
知られざる「マルチテナントアーキテクチャ」(2)~スケーラビリティのカギは組織ID
セールスフォースが採用しているマルチテナントアーキテクチャでは、すべてのユーザーが同一データベース、同一スキーマを共有しています。これによってインフラの共有が容易になり、非常に効率的な運用と低コストを実現しています。
(本エントリは「知られざる『マルチテナントアーキテクチャ』(1)~SaaSはみんな同じではない?」からの続きです。)
しかし、それだけではスケーラビリティやアベイラビリティを実現することはできません。それらの実現には別の技術が併用されています。それはOracleのパーティショニング機能とパラレル機能による分散処理です。
パーティショニング機能の話をする前に、セールスフォースが採用しているデータベースの特徴を見てみましょう。
すべてのデータに振られる組織ID
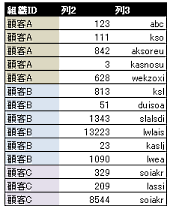 格納されているデータには必ず組織IDが振られている(イメージ)
格納されているデータには必ず組織IDが振られている(イメージ)セールスフォースはすべてのユーザーが1つのデータベースを共有するマルチテナントアーキテクチャを採用しています。ということは、ユーザーが扱うデータはすべて1つのデータベースに格納されるのです。
しかし当然ながら、ある企業が他の企業のデータを参照してしまうことがないように、厳重なセキュリティを施さなければなりません。そこで、セールスフォースのデータベースに格納されるデータには、必ず「組織ID」が付けられます。スキーマとしてテーブルに組織IDの列が設けられているのです。この組織IDを超えてデータが参照されないようにシステムは設計されています。
そしてこの組織IDが、分散処理によるスケーラビリティのカギにもなっています。
Oracleのパーティショニング機能とパラレル機能
セールスフォースがDBMSとしてOracleを利用しているのは周知の事実です。Oracleは高度なパーティショニング機能とパラレル機能を備えており、セールスフォースはその機能を活用して巨大なスケーラビリティを実現しています。
パーティショニング機能
パーティショニングは、1つのデータベースを複数に分割する機能です。例えば、売上管理のデータベースであれば、売上テーブルを月ごとにパーティションとして分割しておきます。すると、特定の月の売上げを集計したいときには特定のパーティションだけを集計すればよくなるため、テーブル全体をアクセスして特定の月のデータだけを抜き出したうえで集計するより高速になります。
さらに、パーティションごとに別のハードディスクに配置するといった物理設計をしておけば、年間の売上げを集計するのに別々のハードディスクへアクセスが分散するおかげで集計が高速になる、といったメリットがあります。また、データベースに障害が発生した場合でも、障害のあるパーティションだけの局所的なものに抑えることができます。
パラレル機能
さらに、パーティションに分割したデータベースごとにDBMSのプロセス(インスタンス)を割り当てることで、巨大なデータベースを複数のプロセスで分散処理させることができます。例えば、巨大なデータベースを10台のサーバで分散して稼働させる、といったことが可能です。
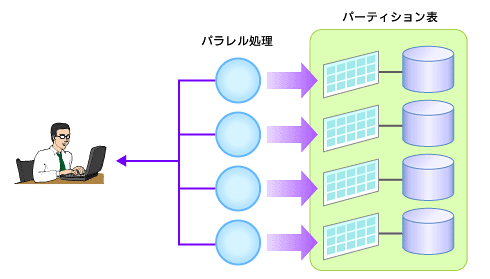 パーティションにプロセスを割り当てることでパラレル処理が可能になる。「パーティショニングとパラレル処理は最高の相性 - @IT」から引用
パーティションにプロセスを割り当てることでパラレル処理が可能になる。「パーティショニングとパラレル処理は最高の相性 - @IT」から引用組織IDによってパーティショニングを行い、分散処理を実現
セールスフォースがリレーショナルデータベースを用いてスケーラビリティを実現する仕組みは、この組織ID、パーティショニング機能、パラレル機能を組み合わせたものです。
まず、組織IDごとにデータベースをパーティショニング機能で分割します。これによって利用者(組織IDで示されるユーザー企業)ごとにデータアクセスの高速化が期待でき、また巨大なデータベースを分割して管理できるようになり、障害も局所的なものに抑えることができるようになります。
そして分割したパーティションに対してインスタンスを割り当てることで、パラレル機能による分散処理を実現して、スケーラビリティを実現していると考えられます。
同社のホワイトペーパーに、その手がかりとなる記述があります。JP Multi Tenant Architecture:Force.comのマルチテナント型アーキテクチャ - developer.force.comから引用します。
Force.comのデータ、メタデータ、ピボットテーブルの構造は、その基盤となるデータベースインデックスも含め、すべてがデータベースのパーティショニングメカニズムによってテナント別の組織IDに基づいて物理的に分離されています。
この仕組みによって、ユーザー企業が増えた場合でも、データが増えた場合でも、パーティションを増やし、そのパーティションを処理するインスタンスを追加することでスケーラブルな対応をすることができるようになっています。しかも管理するデータベースはどれだけ巨大になろうとも1つですから、比較的シンプルなシステムを維持できるわけです。
セールスフォースでは、コアとなるデータベースのインスタンスは現在のところ約50だと明らかにしています(参考)。1つのインスタンスは複数のパーティションを担当しているのでしょう。このインスタンスごとのスケーラビリティとアベイラビリティを実現するため、おそらくはハードウェアレベルでも高性能で信頼性の高いサン・マイクロシステムズのサーバを使って50インスタンスの分散運用を行っているのではないでしょうか。
こうしたパラレル処理を実現したリレーショナルデータベースが、クラウドの定番テクノロジーとして話題のMapReduceと同等以上に高度な分散処理を実現できていることを確かめた論文があることは以前のエントリ「MapReduceとパラレルRDBでベンチマーク対決、勝者はなんとRDB!」で紹介しました。
パラレルデータベースは平均で3倍から6倍、MapReduceよりも高速だった。パラレルデータベースは、速度、問い合わせの自動化、タスクごとに必要な記述も少ないといった点で優れていた。
リレーショナルデータベースでも、ハードウェアとソフトウェアの設計によって高度なスケーラビリティが実現できることを、セールスフォースは実証しています。
最後の疑問。カスタマイズへの対応、スキーマの柔軟性はどうする?
さて。マルチテナントアーキテクチャでは、すべての利用者が同一のデータベースとスキーマを共有しています。
しかし、業務システムを導入する際にカスタマイズが全く発生しない、ということはありえません。「このシステムにあの情報も追加で入れたい」「この情報と連携できるようにしたい」といった要求が発生するのは必至であり、また現実にセールスフォースは企業ごとのカスタマイズの対応は当然のこと、独自データを格納するアプリケーションの開発まで可能なプラットフォームを提供しています。
なぜ同一スキーマのままでこうした柔軟性を実現できているのでしょうか? それについては次回に説明します。
ここで説明しているセールスフォースのマルチテナントアーキテクチャについては、同社が公開している資料などに基づいて僕が理解したことをまとめたものです。できるだけ正確な説明を心がけていますが、推測に基づく部分があること、同社の公式見解とは異なる部分などがあるかもしれないことをお断りしておきます。参照した情報は以下をご覧ください。
(知られざる「マルチテナントアーキテクチャ」(3)~スキーマとメタデータの謎へつづく)
関連記事 on Publickey
- 知られざる「マルチテナントアーキテクチャ」(1)~SaaSはみんな同じではない?
- 知られざる「マルチテナントアーキテクチャ」(2)~スケーラビリティのカギは組織ID
- 知られざる「マルチテナントアーキテクチャ」(3)~スキーマとメタデータの謎
- セールスフォースがサーバをサンからPCへ。コスト4分の1、性能2倍に - Blog on Publickey

