
自然言語からSQLクエリを機械学習で生成、業務データベースが言葉で検索できるように。セールスフォース・ドットコムがAIの研究成果を公開
セールスフォース・ドットコムの人工知能研究部門であるSalesforce Researchは、自然言語による質問とデータベーススキーマの情報を基に、質問に対応するSQLクエリを機械学習で生成する研究成果を公開しました。
これによってビジネスパーソンがSQL言語を学ぶことなく、業務データベースから必要な情報を自然言語で検索できることが期待できます。
自然言語を解析してSQLクエリを生成
下記の図は、公開された研究成果の概要を示したものです。
図の左上「How many engine types did Val Musetti use?」が自然言語の問いとなり、「Entrant / Constructor / Chassis / Engine / No / Driver」がデータベースのテーブルスキーマとなります。
このふたつの情報を機械学習済みのソフトウェア「Seq2SQL」にインプットすると、適切なSQLクエリが生成されることが示されています。
ちなみに問いの日本語訳は「Val Musettiは何種類のエンジンを使ったのか?」で、Val Musetti氏は有名なスタントマンとしてさまざまなレーシングカーを操ったそうです。
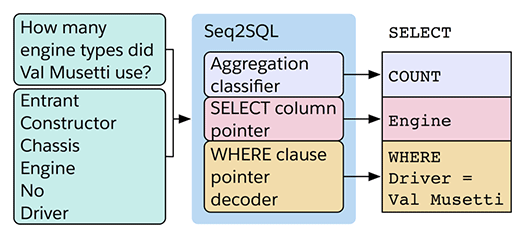
「Seq2SQL」は、自然言語の問いから、SQLクエリを構成する次の3つの要素を生成すると説明されています。
1つ目は「Aggregation classifier」。問いの答えに対応する集約を行います。この例では、問いの「How many」に対応して、SELECT Countで数を数えるための「COUNT」が生成されます。
2つ目が「column pointer」。SELECT節に対応し、問いの答えを得るべき列を示します。ここでは問いの「How many engine types」から、エンジンの種類を問われていると判断し、列名「Engine」が生成されます。
3つ目がWhere節に書くべき条件です。問いに「Val Musetti氏は」とあることから、ここでは「driver = Val Musetti」が生成されます。
Salesforce Researchは、機械学習を用いることでより正確なSQLクエリが生成できるようになったとしています。
また、このように自然言語をもとにデータベースへの問い合わせができるようになることで、ユーザーはテーブルスキーマなどを知らなくてもさまざまな業務データベースから自然言語で情報を取得できるようになり、より効果的な営業やマーケティング施策が実現しやすくなることが期待されるとしています。
あわせて読みたい
VMwareとPivotal、KubernetesなどをホストするCloud Native Computing Foundationに参加。Kubernetesに追い風
≪前の記事
アップルとアクセンチュアが提携、アクセンチュアの専門部隊とアップルのエンジニアが協力。iOSアプリを業務システムやIoTプラットフォームと連係強化へ

