
クラウドの音声認識APIで、ライターにとって実用的な「文字起こしサービス」は作れるのか?
文章を書く仕事をしている多くのライターが苦手にしている作業のひとつに、かつて「テープ起こし」と呼ばれ、いまは「文字起こし」と呼ばれるものがあります。
これは取材やインタビューを行う際に録音したものを聞き返して、逐一正確に文字にしていく作業なのですが、とにかく単調で集中力が必要です。僕はこの作業が苦手ですぐ集中力が切れてしまうので、たとえば60分のインタビューの文字起こしをしようとすると、だいたいその3倍以上の時間がかかることを覚悟しなければなりません。
ある日、たまたま後輩と一緒にインタビューの仕事をしているときに、後輩が僕にこう言いました「新野さん、もし文字起こしを自動でやってくれるソフトがあったら僕は100万円出してもいいですよ」と。
まったく同感でした。この先ずっと、必要な時にいつでも機械がその場で自動的に文字起こしをしてくれるのなら、100万円ぐらい払ってもいい(僕もたまにクラウドワークスなどで人力の文字起こしを頼んだりもしていますけれど、依頼するというプロセスも面倒くさかったりします……)。
その日、僕は決意をしました。いまやSiriやAlexaなどでクラウドの音声認識APIが実用になりつつある時代です。だったら、クラウドのAPIを使って文字起こしサービスが作れるのではないか、作ってみようではないかと。
音声認識はある程度実用になっているが、まだ文字起こしには足りない
 新野がふだん使っているICレコーダー。胸ポケットなどにクリップでとめられるので、イスしかなくて机にICレコーダーを置けない講演などの録音でも扱いやすい
新野がふだん使っているICレコーダー。胸ポケットなどにクリップでとめられるので、イスしかなくて机にICレコーダーを置けない講演などの録音でも扱いやすいみなさんご存知のように、すでに音声認識の機能はある程度実用的に使われています。
それはSiriやAlexaだけではありません。例えばGoogle Docsには音声入力の機能があります。これを利用して、マイクに向かって明瞭にきちんと文節ごとに間を開けて日本語を話すと、それなりにきちんと音声での日本語入力が可能です。
こうした良好な音声条件下であれば、Google Docs以外にもそこそこ使える音声認識アプリはすでに市場に複数あるでしょう。
しかしライターが取材やインタビューで行う録音データは、そこまで音声の条件がよくありません。一般的にライターはボイスレコーダーやICレコーダーと呼ばれる機械を机の上などにおいて録音を行うので、口元でマイクが明瞭に音をとらえる、いわゆるオンマイクの良好な音声ではありません。
それにPCでメモを取るキーボードの打鍵音や周囲のざわめきのようなバックグラウンドノイズも乗るでしょう。
もちろんインタビューの会話は、ときに早口だったり、相手と自分の声が重なったりと、明瞭で文節ごとに区切られたきちんとしたものでもありません。しかしライター向けの文字起こし機能としては、こうした状況下の音声でも認識してもらいたいところです。
そしてもうひとつ、Google Docsもそうですが、現在の音声認識機能のほとんどはマイク入力を前提としています。しかしライターのための文字起こし機能を考えるならば、60分などの長時間の音声データをそのまま読み込んで認識してくれる機能も絶対に必要でしょう(僕は以前、マイク入力にICレコーダーの再生をつないでGoogle Docsで音声認識できないかと試したことがありましたが、いろんな面でうまく認識してくれませんでした)。
ハンズラボさんと協力してPoCを実施
ということで、クラウドの音声認識APIが「まとまった音声データを取り込んで認識してくれるか」「オフマイクの音声で、ノイズが入って、早口でも認識してくれるか」などを検証するアプリケーションを開発することにしました。
とはいえ僕にはクラウドのAPIをすらすら組み合わせて開発する能力も、時間的余裕もありません。
そこでProof of Concept(PoC:概念検証)のためのサンプルアプリ開発に協力してくれるパートナーを探したところ、幸いにも、クラウド関連の開発で有名な「ハンズラボ」さんが興味をもってくれたので、一緒に開発を進めることにしました。
まずは今回の開発の背景とともPoCの要件を文章として簡単にまとめ、にハンズラボさんのオフィスへ伺ってプレゼンをしました。そして、お願いした通りのサンプルアプリケーションが数週間ほどで出来上がってきたではありませんか。さすがプロです。
これがその画面です。まだPoCなので一般公開はしていません。
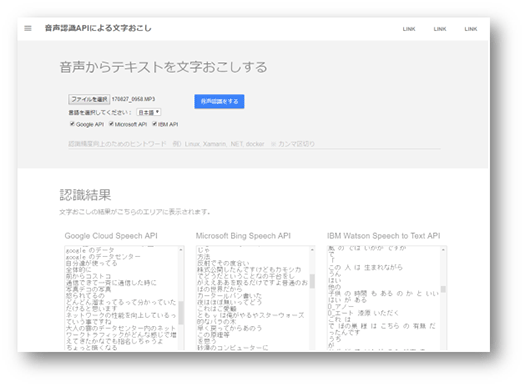
Webページから音声データをアップロードし、「音声認識を開始する」ボタンを押下すると、Google、Azure、Watsonの音声認識APIにそれぞれ音声データを取り込ませます。
すると、いちばん左のテキストフィールドにはGoogle Cloud Speech APIの認識結果が、真ん中のテキストフィールドにはMicrosoft Bing Speech APIの認識結果が、いちばん左のテキストフィールドにはIBM Watson Speech to Text APIの認識結果が順次出力されていくようになっています。
現時点ではどのAPIがいちばん優秀なのかわからなかったので、3種類全部を同時に試して比較することにしたのです。
現時点での評価は……
出来上がったPoC用のアプリケーションに、これまで僕が行ってきた取材の録音データをいくつか読み込んでみました。また、ハンズラボさんにもデータを渡し、評価もしてもらいました。
結果は、まだ業務に投入できるほどの品質には達していないようでした。
この評価は現時点で定量的なものではなく、すべて出力されたテキストを見たうえでの定性的な評価ではありますが、実用的でないことは一目で分かります。上記の画面でも出力結果がうっすらと読み取れるかも知れません。
当初はもう少し実用的なものになるかな、と考えていたのですが、少なくとも僕の録音データでは、人間が行う文字起こしの品質とは比較できないどころが、文章としてもかなり怪しい文字列が出力される、というレベルでした。
おもな原因として、音声の明瞭さの不足と認識APIの能力不足のふたつが想像できますが、特に前者の要因が大きいのかもしれないと考えています。これはつまり、音声認識APIはまだ、人間ほどノイズのなかでの人間の声を聞き分けられていない、と言えるのかもしれません。
ベンダ別のAPIの評価
ちなみにAPIの評価をベンダ別に見てみると、GoogleのAPIがもっとも優秀で、音声のコンディションがよいところでは、ある程度きちんとした文字列を出力する印象でしたが、それでも全体としては実用的とはいいにくいところです。
ハンズラボで開発を担当していただいたエンジニアの一人である山本氏は、それぞれのAPIの特徴について次のように評してくれました。
- Google / Cloud Speech API:「えー」、「あのー」などの不要な語句が取り除かれている
- Microsoft / Bing Speech API:発言した内容はそのまま表示されている印象
- IBM / Speech to Text API:「えー」、「あのー」などの不要な語句が「D_エー」や「D_アノー」などに変換される
また山本氏によると、各社APIごとに独自に存在する機能(パラメーター)や利用可能な音声データの長さや形式に制限があり、思ったように処理や結果が返ってこない場合があったため、対応として各社APIで利用する音声データを下記の形式に統一し、リクエストするようにしているとのことでした。
- 音声データの形式:WAV, PCM, 16 bit, 1 channel, 16,000 Hz
- 音声データの長さ:1度のリクエストは最大10秒程度
もう少し評価範囲を広げていく予定
とはいえここまでの評価は、あくまで僕の録音データだけを用いたものなので、ほかのライターの録音機材や録音状態ではまた異なる評価になるかもしれません。いずれにせよ、もっとたくさん評価したうえで、今後のこの文字起こしサービスの開発の方向性を(もちろん実用性への希望がなく、あきらめることも含めて)考えなくてはと考えています。
そこで次の段階として、僕の知り合いのライター数人から十数人程度に声をかけてこのPoCのサービスを試してもらい、より多くの評価結果を集めるつもりです。たぶんアンケートみたいな形で集計できるようにするつもりです。
そのなかで、より認識率の高い録音テクニックや録音機材をさぐることができるかもしれませんし、音声認識APIに渡す前のノイズフィルタリングの技術を試行錯誤することができるかもしれません。あるいは音声認識APIの能力がさらに向上し、不明瞭な音声を聞き分けてくれるようになるかもしれません。
というわけで、僕の知り合いのライターの方はもしかしたら僕から協力のお願いがいくかもしれませんので、その際にはぜひご検討くださいませ。
そしてまた進捗を報告すべきタイミングが来たら、こんな感じの記事でみなさんに報告するつもりです。たぶん興味をお持ちのライターはたくさんいるのだろうと思いますしね。
続報:ライターが集まって実際のインタビューの録音データで評価してみました。
あわせて読みたい
オープンソースイニシアチブにマイクロソフトが加盟、プレミアムスポンサーとして。あのハロウィーン文書から19年
≪前の記事
[速報]Windows、Linux、Dockerに対応した「SQL Server 2017」正式版リリース。Microsoft Ignite 2017

