
Linux OSからFPGAを透過的に利用する構想。文字列処理をCPUからFPGAへオフロードで10倍速になった研究結果をミラクル・リナックスが発表
プロセッサ内部のロジックをソフトウェアで動的に書き換えることができるFPGAは、アプリケーションごとにロジックを最適化できるため、x86などの汎用プロセッサよりも高速かつ効率的なアプリケーションの実行が可能になると注目されています。
特に、今年の1月にインテルがFPGA大手のアルテラを買収し、XeonにFPGAを統合するという将来計画を発表してから、FPGAへの注目度はさらに高まっています。
しかしいまのところ、FPGAをアプリケーションから利用するには、ロジックを開発ツールなどを用いてFPGAに書き込み、それをデバイスドライバを経由してフレームワークなどを通じて利用するというものになります。
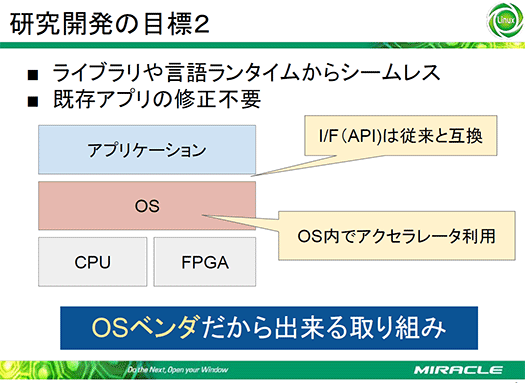
これをもっと簡単にしようという構想を明らかにしたのがミラクル・リナックスです。同社はFPGAの恩恵を容易に享受できるOSの提供を目指し、従来と互換性を保ったOSのAPIからシームレスにFPGAが利用できる環境を実現しようとしています。
これによりアプリケーションの書き換えをしなくともFPGAの恩恵を受けることができると考えられますが、API互換のままFPGAの利用でどれだけ処理を効率化できるかが課題です。
同社はそのための研究として、既存の標準ライブラリで行われている文字列処理と同じ処理をFPGAにオフロードすることで、10倍の高速化を実現したという結果を発表しました。具体的には文字列を特定の記号ごとに分割するC言語のStrtok関数に相当する機能をFPGAで実行し、ベンチマークを行いました。
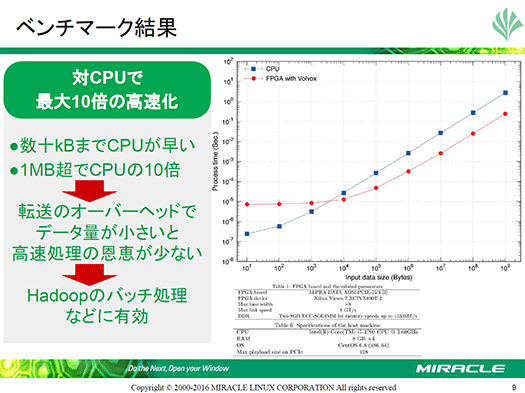
グラフの横軸が入力データ量、縦軸が処理に掛かった時間を示し、赤い線がFPGA、青い線がCPUの処理を示しています。
グラフを見ると、データ量が1KB(103Bytes)まではCPUでの処理時間の方が短くなっていますが、データ量を10KBを超えるところからはFPGAの方が処理時間が短くなり、最大でCPUよりも約10倍速となっていることがわかります。
これはデータ量が小さい場合にはFPGAにデータを転送する際にかかる時間がオーバーヘッドとなっているためCPUの方が処理時間が短い一方、データ量が増えてくることでかかる処理時間に対してオーバーヘッドが無視できるほどの割合になり、FPGAによるカスタムロジックの有効性が顕著になってくるためです。
ただし今回のベンチマークではFPGAがPCIeを通じて接続されているため「FPGAのロジックを32にして並列度を上げても、PCIeの速度によって制限されている面がある。CPUとFPGAがワンチップになればオーバーヘッドがもっと小さくなり、性能がもっと向上するだろう」(ミラクル・リナックス 技術本部 開発部 シニアエキスパート 大和一洋氏)とのことで、将来はさらにオーバーヘッドが小さくなり、性能向上が期待できるとしています。
あわせて読みたい
DockerとCanonicalが提携。Ubuntuで商用サポート版のDocker Engineを提供
≪前の記事
[速報]AWS LambdaでC#のサポートを発表。オープンソースの.NET Coreを採用。AWS re:Invent 2016

