
NTTデータとPostgreSQLが挑んだ総力戦。PostgreSQLを極限まで使い切ったその先に見たものとは?(後編) NTTデータオープンソースDAY2015
PostgreSQLを大規模なミッションクリティカルなシステムの中で使うには、どのようなノウハウが求められるのか。オープンソースの利用に積極的なNTTデータがその事例を、1月26日に開催されたイベント「NTTデータオープンソースDAY 2015」で紹介しています。講演内容をダイジェストにしました。
(本記事は「NTTデータとPostgreSQLが挑んだ総力戦。PostgreSQLを極限まで使い切ったその先に見たものとは?(前編)」の続きです)
実行計画をチェックするためにPostgreSQLを騙す。
3つ目は実行計画のチェックです。PostgreSQLのSQL文はコストベースで実行されますので、統計情報を見て、テーブルをスキャンする方法、結合する方法などを選択するのですが、その選択が実行性能にとって重要です。そこで実行計画をチェックしました。
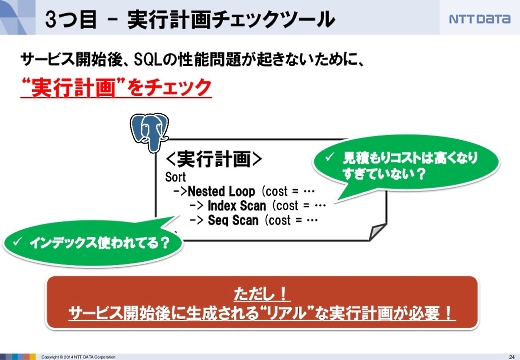
ただし、本番環境でしかもサービス開始後のリアルな計画を開発環境で再現してチェックしなければ意味がありません。
本来であれば本番環境と似たサンプルデータを用意して実行計画を作らせたかったのですが、なかなかデータを用意できなかったので、統計情報を操作してPostgreSQLをだます形でそれを実現しました。
ただし統計情報はテーブルの中身によって更新されるため、一回騙す仕組みだけでなく騙し続ける仕組みも必要でした。そこで統計情報カスタマイズ機能を作りました。
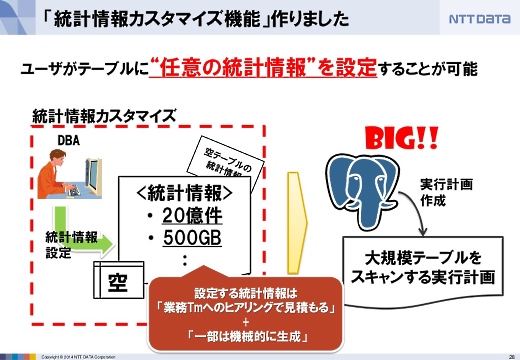
さらに、騙し続ける仕組みとして統計情報固定化機能も作りました。本来の統計情報を使わずに、つねに騙す方へ固定化できます。
これで9割くらいはSQL文の問題が解決できるようになりました。しかしまだ最小限で最大限の効果が求められました。そこで、HINT句を使ってSQLチューニングをしました。

そして5つ目の最後の手段としてSQL文の書き換えも行いました。
この5つの関門を設定したことで、大量のSQL文の性能を守ることができました。

オープンソースの良さでトラブルを解決
最後のトピックは、リスクとの対峙です。
新しい仕組みを取り入れるのは有益な点もありますがリスクもあります。例えば、最終テストに差しかかってからPostgreSQLがセグメンテーションフォルトで落ちました。これはかなり重大な問題で、しかも再現が難しいものでした。
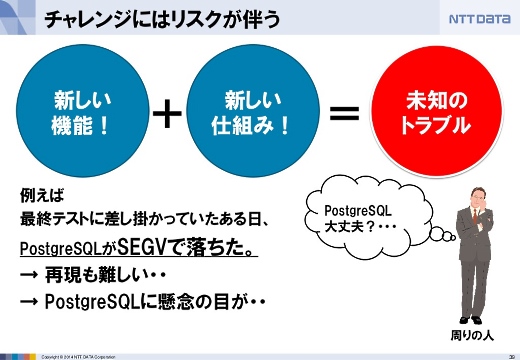
そうすると、そもそもPostgreSQLを選んだのがよかったのか、などとPostgreSQL自体が懸念されるようになることもありました。
しかしそこはオープンソースの良さとして、コアダンプとソースコードがありますから、原因がPostgreSQL本体なのか、外部モジュールなのか、切り分けができます。解析した結果、外部モジュールが原因だということがわかり、原因を追及してパッチを書いて根本解決しました。

必要以上のリスクを負わない、ということは大事ですが、エンジニアの力でリスクを低減するということも大事だと思います。
PostgreSQLでしかできない領域へ
今回のシステム構築で感じたこと。
PostgreSQLは豊富な拡張機能で機能を引き出せるので、今回のようなシビアな要件ではそれらを活用してポテンシャルを引き出すのは、1つの手段としてありかなと。
また、問題はどうしても発生します。その問題の補足手段と対策を持っておくことが大事ではないかと思います。
そして最後は製品だけでなく、その裏にいるエンジニアやサポートの力。オープンソースはホワイトボックスであることを生かして、コアダンプとソースコードで解決できる、ということも感じました。

これまでPostgreSQLは商用データベースの代替としてコスト削減のために使われてきたことが多かったと思います。しかしいまPostgreSQLは例えばJSON型が使えるなど、従来のRDBMSの使い方を超えた領域に挑んでいます。
JSON型を使うことでスキーマレスで自由に列を拡張できたり、PostgreSQLをハブにしてOracleやMySQLを連携するといったこともできるようになります。PostgreSQLは、PostgreSQLにしかできない領域に進んでいると言えるのではないでしょうか。
公開されたスライド。
あわせて読みたい
MacOS/LinuxでC#やVisual Basicを実行可能にする.NETランタイム「.NET CoreCLR」。早くもGitHubで公開
≪前の記事
NTTデータとPostgreSQLが挑んだ総力戦。PostgreSQLを極限まで使い切ったその先に見たものとは?(前編) NTTデータオープンソースDAY2015

