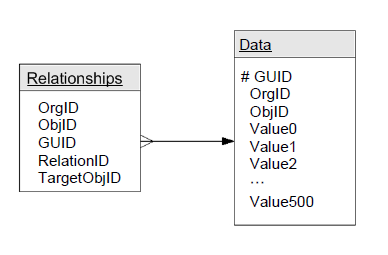 テーブル同士のリレーションも、Relationshipsで定義できる(この図は引用元の図を修正しています)
テーブル同士のリレーションも、Relationshipsで定義できる(この図は引用元の図を修正しています)そしてもう1つ大事なポイントは、前回のエントリ「知られざる「マルチテナントアーキテクチャ」(2)~スケーラビリティのカギは組織ID」で説明したように、これらのデータが組織IDでパーティショニングされていることです。つまり、ユーザー企業ごとにデータが物理的にまとめられているため、Dataテーブルがいかに巨大になろうとも(Oracle11gの仕様では最大8エクサバイト)、あるユーザーがSalesforceのデータベースにアクセスするときには、自社用のパーティションにアクセスするだけで済むのです。
このほかにもさまざまな仕掛けがこのスキーマに込められています。詳しくは記事末の参考記事などを参照してください。
生データとメタデータに分解して保存するためのスキーマ
つまり、セールスフォースが採用し、全ユーザーで共有しているデータベースのスキーマとは、ユーザーが扱うデータベースのテーブルを、データと、その構造という「メタデータ」に分解して格納する目的で設計されたものといえます。
これが、ユーザーごとにデータベースのカスタマイズを許容しながら、しかしセールスフォース内部のデータベースとスキーマは同一のものをすべてのユーザーが共有する、ということを実現している仕組みなのです。
最初からマルチテナントアーキテクチャで設計したからできた
MapReduceもキーバリュー型データベースも使わずにスケールし、すべてのユーザーが同一データベース、同一スキーマを共有しつつ、カスタマイズも許容する。「マルチテナントアーキテクチャ」についてセールスフォースの実装例を3回に渡って説明してきました。
こうしてまとめてみると、セールスフォースはSaasに最適化したシステムを前提に全く新規にシステムを設計・構築したからこそ、こうした大胆なアーキテクチャを採用できたのだ、ということがよく分かります。
既存のアプリケーションをもしもここで紹介したようなマルチテナントのアーキテクチャに書き換えようとすると、SQLなどデータアクセス部分は全部書き換え、オンプレミスでは必要なかった組織IDごとのセキュリティモデルは作り込みが必要になるなど、新規にアプリケーションを開発するのとそれほど変わらないか、それ以上に苦労することは間違いないでしょう。オラクルやSAPといったオンプレミスのアプリケーションを基にSaaSを展開しようとしているベンダが、マルチテナントアーキテクチャを採用できないでいる理由もこの辺にあるのではないでしょうか。
いま日本でもSaaSへ参入する企業は増えており、今後はSaaSも品質と価格で競争が始まることでしょう。そのとき、スケーラブルかつ効率的なアーキテクチャに基づいているかどうかは、品質やコスト構造に大きく影響するはずです。マルチテナントアーキテクチャはSaaS時代の新しいアーキテクチャとして、今後注目度が増していくことでしょう。
ここで説明しているセールスフォースのマルチテナントアーキテクチャについては、同社が公開している資料などに基づいて僕が理解したことをまとめたものです。できるだけ正確な説明を心がけていますが、推測に基づく部分があること、同社の公式見解とは異なる部分などがあるかもしれないことをお断りしておきます。参照した情報は以下をご覧ください。
関連記事 on Publickey
- 知られざる「マルチテナントアーキテクチャ」(1)~SaaSはみんな同じではない?
- 知られざる「マルチテナントアーキテクチャ」(2)~スケーラビリティのカギは組織ID
- 知られざる「マルチテナントアーキテクチャ」(3)~スキーマとメタデータの謎
- セールスフォースがサーバをサンからPCへ。コスト4分の1、性能2倍に - Blog on Publickey
- Salesforce CRMレビュー - SaaSの代名詞ともいえるアプリケーションの営業支援機能を試す
- パッケージソフトからSaaSへと主戦場が変わるCRM市場

