
クックパッドのデプロイとオートスケール、1日10回デプロイする大規模サイトの裏側(後編)。JAWS DAYS 2014
大規模なオンラインサービスを支えるためのオートスケールと、サービスをすばやく進化させていくための迅速なデプロイ。クックパッドはこの2つをクラウド技術の組み合わせによって両立させています。
同社のインフラ責任者である成田氏がその仕組みやルールを、Amazonクラウドのユーザーコミュニティ主催のイベントJAWS DAY 2014で解説しました。
(本記事は「クックパッドのデプロイとオートスケール(前編)。JAWS DAYS 2014」の続きです)
オートスケールはAmazon Auto Scalingを使わないと判断
今日の本題であるオートスケールの話をしたいと思います。
オートスケールとは一般に、トラフィックが増えたらサーバを増やしましょうね、という作業を自動化するものですね。
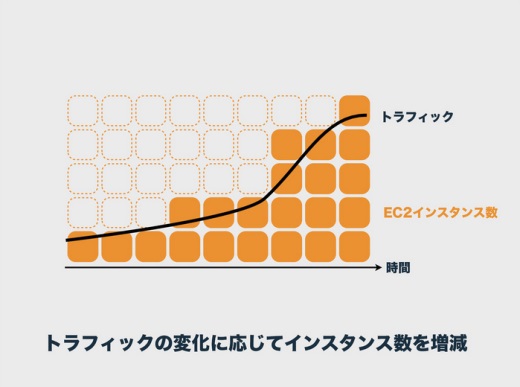
なぜオートスケールをするのかというと、最大のトラフィックに合わせてインスタンスを立てっぱなしにすると、この点線のサーバも含めて9時間で45インスタンス分の課金になりますが、トラフィックに応じてオートスケールさせれば22インスタンス分で済むから、という考え方です。
オートスケールを容易にするためにAmazon Auto Scalingがあります。これはCloudWatchのトリガーでインスタンスを立てたり落としたりするものです。
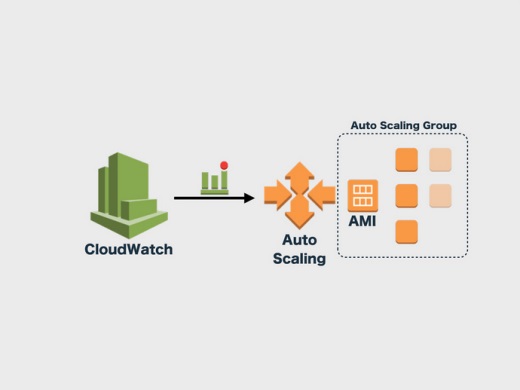
ただ、僕らはAmazon Auto Scalingを使わずにオートスケールをやっています。理由の1つ目は、CloudWatchが1分ごとにしかリクエストカウントの値がとれないので、オートスケールの反応が1分遅れるためです。
それからもう1つは勝手にGraceful Terminate問題と呼んでいるのですが、いまAmazon Auto Scalingがサーバをトラフィックに応じて10台から8台に減らしたとすると、これにELBが微妙に追随していなくて、落としたはずの2台にもトラフィックを振ってエラーになるんです。
がんばればこれを安全な挙動にできるのですが、僕が触った感じではずいぶんプログラミングが必要です。
そしてこれが最大の問題なのですが、最初に説明したとおり、僕らは1日に10回デプロイしていて、これがAmazon Auto Scalingとは相性が悪いんです。
例えば、いまアプリのバージョン1(v1)がサーバに入っています。図の上にあるのはAmazon Machine Image(AMI)です。ここで開発者がv2をデプロイしている最中にAmazon Auto Scalingが動き出すと、まだAMIはv1のままなので、デプロイされたv2とAmazon Auto Scalingで展開されたv1が混在してしまうという問題があります。
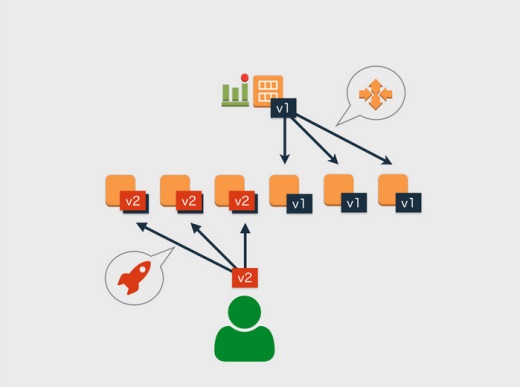
このためデプロイ作業とAmazon Auto Scalingの排他制御をしなくてはいけないのですが、Amazon Auto Scalingではインスタンスの増減をしようとするときにそれをフックして中断させるのは至難の業で、すごく難しい。
そこでAmazon Auto Scalingは使わないでオートスケールを実装する方が良さそうだと判断しました。

オートスケールとデプロイを鍵で排他制御
僕らの実装は、さきほどのimonがapacheのアクセスログをパースして数秒単位でrequest per sec(rps)を取っているので、これでアクセスが多いか少ないかを判断して行っています。
オートスケールが実行されるているあいだはデプロイを禁止したいんですね。そこでimonが「鍵」を持っていて、オートスケールの実行中はimonから鍵をもらってオートスケールします。このとき開発者は鍵をもっていないのでデプロイが禁止され、このときにデプロイコマンドを実行してもエラーになります。
開発者がデプロイしたいときにはimonから鍵をもらって、v2をデプロイしてAMIもv2になってから鍵を返す。すると次からはv2でオートスケールされますと。
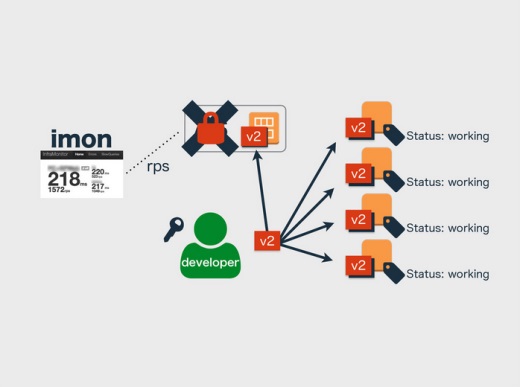
こうしてオートスケールと開発者のデプロイの排他制御をするのが僕らの実装です。
オートスケールのある暮らし
デプロイを1日に10回くらいやっていると、開発者はデプロイ中心の生活になります。そこにオートスケールの割り込みが入るとデプロイのサイクルが阻害されるのではないか、という心配があります。
オートスケールをしている最中はimonに表示されて分かるようになっていて、デプロイ中も同じように表示されます。これって、餅つきで杵を持ち上げているときにちょいちょいと餅をこねる人みたいに、あれがオートスケールとデプロイの関係だと思っていて、お互いに絶妙な間合いで排他制御しているみたいな。
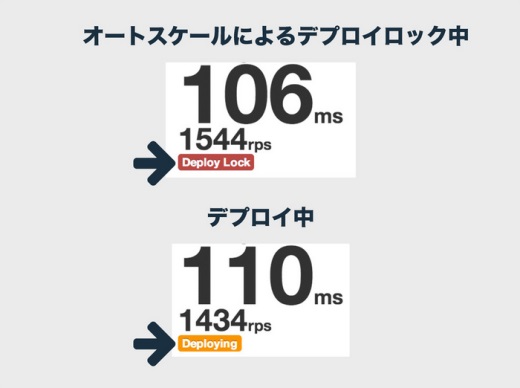
そこで、これらをどう工夫して運用しているのかを最後にお話ししたいと思います。
僕が気にしているのがオートスケールによるロックの回数、デプロイを止める回数をどれだけ減らすかです。デプロイをロックしているとユーザーに価値を届ける機会やバグを直す機会を減らしてしまうので、できるだけ少ない方がいいわけです。
そこで業務時間中のロックができるだけ少なくなるようにチューニングしています。それはいちどに増減する台数の調整です。
コストを気にするのならば少ない台数でこまめに増減する方がいいのですが、あえて台数を増やしてロックの回数を減らしています。うまくいくと業務中はロックが2回で済みます。
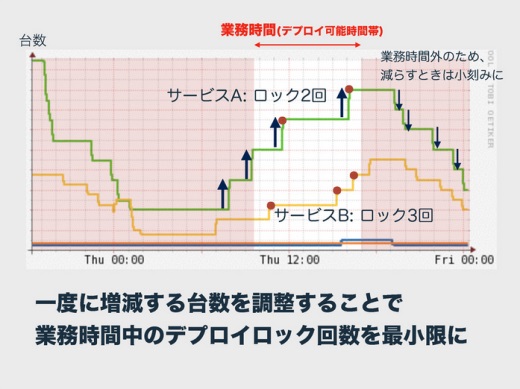
業務時間外は小刻みに動かしてデプロイをロックしてもいい、クックパッドの特徴として業務時間外はアクセスが減っていく傾向にあるので、オートスケールでサーバを減らすときのパラメータは小刻みにする、ということをしています。
それからオートスケールはサーバを落とすものなので、万が一ここにバグがあると壊滅的なことになります。暴走だけは怖いので、必ずこまめにテストを通すようにしています。
オートスケールとImmutable Infrastructure
オートスケールでは、朝たったサーバが夕方には落ちてるということもあって、サーバは使い捨てです。でもこれには問題もあって、サーバに入って調べたいこともときどきあります。そうやって調べているあいだにオートスケールでサーバが落とされてしまうと不便なので、絶対に落とさないサーバというのも設けています。
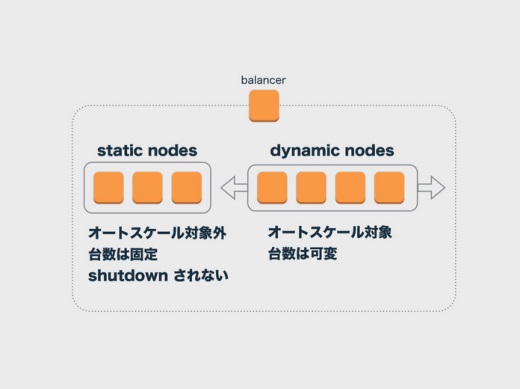
そういうスタティックなノードと、オートスケールの対象としてダイナミックなノードが1つのロードバランサーの下にぶらさがるようになっていて、スタティックな方のサーバはシャットダウンされずにずっと動いています。
ダイナミックな方のサーバは、AMIから生成されたImmutableなもの、つまりいちども状態が変更されることなく動いています。このように、オートスケールにするとImmutableにせざるを得ないところがでてくるんです。
Immutable Infrastrucuteって理想論や未来の話のように扱われたりしますが、現実の話です。オートスケールでちょっと工夫するとすぐにImmutable Infrastructureになってしまう。みなさんも来たるべきときが来ると思うので、心してオートスケールを組んでみてください。
関連記事
あわせて読みたい
複数クラウドのインスタンスの状況や課金状況を把握、予測できるダッシュボード「RightScale Cloud Analytics」がベータ公開
≪前の記事
クックパッドのデプロイとオートスケール、1日10回デプロイする大規模サイトの裏側(前編)。JAWS DAYS 2014

